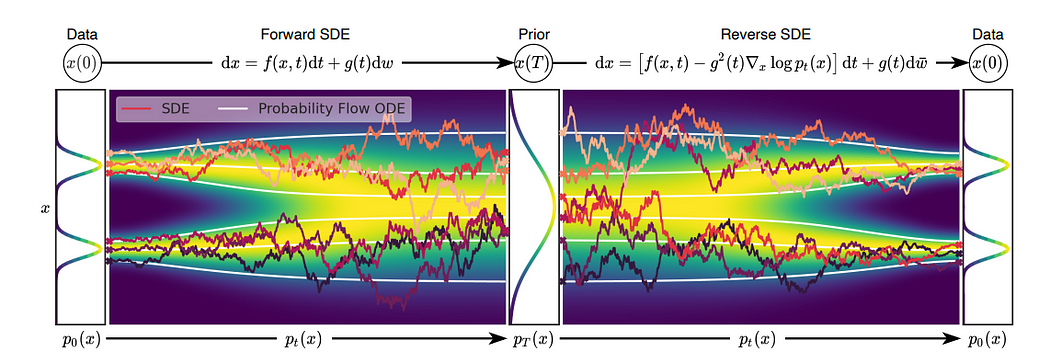
首先,我们来探讨一下什么是基于分数的生成模型(Score-based Generative Models,简称SGM)。其核心思想可以概括为:该模型通过估计数据概率密度函数的对数梯度(即“分数”) ,并借鉴**朗之万动力学(Langevin Dynamics)**的原理来逐步生成新的数据样本
假设我们有一组从真实数据分布 p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x ) { x 1 , x 2 , … , x n } \{\boldsymbol x_1, \boldsymbol x_2, \dots, \boldsymbol x_n\} { x 1 , x 2 , … , x n } p θ ( x ) p_\theta(\boldsymbol x) p θ ( x )
max θ ∑ i = 1 n log p θ ( x i ) \max_\theta \sum_{i=1}^n \log p_\theta(\boldsymbol x_i)
θ max i = 1 ∑ n log p θ ( x i )
为了处理概率分布的归一化约束(积分为1且非负),我们通常将概率密度函数参数化为能量模型的形式:
p θ ( x ) = e − f θ ( x ) ∫ X e − f θ ( y ) d y p_\theta(\boldsymbol x) = \frac{e^{-f_\theta(\boldsymbol x)}}{\int_\mathcal{X} e^{-f_\theta(\boldsymbol y)}d\boldsymbol y}
p θ ( x ) = ∫ X e − f θ ( y ) d y e − f θ ( x )
其中 f θ ( x ) f_\theta(\boldsymbol x) f θ ( x ) Z θ = ∫ X e − f θ ( y ) d y Z_\theta = \int_\mathcal{X} e^{-f_\theta(\boldsymbol y)}d\boldsymbol y Z θ = ∫ X e − f θ ( y ) d y
log p θ ( x ) = − f θ ( x ) − log Z θ \log p_\theta(\boldsymbol x)= -f_\theta(\boldsymbol x) - \log Z_\theta
log p θ ( x ) = − f θ ( x ) − log Z θ
因此,最大化对数似然的优化问题转变为:
max θ ( − ∑ i = 1 n f θ ( x i ) − n log Z θ ) \max_\theta \left( - \sum_{i=1}^n f_\theta(\boldsymbol x_i) - n \log Z_\theta \right)
θ max ( − i = 1 ∑ n f θ ( x i ) − n log Z θ )
然而,直接计算配分函数 Z θ Z_\theta Z θ
我们将数据点 x \boldsymbol x x log p θ ( x ) \log p_\theta(\boldsymbol x) log p θ ( x ) x \boldsymbol x x
s θ ( x ) = ∇ x log p θ ( x ) s_\theta(\boldsymbol x) = \nabla_x \log p_\theta(\boldsymbol x)
s θ ( x ) = ∇ x log p θ ( x )
结合能量模型的形式,由于 Z θ Z_\theta Z θ x \boldsymbol x x
s θ ( x ) = ∇ x ( − f θ ( x ) − log Z θ ) = − ∇ x f θ ( x ) s_\theta(\boldsymbol x) = \nabla_x (-f_\theta(\boldsymbol x) - \log Z_\theta) = -\nabla_x f_\theta(\boldsymbol x)
