拉格朗日凸优化
一般而言,非线性规划的问题有如下形式:
PA:⎩⎪⎪⎨⎪⎪⎧minxsubject to:f(x)hi(x)gj(x)=0, i=1,2,⋯,m≤0, j=1,2,⋯,l
其中自变量 x=(x1,x2,…,xn)T∈Rn,f(x) 为目标函数,hi(x)=0(i=1,2,…,m) 和 gj(x)≥0(j=1,2,⋯,l) 为约束条件。
由于 maxf(x)=−min(−f(x)),当需使目标函数极大化时只需使其负值极小化即
可。因而仅考虑目标函数极小化,这无损于一般性。若某约束条件是 ≤ 不等式时,仅需在约束的两端同时取负号即可,因此这也无损一般性
无约束优化问题
定义拉格朗日函数 L(x,λ,μ) 如下:
L(x,λ,μ)=f(x)+λjgj(x)
则原优化问题等价于如下的优化问题:
PL:{minxmaxλSubject to:L(x,λ,μ)=f(x)+∑i=1mλigi(x)+∑j=1nμjhj(x)λi≥0i=1,2,…,m
我们接下来说明优化问题 PL 和优化问题 PA 等价:
-
若 x 在 PA 的可行域之内,则对于 maxλ,μL(x,λ,μ)=f(x)+∑i=1mλigi(x) 这个优化问题,x 为常值,后一项 ∑i=1mλigi(x)≤0,因此 maxλ,μL(x,λ,μ)=f(x),经过外层的 min 之后就等价于原问题
-
若 x 在 PA 的可行域之外,则至少存在一个存在 i 使 gi(x)>0,代表着若取 λi→+∞,其余 λj 元素为零,则 maxλ,μL(x,λ,μ)=f(x)+∑i=1mλigi(x) 这个优化问题的结果是 +∞,经过外层的 min 后该项是一定被去掉的,即 PL 等价于 PA
对偶优化问题:
化为对偶问题的原因是,无论原问题是什么优化问题,对偶问题都是凸优化问题
PD:{maxλminxSubject to:L(x,λ,μ)=f(x)+∑i=1mλigi(x)+∑j=1nμjhj(x)λi≥0i=1,2,…,n
下面推导原问题的最优解和对偶优化问题的最优解之间的关系,设原问题的最优解为 d∗,对偶问题的最优解为 p∗:
d∗=x∈Dminf(x)≥xminf(x)d∗=λmaxx∈Dminf(x)≥λmaxxminf(x)=p∗
这是一般化的原问题最优解和对偶问题最优解之间的关系,如果满足 Slater 条件和原问题是凸优化问题,则可以证明原问题和对偶问题最优解相同
步骤2:KKT条件
