SDE 统一视角
在之前的文章中,我们介绍了 score-based model 的基本概念,包括其如何对数据分布进行建模、如何从建模的分布中采样,以及通过对分布施加扰动来提高建模精度的方法。本文将重点探讨如何运用随机微分方程(Stochastic Differential Equations, SDEs)来构建和理解 score-based 生成模型。
SDE 提供了一个强大的数学框架,能够将 score-based model 和 DDPM (Denoising Diffusion Probabilistic Models) 等看似不同的模型统一起来。尽管基于 SDE 构建扩散模型引入了新的视角,但其核心思想依然围绕着 score function。
随机微分方程简介
首先,我们回顾一些随机微分方程的基础知识。作为对比,我们先看一个常微分方程(Ordinary Differential Equation, ODE)的例子:
dtdx=f(x,t)ordx=f(x,t)dt
其中 f(x,t) 描述了向量 x 随时间 t 的变化规律。该 ODE 的解析解为:
x(t)=x(0)+∫0tf(x,τ)dτ
在实际计算中,我们通常无法得到解析解,而是采用数值方法(如前向欧拉法)进行迭代逼近:
x(t+Δt)≈x(t)+f(x(t),t)Δt
ODE 描述的是确定性过程。然而,许多现实世界的过程(例如从复杂分布中采样)本质上是随机的,这时就需要随机微分方程(SDE)来进行描述。SDE 在 ODE 的基础上引入了一个随机噪声项:
dtdx=漂移项(drift)f(x,t)+扩散项(diffusion)g(t)wtordxt=f(xt,t)dt+g(t)dwt
其中:
- f(x,t) 称为漂移系数(drift coefficient),描述了 xt 的确定性趋势。
- g(t) 称为扩散系数(diffusion coefficient),控制随机扰动的强度。
- wt 表示标准布朗运动(Brownian motion),也称为维纳过程(Wiener process)。它是驱动随机性的核心,具有以下关键性质:
- 独立增量:对任意时间 s<t<u<v,增量 wt−ws 和 wv−wu 是独立的。
- 正态增量:增量 wt+Δt−wt 服从均值为 0、协方差矩阵为 Δt⋅I 的正态分布,即 wt+Δt−wt∼N(0,Δt⋅I)。
- 连续而不可导:wt 的样本路径几乎处处连续,但几乎处处不可导。
dwt 的积分(如伊藤积分)用于建模随机波动对系统动态的累积影响。与 ODE 类似,SDE 也可以通过数值方法进行迭代求解,例如使用欧拉-丸山(Euler-Maruyama)法:
x(t+Δt)≈x(t)+f(x(t),t)Δt+g(t)Δtzt