s θ ( x ) = ∇ x ( − f θ ( x ) − log Z θ ) = − ∇ x f θ ( x )
分数匹配的核心思想是训练一个模型 s θ ( x ) s_\theta(\boldsymbol x) s θ ( x ) p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x ) s data ( x ) = ∇ x log p data ( x ) s_{\text{data}}(\boldsymbol x) = \nabla_x \log p_{\text{data}}(\boldsymbol x) s data ( x ) = ∇ x log p data ( x )
θ ∗ = arg min θ 1 2 E x ∼ p data ( x ) ∥ s data ( x ) − s θ ( x ) ∥ 2 \theta^* = \arg\min_\theta \frac{1}{2} \mathbb{E}_{\boldsymbol x \sim p_{\text{data}}(\boldsymbol x)}\left\Vert s_{\text{data}}(\boldsymbol x) - s_\theta(\boldsymbol x) \right\Vert^2
θ ∗ = arg θ min 2 1 E x ∼ p data ( x ) ∥ s data ( x ) − s θ ( x ) ∥ 2
其中 s data ( x ) s_{\text{data}}(\boldsymbol x) s data ( x ) s data ( x ) s_{\text{data}}(\boldsymbol x) s data ( x ) p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x ) p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x )
一种避免直接计算 s data ( x ) s_{\text{data}}(\boldsymbol x) s data ( x ) p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x ) θ \theta θ
θ ∗ = arg min θ E x ∼ p data ( x ) [ 1 2 ∥ s θ ( x ; θ ) ∥ 2 + ∇ x ⋅ s θ ( x ; θ ) ] \theta^* = \arg\min_\theta \mathbb{E}_{\boldsymbol x \sim p_{\text{data}}(\boldsymbol x)}\left[ \frac{1}{2}\Vert s_\theta(\boldsymbol x; \theta) \Vert^2 + \nabla_x \cdot s_\theta(\boldsymbol x; \theta) \right]
θ ∗ = arg θ min E x ∼ p data ( x ) [ 2 1 ∥ s θ ( x ; θ ) ∥ 2 + ∇ x ⋅ s θ ( x ; θ ) ]
其中 ∇ x ⋅ s θ ( x ; θ ) \nabla_x \cdot s_\theta(\boldsymbol x; \theta) ∇ x ⋅ s θ ( x ; θ ) s θ ( x ; θ ) s_\theta(\boldsymbol x; \theta) s θ ( x ; θ ) s data ( x ) s_{\text{data}}(\boldsymbol x) s data ( x )
正如其名,“分数”即指数据点 x \boldsymbol x x log p ( x ) \log p(\boldsymbol x) log p ( x ) x \boldsymbol x x ∇ x log p ( x ) \nabla_x \log p(\boldsymbol x) ∇ x log p ( x ) s θ ( x ) s_\theta(\boldsymbol x) s θ ( x )