满足以下KKT条件时,点 x∗ 为最优解:
hi(x∗)=0, i=1,2,...,mgj(x∗)≥0, j=1,2,...,n
∇xL(x∗,λ∗,μ∗)=0μj≥0, j=1,2,...,l
λjgj(x∗)=0, j=1,2,...,l
在理解上唯一值得注意的就是互补松弛条件了,它的几何含义如下:
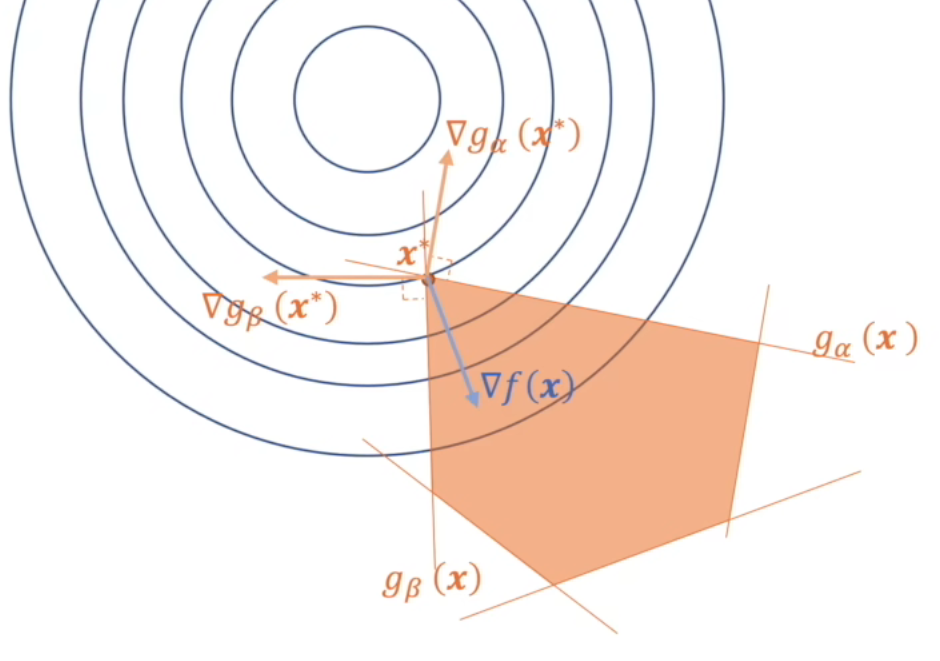
- 其中蓝色线为原问题 f(x) 的等高线,gi(x) 所围成的区域即为该优化问题的可行域,我们可以观察到不是所有的 gi(x)≤0 都是对 x∗ 发挥作用的,对于限制 x∗ 的条件满足 gi(x)=0,而对于 gi(x)<0,由梯度条件 ∇λigi(x)=0,则可以推出互补松弛条件
通过上述步骤,我们可以利用拉格朗日乘子法求解带有多元约束的优化问题。具体来说,我们通过构造拉格朗日函数并满足KKT条件来找到最优解。
对 $ \boldsymbol{x} $ 的偏导数
首先,计算 $ L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\mu}) $ 关于 $ \boldsymbol{x} $ 的偏导数:
