E2E_auto_driving
传统自动驾驶系统与端到端:
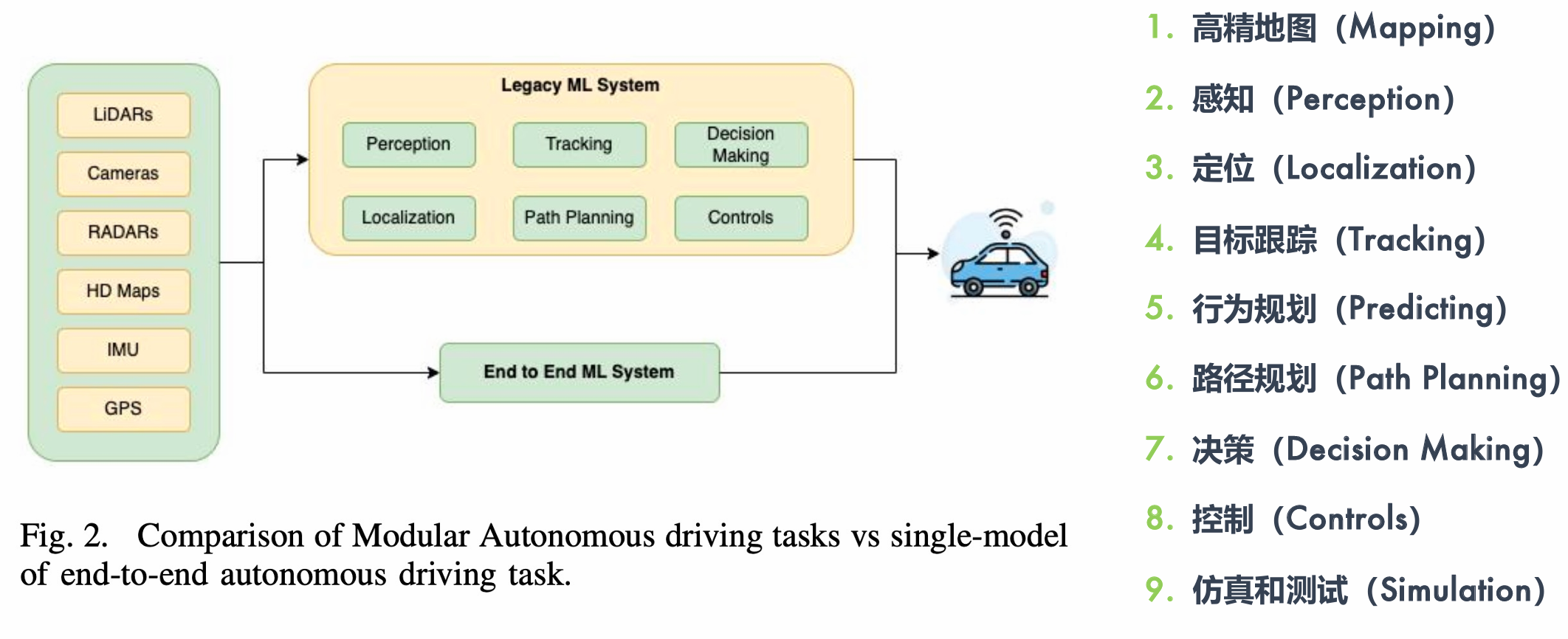
传统自动驾驶系统:级联式
- 每个模型都要专门进行训练、优化、迭代,随着模型不断进化,参数量提高和数据量增加,所需研发投入大,研发成本高。
- 模块化架构可以看做级联流水线,模型的输入参数,是前级模型的输出结果。如果前级模型输 出结果有误差,会影响下一级模型输出,导致累计级联误差,最终影响系统性能

端到端方式
通过一个模型实现流程中多个模型的功能。该模型可以接收传感器数据(图像、激光雷达等)作为输入,并输出车辆控制指令(如方向盘角度、刹车和加速等)。通过大规模数据集和训练 算法,模型能够学习从感知到控制的完整驾驶策略
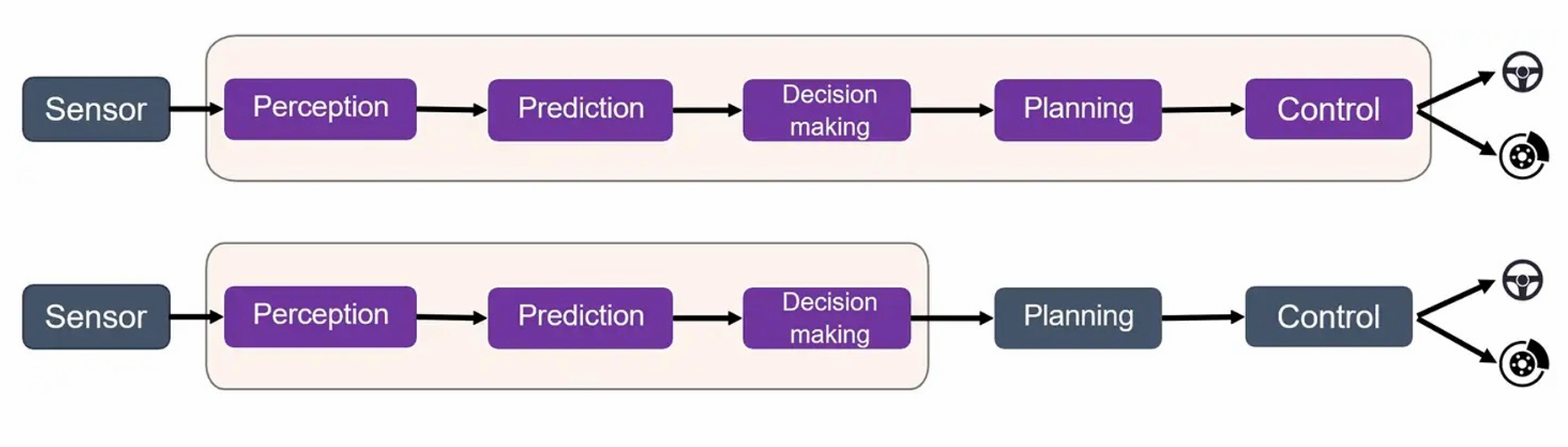
目前的端到端并不是完全的端到端,而是上面两种方式:
- 一种是真正意义上的端到端,把感知,预测,决策,规划和执行全部统一到一个模块,但是目前主流的解决方案中并没有模型能做到这种意义上的端到端
- 另外一种是一部分的端到端,是将感知,预测,决策统一,只在一部分模块中进行端到端
级联方案与端到端方案对比
| 级联 | 端到端 | |
|---|---|---|
