intro
Hugging Face Transformers:源码入门指南
Hugging Face transformers 库对于任何使用当前最先进的自然语言处理 (NLP) 模型的人来说,都是一个极其强大的工具。虽然使用库的高级 API,如 pipeline 或 AutoModel.from_pretrained 非常直接,但深入研究源代码可以让你获得更深层次的理解,实现定制化,并更有效地调试问题
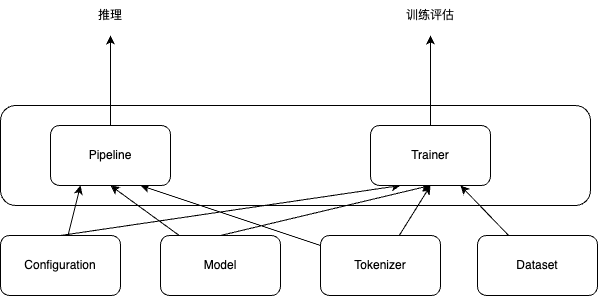
本指南将依据这张图的逻辑,从核心组件 (Core Components) 出发,再到支撑推理 (Inference) 和训练/评估 (Training/Evaluation) 工作流的高层抽象 (High-Level Abstractions),带你一步步探索 transformers 的源代码
核心组件 (Core Components)
配置 (Configuration)
模型的结构等信息的配置文件,基类为:src/transformers/configuration_utils.py (PretrainedConfig),每个模型的具体模型配置为: src/transformers/models/<model_name>/configuration_<model_name>.py (例如 BertConfig in models/bert/configuration_bert.py)
即每个模型架构都有一个对应的 *Config 类,继承自 PretrainedConfig。当你加载模型时,库会先加载 config.json 文件来实例化这个配置对象
分词器 (Tokenizer)
分词器的基类位于 src/transformers/tokenization_utils_base.py 中,分别是 PreTrainedTokenizer 和 PreTrainedTokenizerFast。而针对特定模型的分词器实现则存放在 src/transformers/models/<model_name>/tokenization_<model_name>.py (以及对应的 _fast.py 版本)目录下。值得一提的是,Transformers 库为了追求极致的性能,大量使用了由 Rust 语言实现的 Hugging Face tokenizers 库作为底层依赖。通常情况下,PreTrainedTokenizerFast 由于直接调用了 Rust 实现,因此在速度上往往更胜一筹。要让分词器正常工作,我们需要加载其对应的词汇表文件(例如 vocab.txt, merges.txt 等)以及配置文件 (tokenizer_config.json)
当分词器处理一段文本后,通常会生成以下几种数据:
input_ids:文本的数字编码,不用 token 而是使用 token id。这个 id 来源于分词器预先构建好的词汇表。比如,词汇表里 “hello” 的ID是123,那么input_ids里就会出现123来代表它attention_mask:当我们把多段文本一起送给模型处理时,为了让它们的长度一样,通常会用特殊符号(padding)把短的文本补齐。attention_mask就是用来告诉模型哪些位置是原始文本的token(用1表示),哪些是后来填充的(用0表示)。这样模型在计算注意力的时候就不会被填充的部分干扰token_type_ids:主要用在处理有多个输入段落的任务中,比如回答问题或者判断两个句子是不是相关。它用来标记每个 token 属于哪个段落。例如,在问答场景里,问题的 token 可能被标记为 0,答案上下文的 token 可能被标记为1。如果是只有一段文本的任务,那token_type_ids通常就是一串 0
模型 (Model)
这是 Transformers 库中实现神经网络核心逻辑的部分,包含了模型的所有层 (layers) 和计算逻辑 (computation logic)。模型架构的基类位于 src/transformers/modeling_utils.py 中的 PreTrainedModel(是 nn.Module 的一个功能拓展类)。具体的模型实现则存放在 src/transformers/models/<model_name>/modeling_<model_name>.py 目录下,例如 BERT 模型的相关代码可以在 models/bert/modeling_bert.py 文件中找到 BertModel(基础模型)和 BertForSequenceClassification(序列分类模型)等
数据集 (Dataset)
这一部分主要负责为模型的训练和评估提供数据。虽然 Transformers 库本身对数据格式没有硬性要求,但它与 Hugging Face datasets 库有着非常紧密的集成,推荐使用该库来管理和加载数据集
数据整理器 (Data Collators) 的相关代码位于 src/transformers/data/data_collator.py。它的主要作用是将数据集中的多个样本组合成一个批次 (batch),并处理成模型能够直接接受的格式。例如,对于长度不一的文本序列,数据整理器会负责进行填充 (padding) 操作,确保同一个批次内的所有样本长度一致。
此外,src/transformers/trainer.py 文件中的 Trainer 类是 Transformers 库中用于模型训练和评估的高级接口,它期望接收符合特定接口的数据集对象,通常是 PyTorch 的 torch.utils.data.Dataset 或 Hugging Face datasets 库的 datasets.Dataset 对象。数据整理器会在 Trainer 内部被调用,用于在每个训练或评估步骤中生成模型所需的批次数据
example:以 Qwen2 为例:
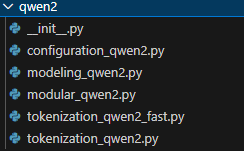