分数的物理意义非常直观:它指向数据点 x \boldsymbol x x s θ ( x ) ≈ ∇ x log p data ( x ) s_\theta(\boldsymbol x) \approx \nabla_x \log p_{\text{data}}(\boldsymbol x) s θ ( x ) ≈ ∇ x log p data ( x )
然而,单纯的梯度上升可能会导致生成的样本仅仅是训练数据的简单复制,缺乏多样性。为了生成新颖且多样化的样本,同时确保它们仍然符合目标数据分布,引入了随机性。朗之万动力学(Langevin Dynamics)采样方法便为此提供了一个有效的框架。
朗之万动力学最初用于描述物理学中粒子在势场中的随机运动(如布朗运动)。在生成模型领域,它被借鉴为一种从复杂分布中采样的方法。其核心思想是:从一个简单的先验分布(如高斯分布)中随机初始化一个样本,然后通过迭代更新使其逐渐向目标数据分布的高概率密度区域移动。这个更新过程不仅包括了沿着分数(梯度)方向的确定性移动,还引入了高斯噪声以保证生成样本的多样性和随机性。其随机微分方程 (SDE) 形式可以写作:
d X ( t ) = − ∇ x U ( X ( t ) ) d t + 2 D d W ( t ) d \boldsymbol X(t) = -\nabla_x U(\boldsymbol X(t)) dt + \sqrt{2D} d\boldsymbol W(t)
d X ( t ) = − ∇ x U ( X ( t ) ) d t + 2 D d W ( t )
其中 U ( X ( t ) ) U(\boldsymbol X(t)) U ( X ( t ) ) − log p ( X ( t ) ) -\log p(\boldsymbol X(t)) − log p ( X ( t ) ) ∇ x U ( X ( t ) ) \nabla_x U(\boldsymbol X(t)) ∇ x U ( X ( t ) ) D D D d W ( t ) d\boldsymbol W(t) d W ( t )
将其离散化,令时间步长为 ϵ = d t \epsilon = dt ϵ = d t U ( x ) = f θ ( x ) U(\boldsymbol x) = f_\theta(\boldsymbol x) U ( x ) = f θ ( x ) s θ ( x ) = − ∇ x f θ ( x ) s_\theta(\boldsymbol x) = -\nabla_x f_\theta(\boldsymbol x) s θ ( x ) = − ∇ x f θ ( x )
x t + ϵ = x t + s θ ( x t ) ϵ + 2 D ϵ z t \boldsymbol x_{t+\epsilon} = \boldsymbol x_t + s_\theta(\boldsymbol x_t)\epsilon + \sqrt{2D\epsilon}\boldsymbol z_t
x t + ϵ = x t + s θ ( x t ) ϵ + 2 D ϵ z t
其中 z t ∼ N ( 0 , I ) \boldsymbol z_t \sim \mathcal{N}(0, I) z t ∼ N ( 0 , I )
我们从一个简单的先验分布(如标准正态分布 N ( 0 , I ) \mathcal{N}(\boldsymbol 0, \boldsymbol I) N ( 0 , I ) x 0 \boldsymbol x_0 x 0 x T \boldsymbol x_T x T p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x )
朗之万动力学有一个重要的性质:如果其对应的 Fokker-Planck 方程的稳态解为 p θ ( x ) ∝ exp ( − f θ ( x ) ) p_\theta(\boldsymbol x) \propto \exp(-f_\theta(\boldsymbol x)) p θ ( x ) ∝ exp ( − f θ ( x ) ) D D D