| 算法类型 | 模型算法+规则判断 | 模型算法+数据驱动 |
| 安全性 | 高 | 未知 |
| 可解释性 | 高 | 低 |
| 响应时延 | 中 | 高 |
| 算法难度 | 中 | 高 |
| 训练难度 | 中 | 高 |
| 评测手段 | 相同 | 相同 |
| 累计误差 | 高 | 无 |
研究方式
端到端自动驾驶学术研究主要分为两类
- 闭环方式:模拟器(如CARLA)中进行验证,规划下一步指令可以被真实执行,即算法直接控制
- 闭环指的是数据上的闭环:数据采集 -> 数据标注 -> 模型训练 -> 模型部署 -> 数据采集
- 为什么需要数据上的闭环,因为自动驾驶数据为长尾分布的数据
- 开环方式:在已经采集现实数据上进行端到端研究(主要指模仿学习,IL),因为只通过采集到的数据只能让网络如何预测,因此只能开环。开环方式不能真正看到自动驾驶预测指令执行后效果。由于不能得到反馈,开环测评受限。常用指标是:
- L2 距离:计算预测轨迹vs真实轨迹之间L2距离,来判断预测轨迹的精度;
- Collision Rate:通过计算预测轨迹和其他物体发生碰撞概率,来评价预测轨迹的安全性
闭环是算法控车,开环是算法不控车。用输出规划轨迹和人实际开出轨迹的差距来评分,数学本质是预测误差 predict error