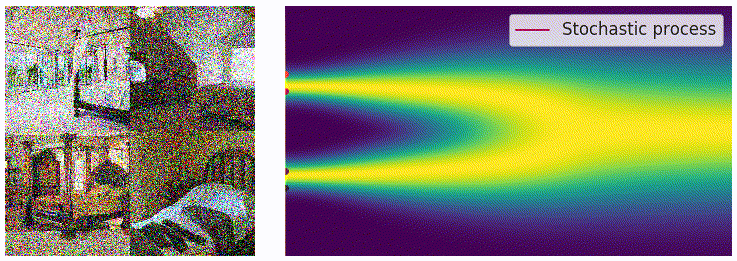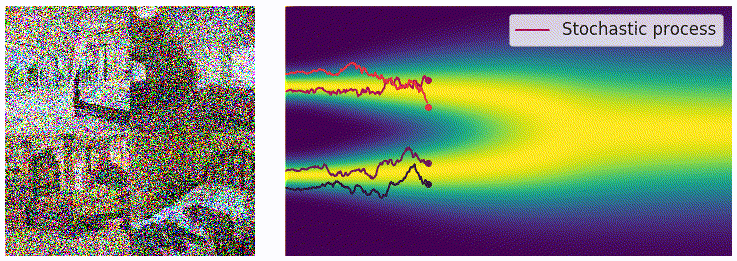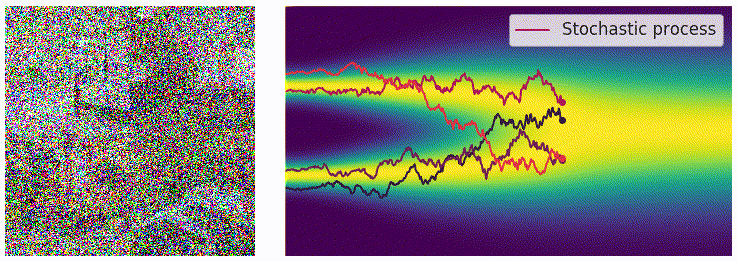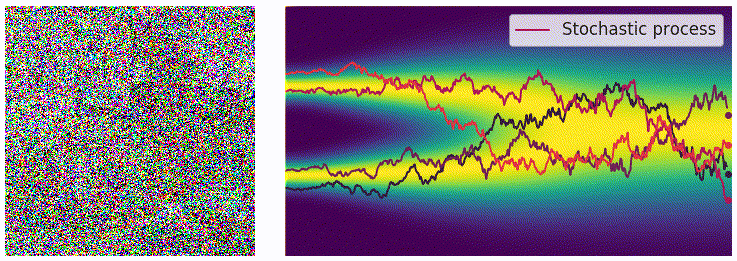
其中 zt∼N(0,I) 是一个标准高斯随机向量。由于采样过程中存在高斯噪声,对同一个 SDE 进行多次数值求解会得到不同的样本路径,如下图右侧所示的一系列绿色折线。
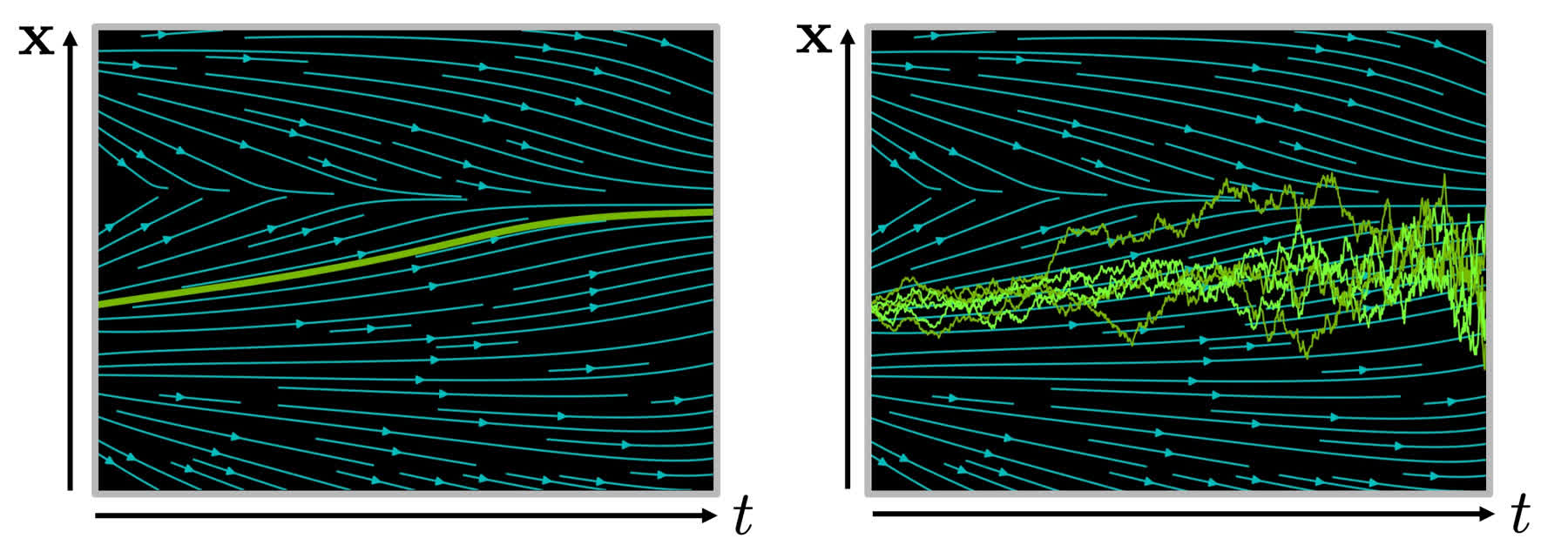
左:ODE 的确定性轨迹。右:SDE 的多条随机轨迹。
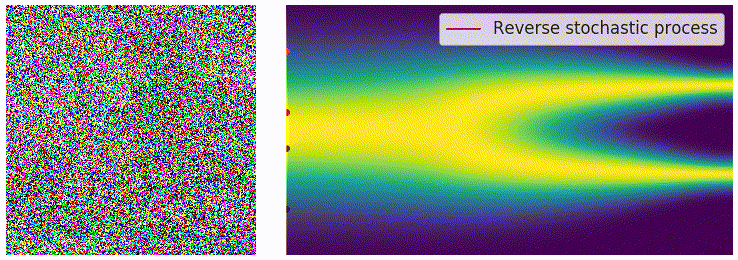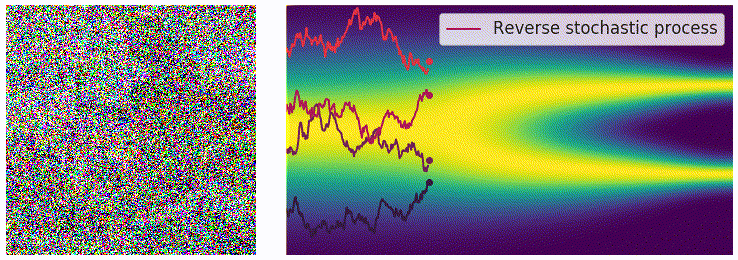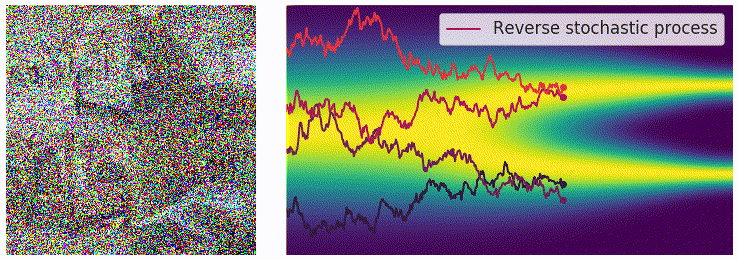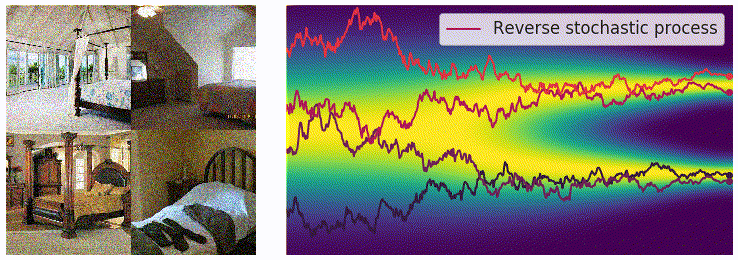
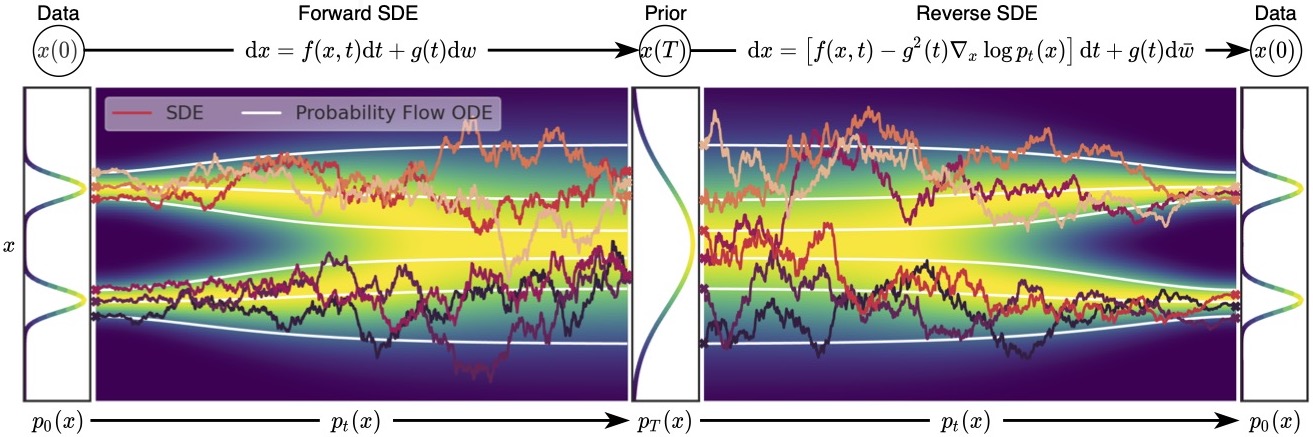
一个非常关键的结论是(不加证明地给出,数学家干的事情),对于一个由上述 SDE 定义的前向过程(forward process),其时间反向过程(reverse process)也同样由一个 SDE 描述。若前向 SDE 和反向 SDE 满足:
dx=f(x,t)dt+g(t)dwdx=[f(x,t)−g2(t)∇xlogpt(x)]dt+g(t)dw
其中 dw 表示反向的布朗运动,pt(x) 是 x(t) 在时刻 t 的概率密度函数。通常,我们设定 t=0 对应于真实数据分布 p0(x)=pdata(x),t=T 对应于一个已知的先验分布(如标准高斯分布 pT(x)≈N(0,I))。
在反向 SDE 中,红色的项 ∇xlogpt(x) 正是我们在 score-based models 中定义的 score function,记为 s(x,t)。与早期 score-based models 不同的是,这里的 score function 明确地依赖于时间 t(或者说,依赖于噪声水平)。实际上,在早期的 score-based models 中,p(x) 指的是在特定噪声水平扰动下的数据分布,因此它也隐式地依赖于扰动(或时间)。SDE 将这种依赖性明确化为 pt(x)
离散形式下,前向和反向过程可以近似为:
前向: xk+1反向: xk−1≈xk+f(xk,tk)Δt+g(tk)Δtzk≈xk+[f(xk,tk)−g2(tk)∇xlogptk(xk)](−Δt′)+g(tk)Δt′zk′≈xk−[f(xk,tk)−g2(tk)s(xk,tk)]Δt′+g(tk)Δt′zk′
(注意:这里 Δt 和 Δt′ 均为正的时间步长,反向过程是从 tk 到 tk−1=tk−Δt′)。