∇xL(x,λ,μ)=∇f(x)+i=1∑mλi∇hi(x)+j=1∑lμj∇gj(x)
将这个表达式设为零,得到:
∇f(x∗)+i=1∑mλi∗∇hi(x∗)+j=1∑lμj∗∇gj(x∗)=0
这意味着对于每个分量 $ k $:
∂xk∂L(x∗,λ∗,μ∗)=∂xk∂f(x∗)+i=1∑mλi∗∂xk∂hi(x∗)+j=1∑lμj∗∂xk∂gj(x∗)=0
对 $ \boldsymbol{\lambda} $ 的偏导数
接下来,计算 $ L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\mu}) $ 关于 $ \boldsymbol{\lambda} $ 的偏导数:
∂λi∂L(x,λ,μ)=hi(x)
将这个表达式设为零,得到原始可行性条件:
hi(x∗)=0, i=1,2,...,m
对 $ \boldsymbol{\mu} $ 的偏导数
最后,计算 $ L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\mu}) $ 关于 $ \boldsymbol{\mu} $ 的偏导数:
∂μj∂L(x,λ,μ)=gj(x)
由于 $ \mu_j \geq 0 $ 并且 $ g_j(\boldsymbol{x}) \leq 0 $(因为 $ g_j(\boldsymbol{x}) \geq 0 $),我们有互补松弛性条件:
μjgj(x∗)=0, j=1,2,...,l
进一步理解和可视化
理解拉格朗日对偶条件:
我们先考虑一种特殊情况:在 SVM 中,拉格朗日函数为:
L(w,β)=f(w)+βh(w)
则最优解的满足的条件为:
∂w∂L(w,β)=∂w∂f(w)+β∂β∂h(w,β)=0
它的几何意义为:让 f(w) 的等值曲面与约束条件 h(w)=0 这条曲线相切,即 ∂w∂f(w) 和 ∂w∂h(w) 两梯度方向共线,对于有约束问题,它的可行域为 h(w)=0,对可行域上的点 x0 进行微扰,假设在 x0 处存在一个方向和 ∂w∂f(w) 方向夹角为锐角,且和 ∂w∂h(w) 方向垂直,代表着我们可以沿着这个方向前进时可以让 f(w) 减小的同时让 h(w) 的值不变,即满足约束条件,因此极小值点处应满足的约束为 ∂w∂f(w) 和 ∂w∂h(w) 两梯度方向共线
- 注意由于这个条件是充分条件,我们也可能解出极大值点