x t + ϵ = x t + s θ ( x t ) ϵ + 2 ϵ z t \boldsymbol x_{t+\epsilon} = \boldsymbol x_t + s_\theta(\boldsymbol x_t)\epsilon + \sqrt{2\epsilon} \boldsymbol z_t
x t + ϵ = x t + s θ ( x t ) ϵ + 2 ϵ z t
通过迭代这个更新规则足够多次,从 x 0 ∼ N ( 0 , I ) \boldsymbol x_0 \sim \mathcal{N}(\boldsymbol 0, \boldsymbol I) x 0 ∼ N ( 0 , I ) x T \boldsymbol x_T x T p θ ( x ) p_\theta(\boldsymbol x) p θ ( x )
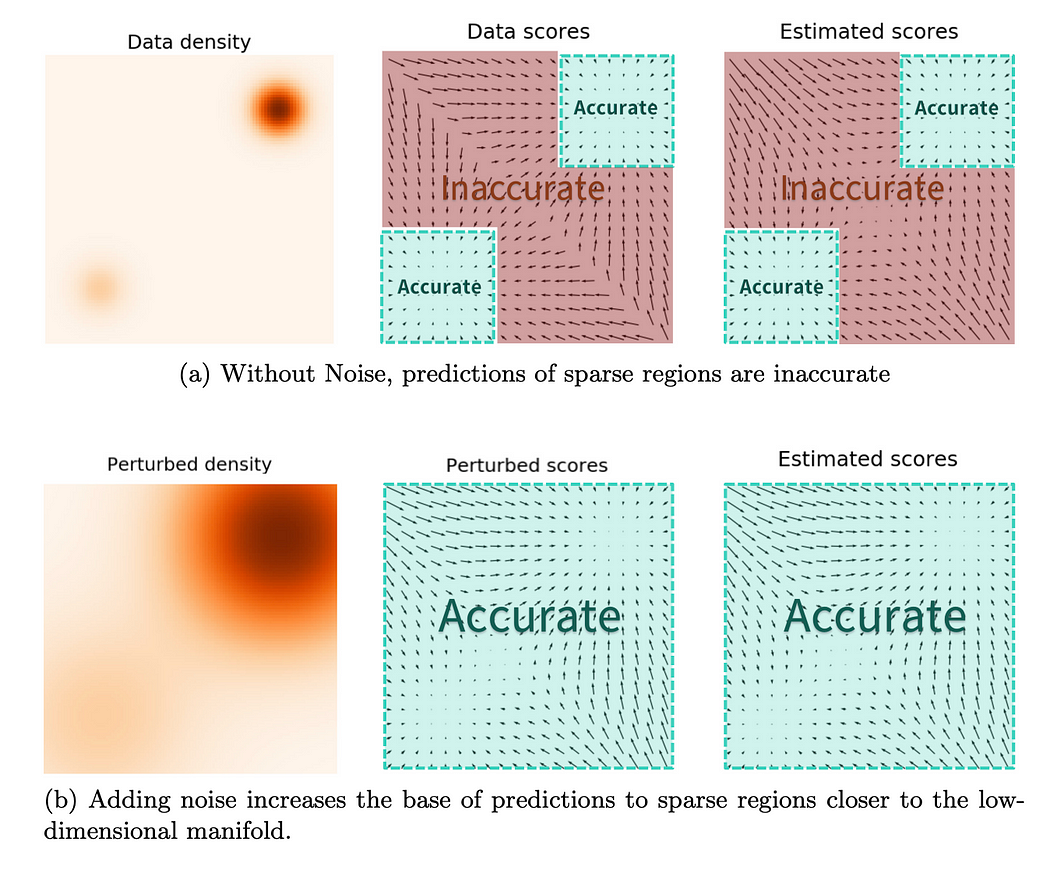
原始的分数匹配方法(尤其是显式分数匹配)在处理高维数据(如图像)时面临挑战。根据流形假设(manifold hypothesis),真实数据往往分布在高维空间中的一个低维流形上。这意味着在流形之外的区域,数据密度 p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x ) ∇ x log p data ( x ) \nabla_x \log p_{\text{data}}(\boldsymbol x) ∇ x log p data ( x )
为了解决这个问题,一个关键的改进是引入噪声扰动数据。去噪分数匹配(Denoising Score Matching, DSM)通过向原始数据 x ′ \boldsymbol x' x ′ p data p_{\text{data}} p data n ∼ N ( 0 , σ 2 I ) \boldsymbol n \sim \mathcal{N}(\boldsymbol 0, \sigma^2 \boldsymbol I) n ∼ N ( 0 , σ 2 I ) x = x ′ + n \boldsymbol x = \boldsymbol x' + \boldsymbol n x = x ′ + n q σ ( x ) = ∫ p data ( x ′ ) N ( x ∣ x ′ , σ 2 I ) d x ′ q_\sigma(\boldsymbol x) = \int p_{\text{data}}(\boldsymbol x') \mathcal{N}(\boldsymbol x | \boldsymbol x', \sigma^2 \boldsymbol I) d\boldsymbol x' q σ ( x ) = ∫ p data ( x ′ ) N ( x ∣ x ′ , σ 2 I ) d x ′
此时,我们不再直接估计 p data ( x ) p_{\text{data}}(\boldsymbol x) p data ( x ) q σ ( x ) q_\sigma(\boldsymbol x) q σ ( x ) ∇ x log q σ ( x ) \nabla_x \log q_\sigma(\boldsymbol x) ∇ x log q σ ( x ) s θ ( x , σ ) s_\theta(\boldsymbol x, \sigma) s θ ( x , σ ) σ \sigma σ q σ ( x ∣ x ′ ) q_\sigma(\boldsymbol x | \boldsymbol x') q σ ( x ∣ x ′ ) ∇ x log q σ ( x ∣ x ′ ) \nabla_x \log q_\sigma(\boldsymbol x | \boldsymbol x') ∇ x log q σ ( x ∣ x ′ )
对于给定的原始数据点 x ′ \boldsymbol x' x ′ σ \sigma σ x ∼ q σ ( x ∣ x ′ ) = N ( x ∣ x ′ , σ 2 I ) \boldsymbol x \sim q_\sigma(\boldsymbol x|\boldsymbol x') = \mathcal{N}(\boldsymbol x | \boldsymbol x', \sigma^2 \boldsymbol I) x ∼ q σ ( x ∣ x ′ ) = N ( x ∣ x ′ , σ 2 I ) x \boldsymbol x x
