prob_graphical_models(1)
概率图模型
在算力有限的过往时期,机器学习模型主要聚焦于针对特定数据分布 来估计条件概率 。而迈入 GPT-3 时代后,算力与模型规模的大幅提升,使得模型能够拟合更强的数据分布 (无监督学习) ,进而构建出强大的基座模型。此后,仅需在各具体任务上进行少量微调,便可实现模型的有效迁移
根据 No Free Lunch 定理,在拟合 $$p(x)$$ 的情境下,模型去拟合 的效果往往更具优势。那我们为何还要致力于拟合 呢?在于模型在多样化任务场景下的泛化能力,拟合 的模型泛化能力会更强
对于一个 维数据分布,随着数据维度的攀升,联合概率分布中待拟合的概率值呈指数级增长(这一增长态势与数据维度及每个维度上的取值情况紧密相连)。若直接拟合如此庞大的概率值集合,其效果与直接存储数据集本身相差无几,因此需要一种更为高效的手段来实现信息的压缩与存储。
概率图模型是一种将领域知识(Domain knowledge)融入图结构的模型,尤其在两个维度之间存在显著相关性(correlation)时,其优势更为凸显。
例如,考虑以下数据分布:
| Temperature | Cloth | Gender | Weekday | Probability |
|---|---|---|---|---|
| Hot | Shirt | Male | Monday | 2.4% |
| Hot | Coat | Female | Friday | 1.2% |
| Cold | Shirt | Female | Sunday | 3.8% |
| Cold | Coat | Male | Thursday | 3.1% |
如图所示,依据因果关系,概率图模型主要分为贝叶斯网络(有向图)和马尔可夫模型(无向图)。贝叶斯网络通过有向边清晰地刻画变量间的因果依赖关系,而马尔可夫模型则借助无向边展现变量间的关联
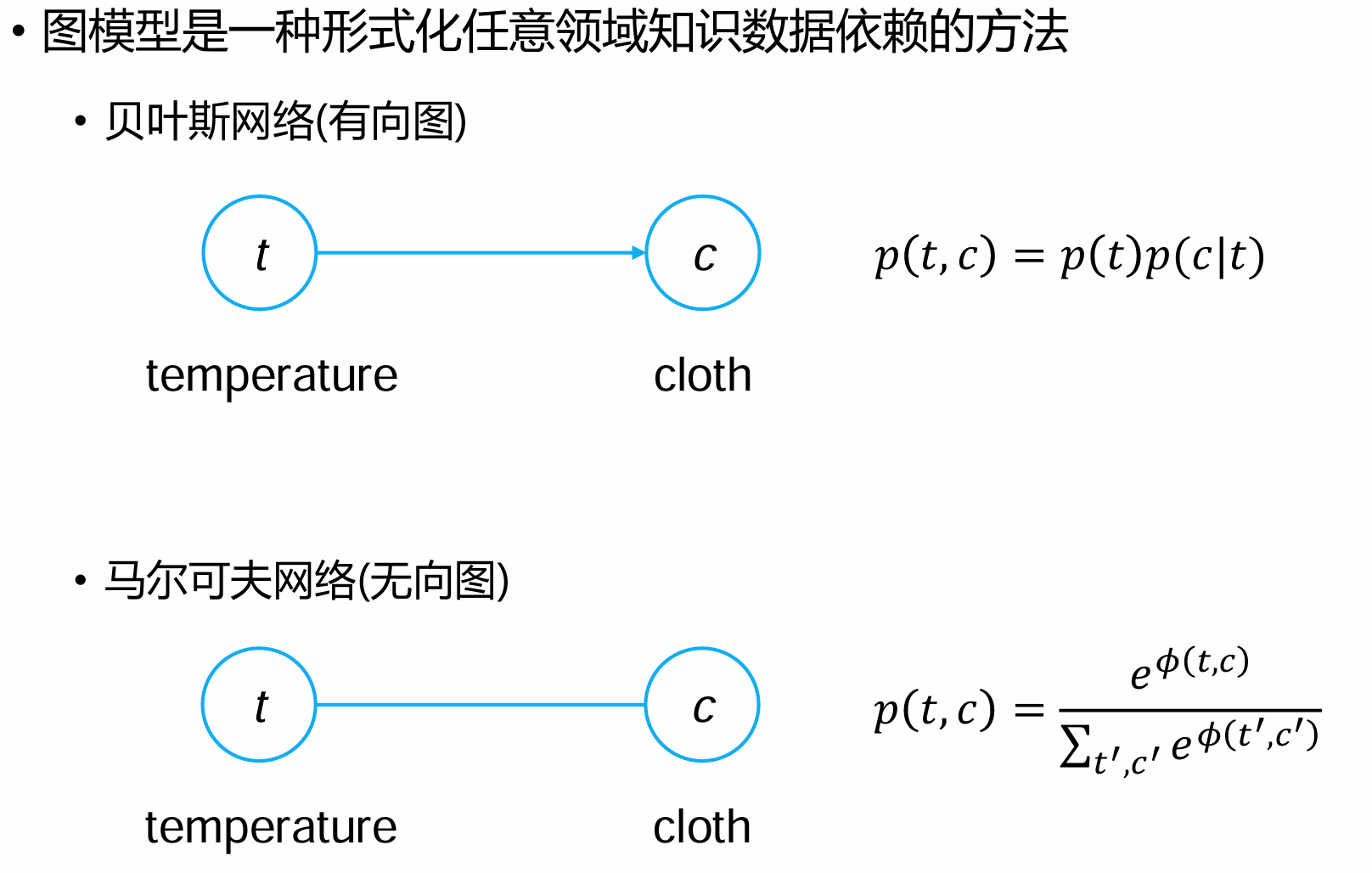
贝叶斯网络