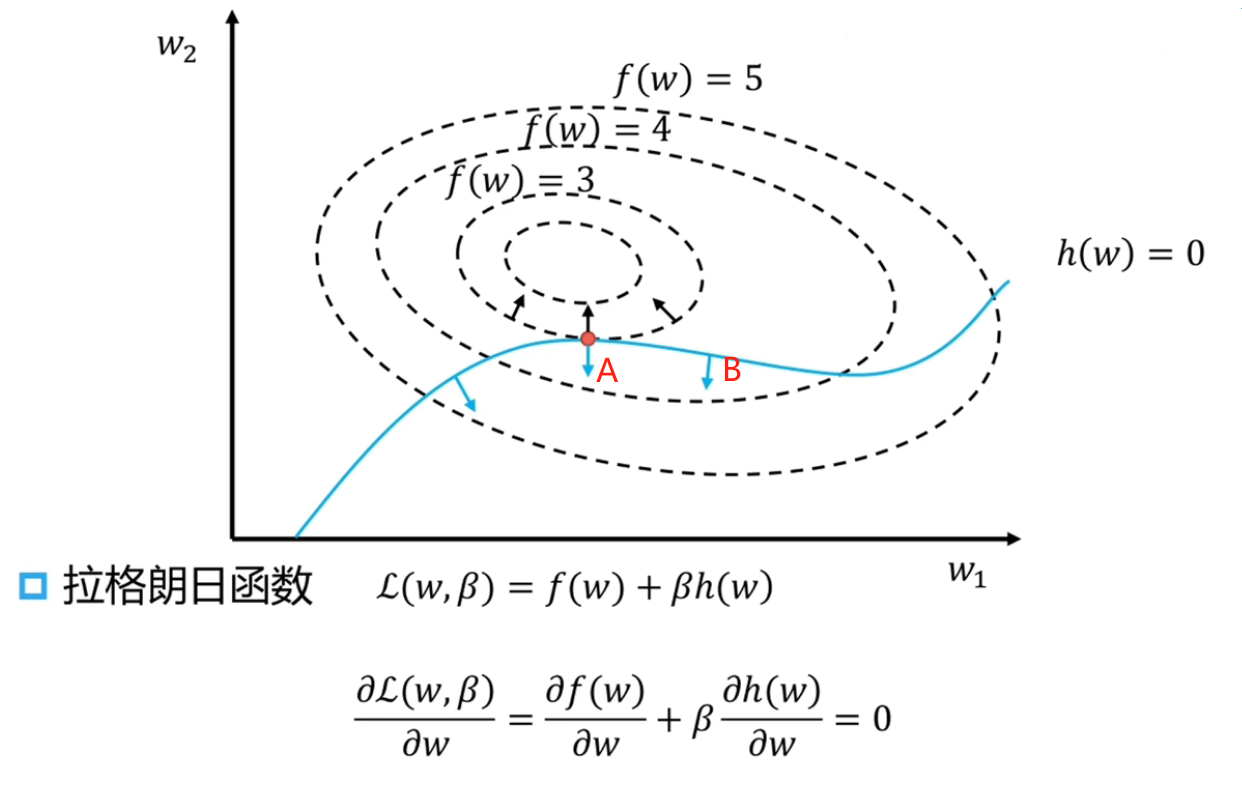
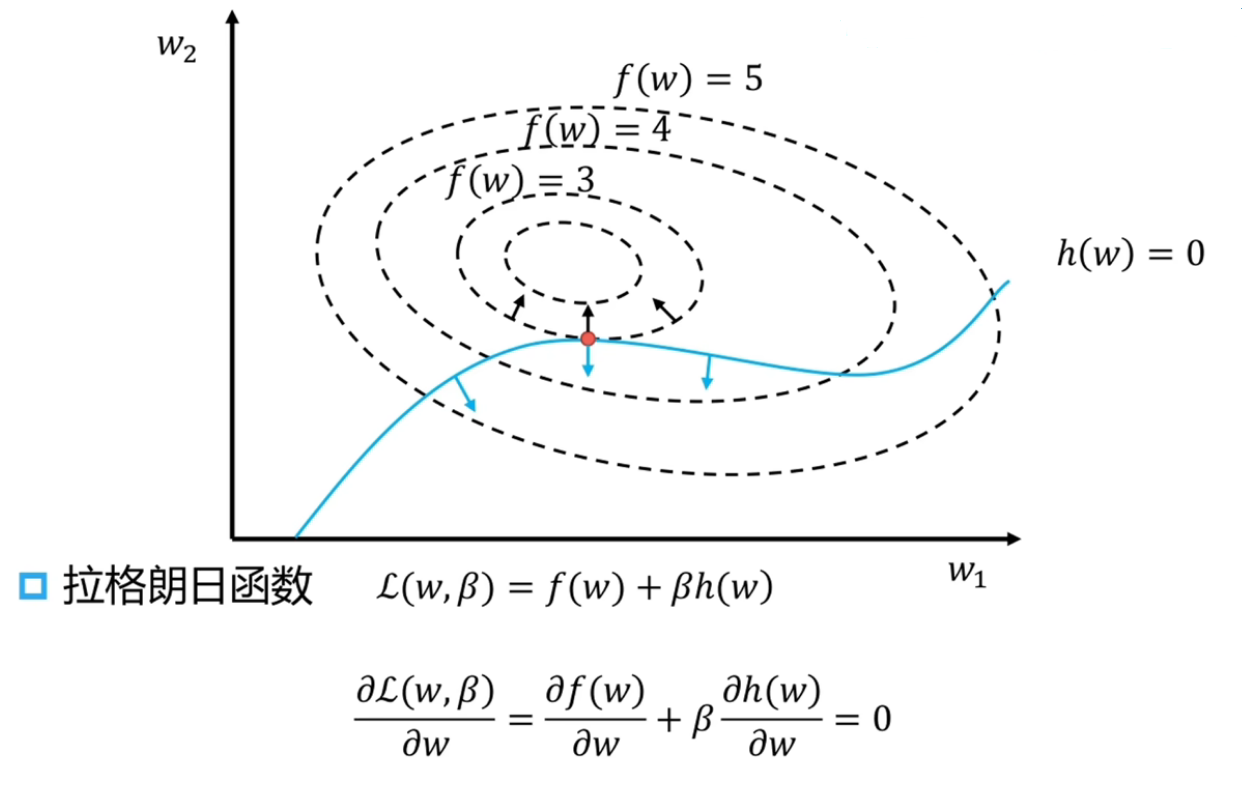
我们再去理解 Lagrange 函数的构造过程,记下面方向 A 为 h(w) 增大的方向,那么构造的 Lagrange 函数 L(w,β)=f(w)+βh(w) 沿着方向 A 就会让它的两个分量 f(w) 和 h(w) 同时增大,因此从这个角度来看,≥ 和 h(w) 的增大方向是配对的(如果 h(w) 沿 A 的反方向增大,那这个极值问题本身是无意义或者 trivial 的,只能让拉格朗日乘子小于零这个问题才有意义),我们如果要让优化问题 PA 到 PB 的 +βh(w) 这个操作没有用的话,就让它加的正值部分在 f(w) 的大值区域就行(非优解区域),这样就会迫使
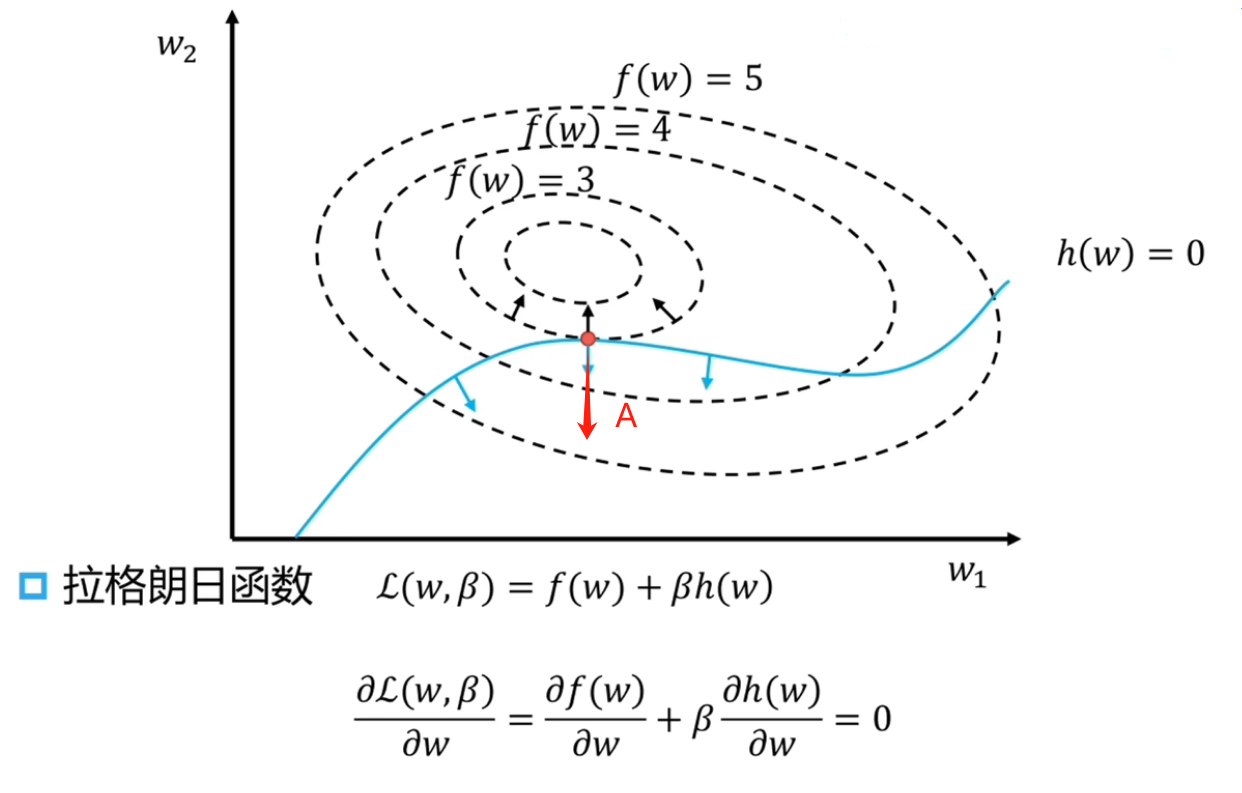
拉格朗日对偶可视化
设原问题可行域为 D,原问题表述如下:
PA:⎩⎪⎪⎨⎪⎪⎧minxsubject to:f(x)hi(x)gj(x)=0, i=1,2,⋯,m≤0, j=1,2,⋯,l