log q σ ( x ∣ x ′ ) = − ∥ x − x ′ ∥ 2 2 σ 2 + const \log q_\sigma(\boldsymbol x|\boldsymbol x') = -\frac{\|\boldsymbol x - \boldsymbol x'\|^2}{2\sigma^2} + \text{const}
log q σ ( x ∣ x ′ ) = − 2 σ 2 ∥ x − x ′ ∥ 2 + const
∇ x log q σ ( x ∣ x ′ ) = − x − x ′ σ 2 \nabla_x \log q_\sigma(\boldsymbol x|\boldsymbol x') = -\frac{\boldsymbol x - \boldsymbol x'}{\sigma^2}
∇ x log q σ ( x ∣ x ′ ) = − σ 2 x − x ′
去噪分数匹配的目标是训练一个噪声条件分数网络 s θ ( x , σ ) s_\theta(\boldsymbol x, \sigma) s θ ( x , σ ) ∇ x log q σ ( x ∣ x ′ ) \nabla_x \log q_\sigma(\boldsymbol x|\boldsymbol x') ∇ x log q σ ( x ∣ x ′ ) p data ( x ′ ) p_{\text{data}}(\boldsymbol x') p data ( x ′ ) q σ ( x ∣ x ′ ) q_\sigma(\boldsymbol x|\boldsymbol x') q σ ( x ∣ x ′ )
J ( θ ; σ ) = 1 2 E x ′ ∼ p data ( x ′ ) E x ∼ q σ ( x ∣ x ′ ) ∥ s θ ( x , σ ) − ∇ x log q σ ( x ∣ x ′ ) ∥ 2 = 1 2 E x ′ ∼ p data ( x ′ ) E x ∼ N ( x ∣ x ′ , σ 2 I ) ∥ s θ ( x , σ ) + x − x ′ σ 2 ∥ 2 \begin{aligned}
J(\theta; \sigma) &= \frac{1}{2} \mathbb{E}_{\boldsymbol x' \sim p_{\text{data}}(\boldsymbol x')} \mathbb{E}_{\boldsymbol x \sim q_\sigma(\boldsymbol x|\boldsymbol x')} \left\| s_\theta(\boldsymbol x, \sigma) - \nabla_x \log q_\sigma(\boldsymbol x|\boldsymbol x') \right\|^2 \\
&= \frac{1}{2} \mathbb{E}_{\boldsymbol x' \sim p_{\text{data}}(\boldsymbol x')} \mathbb{E}_{\boldsymbol x \sim \mathcal{N}(\boldsymbol x | \boldsymbol x', \sigma^2 \boldsymbol I)} \left\| s_\theta(\boldsymbol x, \sigma) + \frac{\boldsymbol x - \boldsymbol x'}{\sigma^2} \right\|^2
\end{aligned}
J ( θ ; σ ) = 2 1 E x ′ ∼ p data ( x ′ ) E x ∼ q σ ( x ∣ x ′ ) ∥ s θ ( x , σ ) − ∇ x log q σ ( x ∣ x ′ ) ∥ 2 = 2 1 E x ′ ∼ p data ( x ′ ) E x ∼ N ( x ∣ x ′ , σ 2 I ) ∥ ∥ ∥ ∥ ∥ s θ ( x , σ ) + σ 2 x − x ′ ∥ ∥ ∥ ∥ ∥ 2