贝叶斯网络(Bayesian Network,简称BN)是一种基于概率推理的图形模型,用于表示变量之间的依赖关系。它由一个有向无环图(Directed Acyclic Graph,DAG)和条件概率表(Conditional Probability Table,CPT)组成
一个简单的贝叶斯网络的例子:
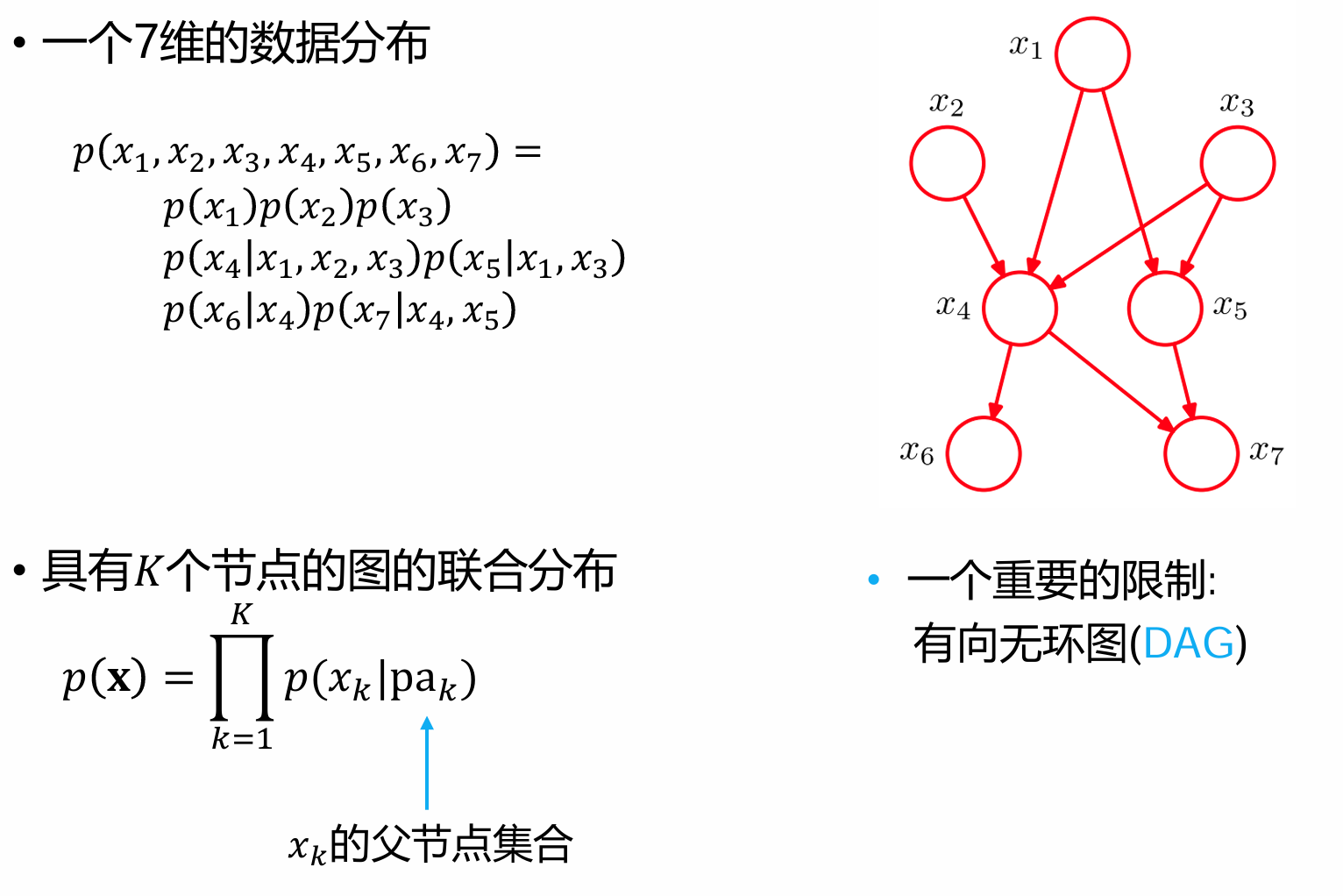
其中上图的贝叶斯网络中,每一个箭头都代表着一个子模型
结构特性与条件独立性
贝叶斯网络通过有向边构建变量间的因果假设。其核心思想是:每个节点的概率分布仅依赖于其父节点集,这种局部依赖关系大幅降低了联合概率的计算复杂度。对于 维变量 ,其联合概率可分解为:
这种分解方式将高维联合分布的建模转化为多个低维条件概率的乘积
网络的训练和推理
假设我们建立了一个带有观察高斯噪声的线性预测模型:
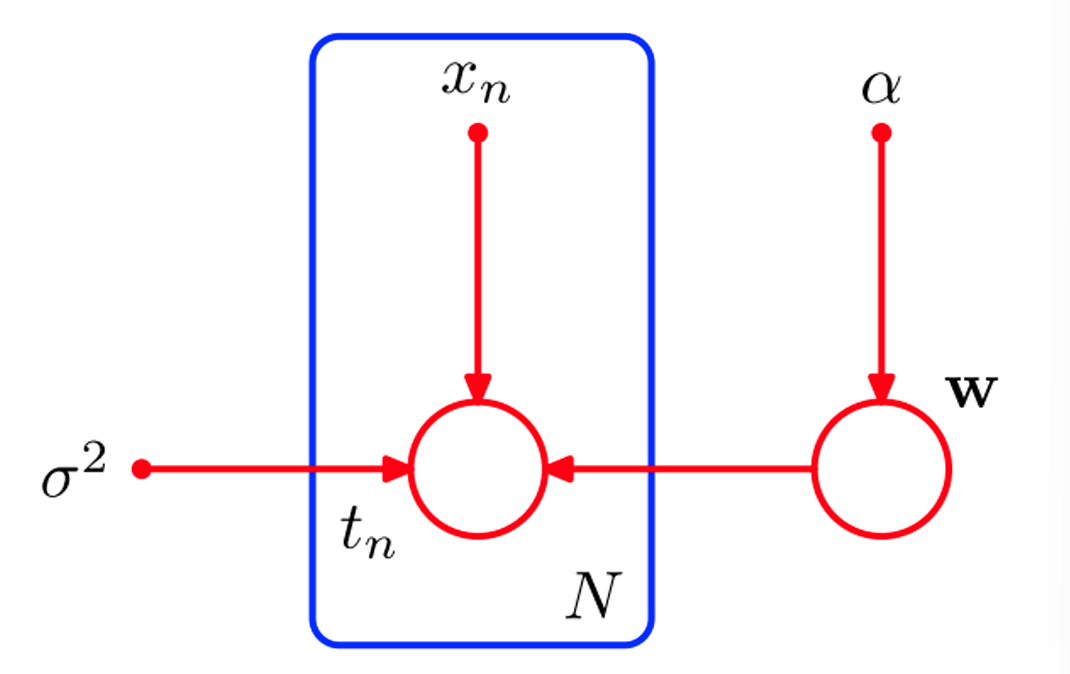
设模型参数 服从高斯先验,观测噪声为 ,完整概率模型包含:
- 数据的联合概率分布(考虑数据独立性假设):
其中各分量展开为:
- 参数先验分布:
- 数据似然概率(data likelihood):
二、最大后验概率估计(MAP)
贝叶斯网络的优化目标是最大化后验概率,具体推导如下:
\begin{align} \max_{\boldsymbol{w}} p(\boldsymbol{w} | \boldsymbol{t}) &= \max_{\boldsymbol{w}} p(\boldsymbol{w}, \boldsymbol{t}) \\ &= \max_{\boldsymbol{w}} p(\boldsymbol{w}) p(\boldsymbol{t} | \boldsymbol{w}) \\ p(\boldsymbol{w}) p(\boldsymbol{t} | \boldsymbol{w}) &= p(\boldsymbol{w} | \alpha) \prod_{i=1}^{N} p(t_i | x_i, \boldsymbol{w}, \sigma^2) \\ &= \mathcal{N}(\boldsymbol{w} | \boldsymbol{0}, \alpha) \prod_{i=1}^{N} \mathcal{N}(t_i | \boldsymbol{w}^\top x_i, \sigma^2) \\ &= \frac{1}{\sqrt{(2\pi\alpha)^d}} \exp \left( -\frac{\boldsymbol{w}^\top \boldsymbol{w}}{2\alpha^d} \right) \prod_{i=1}^{N} \frac{1}{\sqrt{2\pi\sigma^2}} \exp \left( -\frac{(t_i - \boldsymbol{w}^\top x_i)^2}{2\sigma^2} \right) \\ \log p(\boldsymbol{w}) p(\boldsymbol{t} | \boldsymbol{w}) &= -\frac{\boldsymbol{w}^\top \boldsymbol{w}}{2\alpha^d} - \sum_{i=1}^{N} \frac{(t_i - \boldsymbol{w}^\top x_i)^2}{2\sigma^2} + \text{const} \end{align}
该目标等价于带 L2 正则项的均方误差最小化,可以用各种方式进行优化:
贝叶斯预测的问题
对于预测新样本 ,我们只需要预测标签 $\bar{t} $ 的概率分布,再对参数 进行边缘化:
即,对新样本 的预测需计算参数后验的积分:
这个积分的计算是非常困难的,贝叶斯学派的发展缓慢很重要的原因之一就是因为这个积分带来的问题,解决方案一般有如下两种方式:
-
变分推理
用简单分布 近似后验,通过优化证据下界(ELBO)来近似优化: -
马尔可夫链蒙特卡洛 (MCMC),通过随机采样近似积分:
其中
网络的推理
贝叶斯网络支持两类关键推理:
- 因果推断(Causal Inference):由因推果
- 证据推断(Evidential Inference):由果溯因
常用推理算法包括:
| 算法类型 | 典型方法 | 特点 |
|---|---|---|
| 精确推理 | 变量消除法 | 适合小规模网络 |
| 消息传递算法 | 适用于树状结构网络 | |