对偶问题:
PD:{maxλminxSubject to:L(x,λ,μ)=f(x)+∑i=1mλigi(x)+∑j=1nμjhj(x)λi≥0i=1,2,…,n
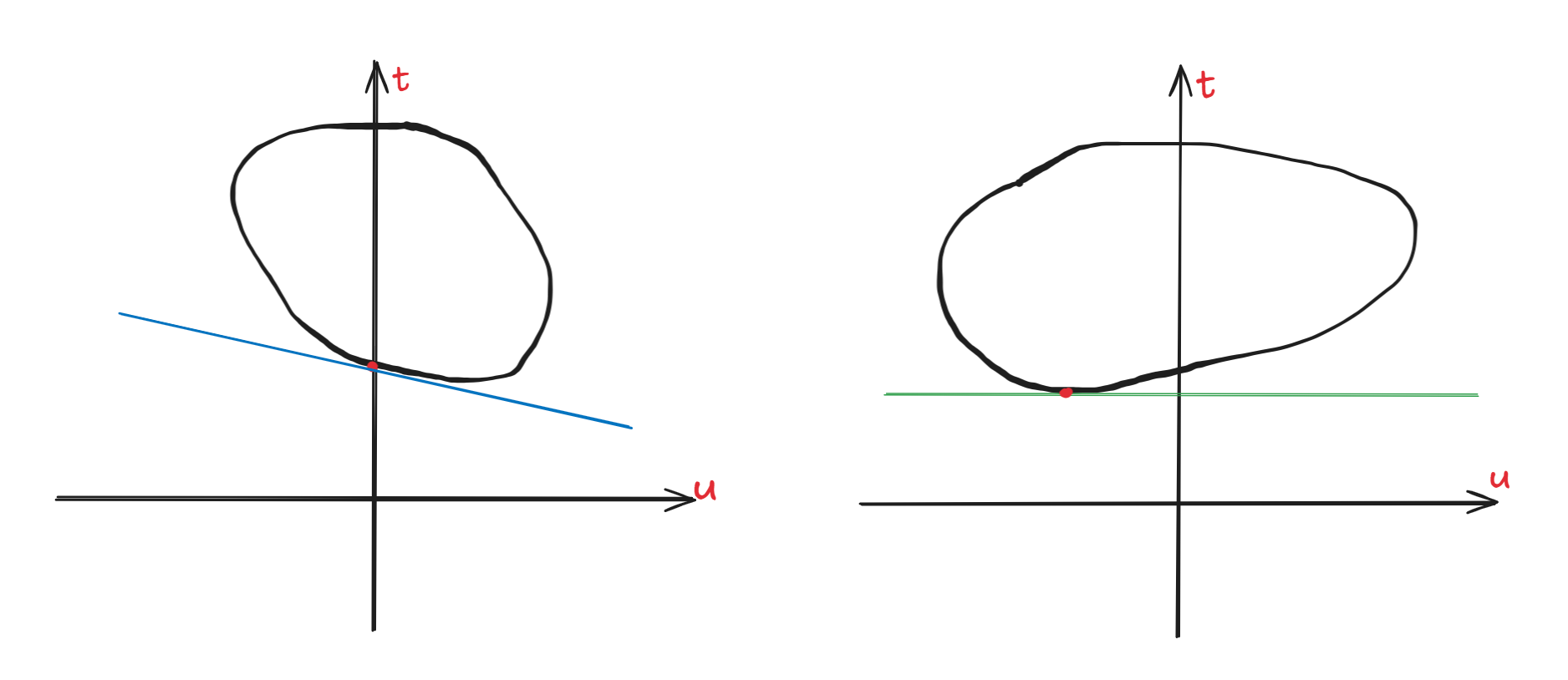
将拉格朗日函数写为:L(x,λ,μ)=t+ λTu ,为了可视化分析我们将 u 视为标量,即原问题和对偶问题的可行域为:
\begin{align}
&G_1 = \{(t, \boldsymbol u)| t=f(\boldsymbol x), u_i= g_i(\boldsymbol x), \boldsymbol x \in D\} \\
&G_2 = \{(t, \boldsymbol u)| t=f(\boldsymbol x), u_i= g_i(\boldsymbol x), \boldsymbol x \in \mathbb{R}^n \}
\end{align}
- 这里可以看出 G1 是 G2 的子集,它们的核心区别在于 x∈D,也就是 u≤0,在后续的可视化的过程中我们可以看出区别
则原问题和对偶问题再改写形式:
Original problem: xmin{t∣(t,u)∈G1}Dual problem: λmaxxmin{t+ λTu∣(t,u)∈G2}
可视化出 (t,u) 坐标系:
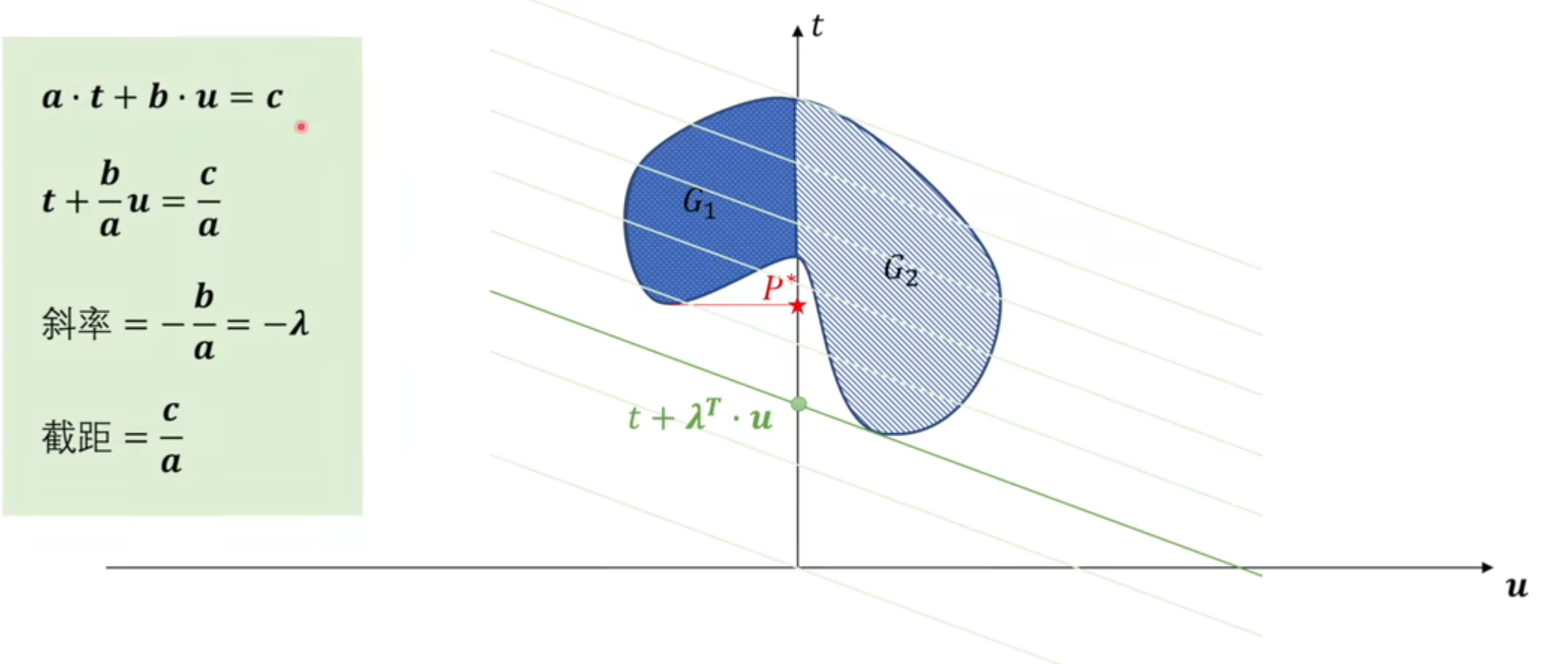
- 对于原问题的目标就是在 G1 中寻找一个 t 值最小的点,投影到 t 轴上的值我们记为 P∗,即为原问题的最优解
- 对于对偶问题
- 对于内层的 min 优化:外层求 max 的过程中的 λ 为斜率,可以绘制一系列 t+λTu 的等值线,目标就是在 G2 中寻找对应最小等值线的点,即等值线与 G2 相切处的值
- 对于外层的取最大值:求能够与可行域相切的等值线的斜率最大值,那么对于图中所示的最大值即为同时相切于两点的直线,则对于对偶问题的最终最优解就是该直线与 t 轴的交点
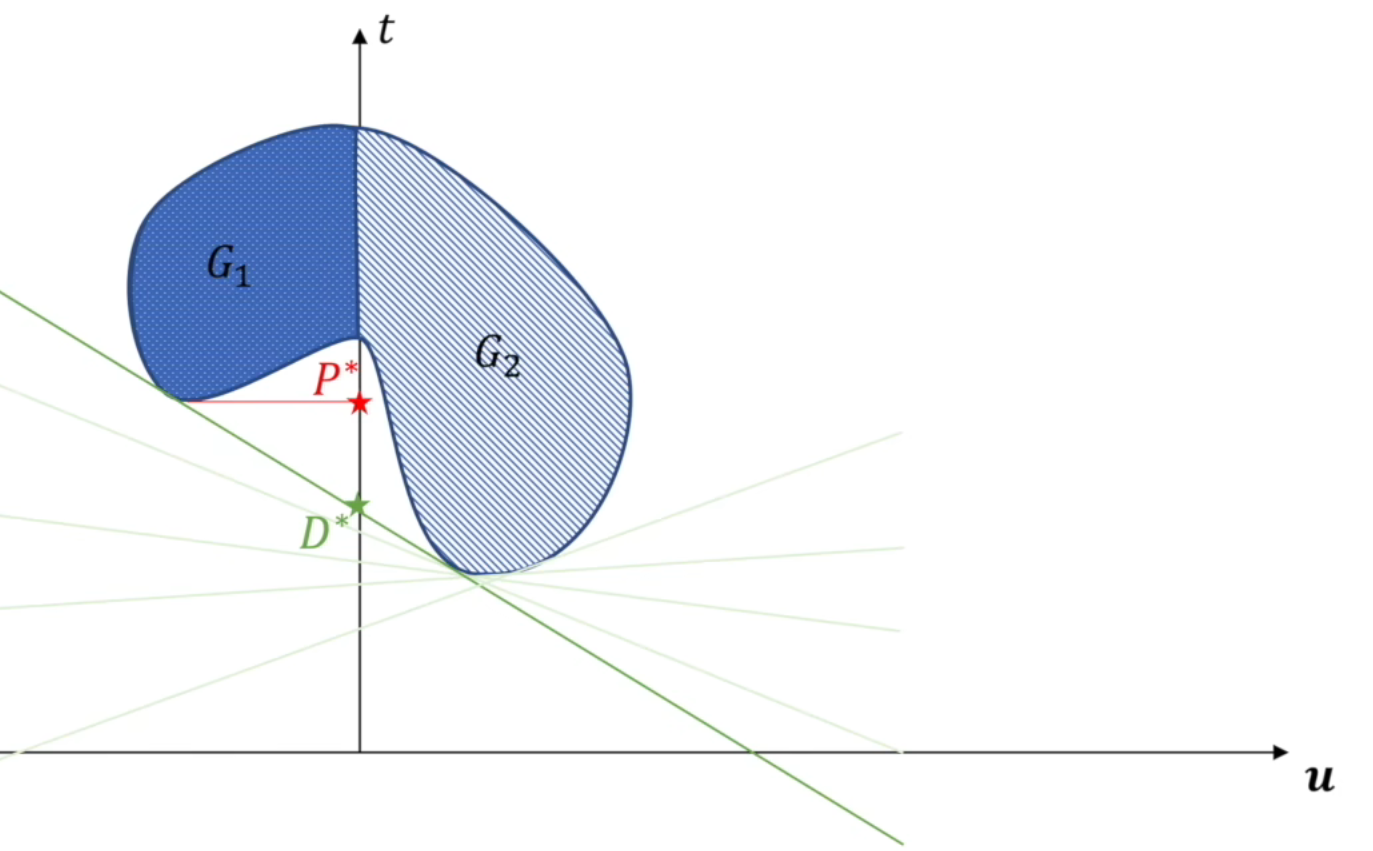
这张图也解释了弱对偶性,同时我们也可以用几何意义来解释 KKT 条件中的互补松弛条件:
在下面两种情况中,P∗ 和 Q∗ 都是相同的,从下面这张图来看,对于绝大多数的凸优化问题,强对偶定理都成立,但是数学上仍然能够举例出特殊情况让他不成立,这就是 Slater 条件