这个目标函数的好处在于,真实的条件分数 ∇ x log q σ ( x ∣ x ′ ) \nabla_x \log q_\sigma(\boldsymbol x|\boldsymbol x') ∇ x log q σ ( x ∣ x ′ ) − x − x ′ σ 2 -\frac{\boldsymbol x - \boldsymbol x'}{\sigma^2} − σ 2 x − x ′ n = x − x ′ \boldsymbol n = \boldsymbol x - \boldsymbol x' n = x − x ′ x \boldsymbol x x σ \sigma σ x ′ \boldsymbol x' x ′
单一噪声水平 σ \sigma σ σ \sigma σ σ \sigma σ { σ 1 > σ 2 > ⋯ > σ L } \{\sigma_1 > \sigma_2 > \dots > \sigma_L\} { σ 1 > σ 2 > ⋯ > σ L } σ 1 \sigma_1 σ 1 σ L \sigma_L σ L
模型 s θ ( x , σ i ) s_\theta(\boldsymbol x, \sigma_i) s θ ( x , σ i )
L ( θ ; { σ i } i = 1 L ) = 1 L ∑ i = 1 L λ ( σ i ) J ( θ ; σ i ) \mathcal{L}(\theta; \{\sigma_i\}_{i=1}^L) = \frac{1}{L} \sum_{i=1}^L \lambda(\sigma_i) J(\theta; \sigma_i)
L ( θ ; { σ i } i = 1 L ) = L 1 i = 1 ∑ L λ ( σ i ) J ( θ ; σ i )
权重因子 λ ( σ i ) \lambda(\sigma_i) λ ( σ i ) λ ( σ i ) = σ i 2 \lambda(\sigma_i) = \sigma_i^2 λ ( σ i ) = σ i 2 1 σ 2 \frac{1}{\sigma^2} σ 2 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def anneal_dsm_score_estimation (scorenet, samples, labels, sigmas, anneal_power=2. ):0 ], *([1 ] * len (samples.shape[1 :])))1 / (used_sigmas ** 2 ) * (perturbed_samples - samples)0 ], -1 ) 0 ], -1 ) 1 / 2. * ((scores - target) ** 2 ).sum (dim=-1 ) * used_sigmas.squeeze() ** anneal_powerreturn loss.mean(dim=0 )
这部分代码实现了退火朗之万动力学采样算法,即在不同噪声水平下逐步进行朗之万采样,噪声水平逐渐降低。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def anneal_Langevin_dynamics (self, x_mod, scorenet, sigmas, n_steps_each=100 , step_lr=0.00002 ):with torch.no_grad():for c, sigma in tqdm.tqdm(enumerate (sigmas), total=len (sigmas), desc='annealed Langevin dynamics sampling' ):0 ], device=x_mod.device) * c1 ]) ** 2 for s in range (n_steps_each):0.0 , 1.0 ).to('cpu' )) 2 )0.0 , 1.0 ).to('cpu' ))return images