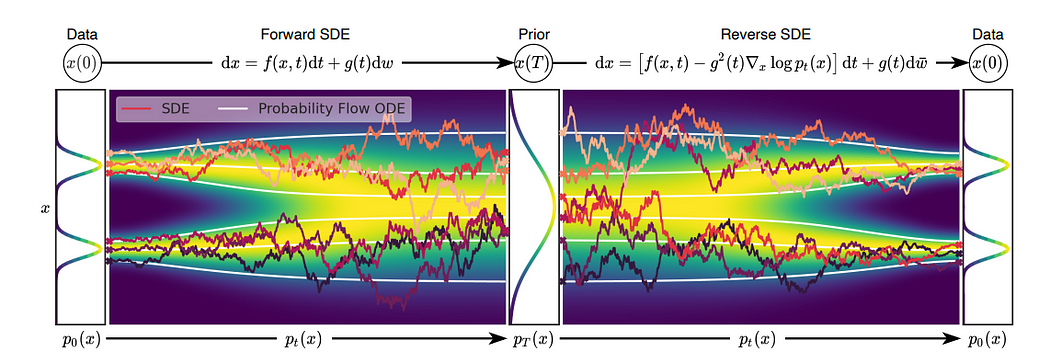
基于分数的生成模型(Score-based Generative Model )
Overview
首先简单讲讲分数模型(score-based models) 是怎么回事,以一句话总结来说就是:
它估计 数据分布相关的梯度 并基于 朗之万动力学(Langevin Dynamics) 的思想来生成样本。

Score Matching
如果有一组数据 {x1,x1,…,xn},我们的目的是最大化对数似然:
θmaxi=1∑nlogpθ(x)
由于概率的性质的硬约束(和为 1,非负性),我们让
pθ(x)=∫Xe−fθ(x)dxe−fθ(x)⇒logpθ(x)=−fθ(x)−logZθ
其中 Zθ=∫Xe−fθ(x)dx,优化问题变为了:
θmaxi=1∑nlogZθ−i=1∑nfθ(x)
在这里 zθ=∑i=1nlog∫Xe−fθ(x)dx 是 intractable 的,像 VAE 中就是通过 ELBO 规避了这个问题,在这篇文章中我们寻求另一种解决方法,即 score based 的方法来最大化对数似然。
score 的定义:
我们定义 score 为:
sθ(x)=∂x∂logpθ(x)=−∇xfx
优化目标为:
θ∗=21argθminEpdata∥s(x)−sθ(x)∥2
其中 s(x) 为真实数据的分数函数,关于为什么能转化优化目标,我们在下一节的 score 的物理意义讨论。再回到如何解这个优化问题上,实际上真实数据的分数函数是不可知的,这对接下来的推导造成了困难,下面用一种巧妙的方法规避这个问题:
设概率路径pt(x)满足p1(x)=pdata(x),定义速度场vt(x)=Ept(x∣x0)[v(x0)],目标函数推导如下:
步骤 1:初始目标函数
J(θ)=21∥∥∥Ep(x)[S(x)−S0(x)]∥∥∥2
步骤 2:展开平方项
J(θ)=21Ep(x)∥sθ(x)∥2−Ep(x)[sθ(x)⊤s(x)]+const
步骤 3:代入得分函数定义
设s(x)=∇xlogp(x),则交叉项可改写为:
Ep(x)[S0(x)⊤S(x)]=∫p(x)S0(x)⊤∇xlogp(x)dx
步骤 4:应用分部积分法
∫p(x)S0⊤∇xlogpdx=∫S0⊤∇xpdx==0p(x)S0(x)∣∣∣−∞+∞−∫p(x)∇x⋅S0(x)dx
⇒J(θ)=−21Ep(x)∥S0(x)∥2−Ep(x)[∇x⋅S0(x)]+const
其实,上面说的“数据分布相关的梯度”实质上是对数概率密度函数对于输入数据的梯度,第一次提出是 Stein Score ,这就是分数。score based 的模型就是训练它让它学会估计(预测)分数。
物理意义
score 的具体物理意义是:对于输入数据(样本)来说,其对数概率密度增长最快的方向。如果我们已经训练好了一个分数预测模型,那么我们可以类似 energy based model 的推理方法,使用梯度下降法来最大化一个样本的对数似然,让这个样本的概率最大化