如果我们希望从随机噪声(先验分布 pT)中采样生成真实数据(目标分布 p0),我们只需要模拟这个反向 SDE。注意到,漂移项 f(x,t) 和扩散项 g(t) 在前向过程中是人为设定的,因此是已知的。所以,求解反向过程的关键在于估计 score function ∇xlogpt(x)。这正是 SDE 生成模型的训练核心:训练一个神经网络 sθ(x,t) 来逼近真实的 score function。
因此,对于 SDE 模型,我们可以采用类似 score matching 的方法来训练模型 sθ(x,t),其优化目标通常为:
J(θ)=Et∼U(0,T)Ex0∼p0(x)Ext∼pt(x∣x0)[λ(t)∥sθ(xt,t)−∇xtlogpt(xt∣x0)∥22]
其中 λ(t) 是一个与时间相关的正权重函数,∇xtlogpt(xt∣x0) 是给定 x0 时 xt 的真实 score。
SDE 与 DDPM
通过上述介绍,我们不难发现基于 SDE 的 score-based model 与 DDPM (Denoising Diffusion Probabilistic Models) 之间存在诸多相似之处。下面我们将展示 DDPM 实际上可以被视为一种特定 SDE 的离散化实现。
DDPM 的前向 SDE (VP SDE)
在 DDPM 中,前向加噪过程被定义为一系列离散步骤:
xk=1−βkxk−1+βkϵk−1,ϵk−1∼N(0,I)
其中 k∈{1,…,N},N 是总的扩散步数,βk 是预设的噪声方差表。为了将其与连续时间的 SDE 联系起来,我们将时间 t 标准化到 [0,T](通常 T=1)。离散时间步 k 对应连续时间 t=k/N⋅T。设 Δt=T/N。我们可以将 βk 重新参数化为与连续时间相关的函数 β(t),使得 βk≈β(tk)Δt (这里假设 Δt=1/N,是为了计算简便表述)。
考虑 x(t) 和 x(t+Δt) 的关系:
x(t+Δt)=1−β(t+Δt)Δtx(t)+β(t+Δt)Δtϵ(t)≈(1−21β(t+Δt)Δt)x(t)+β(t+Δt)Δtϵ(t)
整理后得到:
x(t+Δt)−x(t)≈−21β(t+Δt)Δtx(t)+β(t+Δt)Δtϵ(t)
当 Δt→0,并且假设 β(t+Δt)→β(t),上式可以写作 SDE 的形式:
dxt=−21β(t)xtdt+β(t)dwt
这就是所谓的方差保持(Variance Preserving, VP)SDE。在此 SDE 中:
f(xt,t)=−21β(t)xt,g(t)=β(t)
DDPM 的逆向 SDE
根据前向 SDE 和通用的反向 SDE 公式,DDPM 对应的反向 SDE 为:
dxt=[f(xt,t)−g2(t)∇xtlogpt(xt)]dt+g(t)dwt=[−21β(t)xt−β(t)∇xtlogpt(xt)]dt+β(t)dwt