configuration_qwen2.py:包含Qwen2Config类,定义了qwen2模型的配置参数,例如模型层数、隐藏层大小、注意力机制的设置等等modeling_qwen2.py: 这是qwen2模型的核心架构实现文件,应该包含Qwen2Model类以及可能包含针对不同任务的派生类,例如Qwen2ForCausalLM(用于生成任务)或Qwen2ForSequenceClassification(用于分类任务),Qwen2ForQuestionAnswering等。这个文件定义了模型的神经网络层和计算逻辑modular_qwen2.py: 类似于之前的分析,这个文件可能包含qwen2模型中一些可复用的模块化组件,用于在modeling_qwen2.py中构建完整的模型架构,例如Qwen2Attention,Qwen2Attention等,有助于代码的组织和维护tokenization_qwen2.py: 这个文件应该包含了Qwen2Tokenizer类,它是qwen2模型的 Python 实现的 tokenizer。tokenization_qwen2_fast.py包含了Qwen2TokenizerFast类,这是使用 Rust 实现的快速 tokenizer 版本。_fast.py版本的 tokenizer 通常具有更高的性能,也更加常用
高层抽象与工作流 (High-Level Abstractions & Workflows)
这些是构建在核心组件之上的高级接口,简化了特定的任务流程。
推理工作流:pipline
Pipeline 组件旨在大幅简化使用预训练模型进行推理的过程。通过它,用户仅需寥寥几行代码,即可轻松地利用强大的预训练模型完成各种预测任务。Pipeline 的核心在于其内部集成了模型推理所需的关键要素,包括模型的配置 (Configuration)、模型本身 (Model) 以及负责将原始输入转化为模型可接受格式的分词器 (Tokenizer)
Pipeline 的工作流程主要分为三个步骤:
- 预处理 (Preprocess) 阶段:接收用户的原始输入,例如一段文本,并利用 Tokenizer 将其转化为模型所需的
input_ids和attention_mask等格式 - 前向传播 (Forward) 阶段:处理后的输入会被送入预训练的 Model 中进行计算
- 后处理 (Postprocess) 阶段,模型输出的原始结果(比如 logits)会被转换成更易于理解和使用的形式,例如文本分类的标签和分数,或者机器翻译生成的文本
深入了解 Pipeline 的实现细节,可以从 src/transformers/pipelines/__init__.py 文件中的 pipeline() 函数开始探索。这个函数是 Pipeline 的入口点,它会根据指定的 task 参数,自动找到并实例化对应的 Pipeline 子类。这些具体的任务实现位于 src/transformers/pipelines/<task_name>.py 目录下,例如文本分类任务的实现就在 text_classification.py 中,机器翻译任务则在 translation.py 中
训练/评估工作流: Trainer
Trainer 类是 Transformers 库中用于简化模型训练和评估流程的高级接口。它封装了标准的训练循环,并负责处理诸多复杂的细节,例如优化器的管理、学习率的调度、训练过程中的日志记录、模型的保存以及分布式训练的支持等
要使用 Trainer 需要提供 Model、包含训练配置信息的 TrainingArguments、用于训练和评估的 Dataset、Tokenizer,以及用于将数据集中的样本组合成批次并进行必要处理的 DataCollator 等。
Trainer 的工作流程涵盖了从数据准备到模型评估的整个过程。它会管理训练的轮数 (epoch) 和步数 (step),并利用 DataCollator 和 DataLoader 来准备模型所需的批次数据。在每个训练步骤中,Trainer 会执行模型的前向传播以计算损失 (loss),然后执行反向传播和优化器的更新步骤 (optimizer step)。此外,Trainer 还会负责学习率的调整。在训练结束后或训练过程中,Trainer 能够执行评估循环 (evaluation loop) 并计算各种评估指标 (metrics)。最后,Trainer 还会处理模型的保存、训练日志的记录,并支持与 Weights & Biases (W&B) 和 TensorBoard 等常用工具的集成…
Trainer 的内部机制,可以从 src/transformers/trainer.py 文件中的 Trainer 类的 __init__ 方法开始,了解其初始化过程。train() 方法是启动训练循环的关键,而 evaluate() 方法则负责执行评估。核心的训练逻辑位于 _inner_training_loop 方法中
它们如何连接:from_pretrained
无论是使用 Pipeline 还是 Trainer,加载预训练模型都非常方便。这背后的关键在于 from_pretrained 方法,它连接了 Configuration, Model, 和 Tokenizer 这些核心组件,使得 Pipeline 和 Trainer 能够轻松地使用预训练模型。
from_pretrained 它存在于 PreTrainedModel, PretrainedConfig, PreTrainedTokenizer 等基类及其子类中。它的主要任务就是从 Hugging Face Hub 的模型仓库或者本地缓存中,自动下载并加载预训练好的模型权重、配置文件以及分词器文件
让我们以一个常见的操作 AutoModel.from_pretrained("identifier") 为例,来看看 from_pretrained 是如何工作的:
- 首先,像
AutoModel这样的“Auto”类会根据您提供的identifier(例如模型名称)在 Hugging Face Hub 上查找对应的config.json文件 AutoModel会读取config.json中的model_type字段,这个字段指明了具体的模型类型。- 根据
model_type,AutoModel就能确定需要加载哪个具体的模型类,比如BertModel。 - 然后,
AutoModel会调用这个具体模型类(例如BertModel) 的from_pretrained方法。 - 在这个方法内部,会进行以下操作:
- 下载并将
config.json文件加载到对应的*Config对象中(例如BertConfig)。 - 根据加载的
Config对象实例化模型(例如创建一个BertModel(config)的实例)。 - 下载模型的权重文件 (
pytorch_model.bin或者.safetensors格式)。 - 将下载的权重加载到刚刚创建的模型实例中
- 下载并将