但是我们训练网络的目的就是具有泛化性,我们需要避免网络的输出和原来的数据一模一样的情况,因此我们需要在采样的过程中加入噪声。最终的效果应该是在保证多样性的同时也要符合(靠近)原数据分布。于是就采用了 Langevin Dynamics 采样方法
Langevin Dynamics
Langevin dynamics 指朗之万动力学方程,是描述物理学中布朗运动(悬浮在液体/气体中的微小颗粒所做的无规则运动)的微分方程,借鉴到这里作为一种生成样本的方法。概括地来说,该方法首先从先验分布随机采样一个初始样本,然后利用模型估计出来的分数逐渐将样本向数据分布的高概率密度区域靠近。为保证生成结果的多样性,我们需要采样过程带有随机性。朗之万动力学采样刚好满足这一点。
dX(t)=−∇xU(X(t))dt+σdtztzt∼N(0,I)
其中 U 代表能量函数,这个式子其实很好理解,我们把它写为离散型,令 dt=ϵ:
xϵ+t−xt=−∇xU(xt)ϵ+σϵzt⇒xt+ϵ=xt−∇xU(xt)ϵ+σϵzt
也就是梯度下降加上一个随机项,随机项服从一个均值为 0 方差为 ϵσ2 的正态分布。
套入我们的分数函数,让 x0∼N(0,I),目标为最终的 xN∼pdata(x),我们用一个 p(x,t) 表述,则:
P(x,0)∼P(x,T)∼∂t∂p(x,T)=N(0,I)pθ(x)≈pdata(x)0
根据 Fokker-Planck 方程:
∂t∂P(x,t)=∇xP(x,t)T∇U(x)+P(x,t)div∇U(x)+21σ2ΔP(x,t)
之前的工作结论是 Fokker-Planck 方程为零时,可以求得,T=σ2/2,当当在我们定义能量函数的时候,其实已经默认设置了 T=1(Gibbs 分布的一般形式为 pθ(x)=exp(−Tfθ(x))/Zθ)。因此代入 σ=2:
xt+ϵ==xt−∇xfθ(x)ϵ+2ϵztxt+sθ(x)ϵ+2ϵzt
根据这个采样公式,就可以满足最终的 xT∼pθ(x) 了。
Denoising Score Matching
Noise Conditional Score Network(NCSN)
根据流形假设,我们假设真实图像概率分布空间为高维空间内的一个流形,这样会导致一个问题,就是在训练的时候一些空间内的分布 p(x)=0,就会导致无法训练对应区域的 sθ(x)。但是我们采样的过程中是有可能经过这些点的,因此这些点的 score 也需要正确估计,即需要训练到(还是经典的一句话,数据分布要尽可能覆盖大的空间,有没有对应方向的梯度和梯度小不小是两码事)
为了解决这个问题,作者引入了增噪的手段,假设增加噪声满足概率分布 N(0,σ2),增噪后真是数据概率分布为

优化目标推导
根据加噪条件分布 qσ(x∣x′)=N(x′,σ2I),其对数梯度为:
logqσ(x∣x′)∇xlogqσ(x∣x′)=−2σ2∥x−x′∥2+const=−σ2x−x′
优化目标是最小化估计分数 sθ(x,σ) 与真实分数 ∇xlogqσ(x∣x′) 的均方误差:
J(θ)=21Eqσ(x∣x′)Ep(x′)∥sθ(x,σ)−∇xlogqσ(x∣x′)∥2=21Ex′∼p(x′)Ex∼N(x′,σ2I)∥∥∥∥∥sθ(x,σ)+σ2x−x′∥∥∥∥∥2
此时,qσ(x)=∫qσ(x∣x′)p(x′)dx′ 是加噪后的真实数据分布
多噪声尺度训练:
在前面的分析中提及到,为了让扰动后的分布能够更多地“填充”原来的低概率密度区域,但是强度过大的噪声反之会干扰到原始数据的分布进而造成估计分数的误差增大,从而基于加噪后的分数使用朗之万动力学采样生成的结果也就不太符合原数据分布;相反地,噪声强度小能够获得与原数据分布较为近似的效果,但是却不能够很好地“填充”低概率密度区域。因此训练的时候使用了多尺度的噪声等级序列,即最开始的噪声水平足够大以能够充分“填充"低概率密度区域;而最后的噪声水平足够小以获得对原数据分布良好的近似,避免过度扰动对
L 个噪声级别 {σi}i=1L,引入权重 λ(σi) 平衡不同噪声的贡献,联合损失为:
L(θ;{σi})=L1i=1∑Lλ(σi)J(θ;σi)
其中 λ(σi) 的常见选择是 λ(σi)=σi2,以抵消 σ21 的尺度效应
核心代码分析
Loss损失函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| def anneal_dsm_score_estimation(scorenet, samples, labels, sigmas, anneal_power=2.):
used_sigmas = sigmas[labels].view(samples.shape[0], *([1] * len(samples.shape[1:])))
perturbed_samples = samples + torch.randn_like(samples) * used_sigmas
target = - 1 / (used_sigmas ** 2) * (perturbed_samples - samples)
scores = scorenet(perturbed_samples, labels)
target = target.view(target.shape[0], -1)
scores = scores.view(scores.shape[0], -1)
loss = 1 / 2. * ((scores - target) ** 2).sum(dim=-1) * used_sigmas.squeeze() ** anneal_power
return loss.mean(dim=0)
|
annealed Langevin dynamics:这部分是根据上面的伪代码实现的,具体算法流程参见上面的伪代码公式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def anneal_Langevin_dynamics(self, x_mod, scorenet, sigmas, n_steps_each=100, step_lr=0.00002):
images = []
with torch.no_grad():
for c, sigma in tqdm.tqdm(enumerate(sigmas), total=len(sigmas), desc='annealed Langevin dynamics sampling'):
labels = torch.ones(x_mod.shape[0], device=x_mod.device) * c
labels = labels.long()
step_size = step_lr * (sigma / sigmas[-1]) ** 2
for s in range(n_steps_each):
images.append(torch.clamp(x_mod, 0.0, 1.0).to('cpu'))
noise = torch.randn_like(x_mod) * np.sqrt(step_size * 2)
grad = scorenet(x_mod, labels)
x_mod = x_mod + step_size * grad + noise
return images
|