在 DDPM 中,score function ∇xtlogpt(xt) 通常通过一个神经网络 sθ(xt,t) 来估计。这个网络实际上被训练来预测噪声 ϵt (给定 xt 和 x0),两者之间存在如下关系:
xt=αˉtx0+1−αˉtϵ
其中 αˉt=∏s=1k(1−βs)。真实的 score function ∇xtlogpt(xt∣x0) 为:
∇xtlogpt(xt∣x0)=−1−e−∫0tβ(s)dsxt−x0e−21∫0tβ(s)ds=−1−e−∫0tβ(s)dsϵt
(这里 ϵt 是使得 xt=x0e−21∫0tβ(s)ds+1−e−∫0tβ(s)dsϵt 成立的标准高斯噪声)。
DDPM 训练的噪声预测模型 ϵθ(xt,t) 与 score 模型 sθ(xt,t) 的关系为:
sθ(xt,t)=−1−αˉtϵθ(xt,t)
其中 αˉt 是与 DDPM 中 αk 累乘对应的连续时间量。
DDPM 的祖先采样(ancestral sampling)过程可以被视为上述逆向 SDE 的一种特定离散化求解器。例如,Euler-Maruyama 方法对逆向 SDE 进行离散化(时间步从 t 到 t−Δt,即 dt=−Δt):
xt−Δt≈=xt+[−21β(t)xt−β(t)sθ(xt,t)](−Δt)+β(t)Δtztxt+[21β(t)xt+β(t)sθ(xt,t)]Δt+β(t)Δtzt
这个形式与 DDPM 论文中推导出的采样步骤是紧密相关的,尽管 DDPM 的采样器有其特定的形式和推导
为了更清晰地展示这种联系,我们首先写出经过替换 sθ(xt,t)=−1−αˉtϵθ(xt,t) 后的 Euler-Maruyama 离散形式。记 Δβt=β(t)Δt 为单步离散的噪声方差:
xt−Δt≈(1+21Δβt)xt−1−αˉtΔβtϵθ(xt,t)+Δβtzt(SDE Euler-Maruyama)
DDPM 论文中祖先采样步骤(若取采样方差为 βtDDPM,对应此处的 Δβt)可以写作:
xt−Δt=1−Δβt1xt−1−Δβt1−αˉtΔβtϵθ(xt,t)+Δβtzt(DDPM Sampler)
比较两式:
- 噪声项 Δβtzt 完全相同
- xt 的系数:在 DDPM Sampler 中为 (1−Δβt)−1/2,其泰勒展开为 1+21Δβt+83(Δβt)2+…。SDE Euler-Maruyama 中的系数 1+21Δβt 是其一阶近似
- ϵθ(xt,t) 的系数:在 DDPM Sampler 中为 −1−αˉtΔβt(1−Δβt)−1/2。展开后为 −1−αˉtΔβt(1+21Δβt+…)=−1−αˉtΔβt−211−αˉt(Δβt)2+…。SDE Euler-Maruyama 中的系数 −1−αˉtΔβt 是其主导项