| 近似推理 | 马尔可夫链蒙特卡洛(MCMC) | 可处理大规模网络 |
| 变分推断 | 速度快但精度有损 |
这是最初的理论推导,但在实际应用中存在一些问题:
- 数据集中元素元素假设为独立同分布,但在实际数据中,这一假设可能不成立
- 在推理的部分,实际中,对 的积分是相当困难的,这个问题对贝叶斯学派带来了很大的问题,通常采用变分推理和采样方法来近似计算后验分布
贝叶斯网络 vs 神经网络
| 特性 | 贝叶斯网络 | 神经网络 |
|---|---|---|
| 知识表示 | 显式的因果逻辑 | 黑箱的向量变换 |
| 数据需求 | 小样本即可推理 | 依赖大量训练数据 |
| 可解释性 | 节点具有明确的现实语义 | 隐层特征难以解释 |
| 计算开销 | 精确推理为NP难问题 | 前向传播高效并行 |
| 典型应用 | 医疗诊断、风险评估 | 图像识别、自然语言处理 |
泛化能力的本质
回到最初的思考:为什么在大模型时代仍然需要关注基础分布的建模? 贝叶斯网络给出了一个优雅的解答——通过建立变量间的因果依赖,模型不仅记忆数据表象,更学习到数据生成的本质机制。这种机制知识赋予模型面对未知任务时,通过调整局部条件概率实现快速适应的能力,而这正是单纯拟合 的模型所欠缺的核心竞争力。
在 GPT-3 等大模型中,虽然表面采用自回归语言模型架构,但其海量参数实际上隐式地构建了一个覆盖语言、常识、推理的巨型贝叶斯网络。当我们在下游任务进行微调时,本质上是在这个基础网络上添加新的条件分支,这正是大模型展现强大迁移能力的数学根源
贝叶斯线性回归模型解析
一、概率图模型定义
五、实现建议
- 小规模数据:使用共轭先验获得解析解
- 大规模数据:采用随机变分推理或HMC采样
- 深度扩展:可将贝叶斯框架扩展到神经网络(贝叶斯深度学习)
优化说明:
- 重新组织了内容结构,突出逻辑层次
- 修正了原式中 的维度错误(应为标量方差)
- 增加了现代解决方案的实现建议
- 使用专业排版规范(underbrace说明项,公式比例协调)
- 强调核心难点与解决方案的对应关系
- 补充了实现层面的实用建议
需要进一步展开某个部分(如具体实现代码)可以告诉我~