因此,当 Δβt(即 β(t)Δt)很小时,Euler-Maruyama 离散化与 DDPM 的采样步骤非常接近。DDPM 的采样器可以看作是对应逆向过程的一个更精确的(针对其离散推导的)数值解法
推导到这里可以发现,DDPM 的核心机制,无论是前向加噪还是逆向去噪,都可以被统一在 SDE 的框架下进行描述和理解。这为我们提供了一个更普适的视角来看待和设计扩散模型,并允许我们利用 SDE 理论中的各种数值求解器进行采样
SDE 与 SMLD (NCSN)
除了 DDPM,另一类 score-based 生成模型是基于朗之万动力学(Langevin Dynamics)的 Score Matching with Langevin Dynamics (SMLD),也常被称为 Noise Conditional Score Networks (NCSN)。SMLD 同样可以被 SDE 框架所统一
SMLD 的前向 SDE (VE SDE)
SMLD/NCSN 的核心思想是在一系列递增的噪声水平 {σ1<σ2<⋯<σM} 下扰动数据,并为每个噪声水平训练一个 score network sθ(x,σi)≈∇xlogpσi(x)。
这个过程可以用一个连续时间的 SDE 来描述,通常被称为方差爆炸(Variance Exploding, VE)SDE。VE SDE 的一般形式为:
dxt=g(t)dwt
注意到,这个 SDE 的漂移项 f(xt,t)=0。扩散系数 g(t) 的选择需要使得在时间 t 时,xt 的条件分布 pt(xt∣x0) 的方差与 SMLD 中离散噪声水平 σ(t)2 相匹配。具体来说,从 x0 出发,经过时间 t 后,xt 的分布为:
pt(xt∣x0)=N(xt;x0,∫0tg(s)2ds⋅I)
我们希望 ∫0tg(s)2ds=σ(t)2,其中 σ(t) 是一个随时间 t(从 0 到 T)单调递增的函数,例如从 σmin (接近0) 变化到 σmax。对上式两边关于 t 求导,可得:
g(t)2=dtdσ(t)2
因此,g(t)=dtdσ(t)2。一个常见的 σ(t) 选择是指数形式,例如 σ(t)=σmin(σminσmax)t/T,这使得噪声方差随时间指数增长
SMLD 的逆向 SDE
知道了 SMLD 对应的前向 SDE(漂移项 f(xt,t)=0,扩散项 g(t)=dtdσ(t)2),我们可以利用通用的反向 SDE 公式得到其逆向 SDE:
dxt=[f(xt,t)−g2(t)∇xtlogpt(xt)]dt+g(t)dwt=[0−g2(t)sθ(xt,t)]dt+g(t)dwt=−g2(t)sθ(xt,t)dt+g(t)dwt
其中 sθ(xt,t) 是神经网络对真实 score ∇xtlogpt(xt) 的估计。在 SMLD 的实践中,这个网络通常以噪声水平 σ(t) 作为条件输入,即 sθ(xt,σ(t))。
与退火朗之万动力学的联系
SMLD/NCSN 在生成样本时采用的是退火朗之万动力学(Annealed Langevin Dynamics)。该过程从一个高噪声水平 σM 开始,逐步降低噪声水平到 σ1,在每个噪声水平 σi 下,通过多步朗之万采样来精炼样本:
x(k+1)=x(k)+ηisθ(x(k),σi)+2ηizk
其中 ηi 是步长,zk∼N(0,I)。
我们可以看到,上述朗之万动力学步骤与逆向 SDE 的 Euler-Maruyama 离散化形式非常相似。对 SMLD 的逆向 SDE 进行离散化(时间步从 t 到 t−Δt,即 dt=−Δt):
xt−Δt≈=xt+[−g2(t)sθ(xt,t)](−Δt)+g(t)Δtztxt+g2(t)sθ(xt,t)Δt+g(t)Δtzt
如果我们将朗之万动力学中的步长 ηi 对应于 g2(t)Δt/2 (或者说,如果 g2(t)Δt=αi 且 g(t)Δt=2αi,则需要 g2(t)Δt=2αi),那么两者形式上就非常接近了。更准确地说,朗之万动力学本身就是对某个目标概率分布 p(x) 进行采样的随机过程,其对应的 SDE(过阻尼朗之万方程)为 dXt=∇logp(Xt)dt+2dWt(这里步长被吸收到时间尺度中)。
SMLD 的逆向 SDE dxt=−g2(t)sθ(xt,t)dt+g(t)dwt 正是指导样本从噪声向数据演化的过程。退火朗之万动力学可以被视为求解这个逆向 SDE 的一种特定数值方法,其中 score sθ(xt,t) 扮演了 ∇logpt(xt) 的角色,而 g(t) 控制了噪声的注入。
SMLD 的训练目标
SMLD 的训练目标是让神经网络 sθ(x,σi) 在每个离散的噪声水平 σi 上逼近真实的 score ∇xlogp(x∣x0,σi)。对于高斯扰动核 p(x∣x0,σi)=N(x;x0,σi2I),真实的 score 是:
∇xlogp(x∣x0,σi)=−σi2x−x0
SMLD 的损失函数通常是所有噪声水平上带权重的 score matching 损失之和:
JSMLD(θ)=i=1∑Mλ(σi)Ep0(x0)Ex∼p(x∣x0,σi)[∥sθ(x,σi)−∇xlogp(x∣x0,σi)∥22]
这与 SDE 的通用训练目标形式一致,其中 λ(σi) 是权重,通常取 σi2 或者 g(map to continuous time(σi))2。SDE 框架将离散的噪声水平 σi 推广到了连续的时间 t 和连续的噪声尺度函数 σ(t)。
通过 SDE 的视角,SMLD/NCSN 模型也被纳入了统一的框架中,其前向过程是一个无漂移的 SDE,逆向过程则通过估计随时间(或噪声水平)变化的 score function 来驱动。这不仅加深了我们对这些模型的理解,也为开发新的采样算法和模型变体提供了理论基础