数据降维
数据降维是处理高维数据时常用的技术,它旨在减少数据集的特征数量同时尽可能保留原始数据的关键信息。常见的降维算法可以分为线性方法和非线性方法两大类,常见的线性降维算法有 PCA(Principal Component Analysis 无监督),LDA(Linear Discriminant Analysis 有监督)。非线性降维算法有 SNE(t-distributed Stochastic Neighbor Embedding 主要用于数据可视化),autoencoder 等
这里指出数据降维并非一个特殊的概念。事实上,当我们将数据降维到单一维度时,这一过程实际上与寻找一个用于分类的拟合模型相类似。因此,从这个角度来看,数据降维可以被理解为构建一个简化模型的过程,该模型旨在捕捉数据的本质结构。
在本篇文章中我们主要介绍线性降维方法 LDA 与 PCA
LDA:Fisher线性判别
Fisher 线性判别的目标是在保证类内方差最小化的同时最大化类间方差,即找到一个投影方向,使得投影后的数据点能够最大程度地分开不同的类别。考虑怎么建模这个投影,我们现考虑讲数据从
设数据集为 D={x1,…,xn},其中每个数据点 xi=(xi1,xi2,…,xid)T。再设数据服从分布 xi∼x,i.i.d,且数据被分为 C 类,记作 D1,D2,…,DC。 我们的目标是找到一个投影向量 w,使得数据在该轴上的投影能够最大化类间分离度,同时最小化类内离散度。这可以通过优化 Fisher 准则函数来实现:
定义类均值和总均值 对于每一类 c,我们定义其类均值 μc 为:
μc=Nc1xi∈Dc∑xi,
其中 Nc 是类别 c 中的数据点数量。 定义总均值 μ 为:
μ=N1i=1∑nxi,
其中 N=∑c=1CNc 是所有数据点的总数。
2. 构建类内散度矩阵和类间散度矩阵 类内散度矩阵(within-class scatter matrix)SW 定义为:
我们先以二分类为例,我们建模目标函数 J(w) 如下:我们考虑二分类问题,类别为 y=1 和 y=−1。设投影向量为 w,数据点 xi 在该方向上的投影为 si=wTxi。
J(w)=within class scatterbetween class scatter=Var[s∣y=1]+Var[s∣y=−1](E[s∣y=1]−E[s∣y=−1])2
下面进一步化简均值和方差:
E[s∣y=i]=E[wTx∣y=i]=wTμi(E[s∣y=1]−E[s∣y=−1])2=(wTμ1−wTμ−1)2=wT(μ1−μ−1)(μ1−μ−1)TwVar[s∣y=i]=E[(s−E[s∣y=i])]=E[(wTx−E[wTx∣y=i])2]=E[(wT(x−μi))2]=wTE[(x−μc)(x−μc)T]w=wTΣcw
其中 Σc 为类别 c 的协方差矩阵,则 J(w) 可化为:
J(w)=Var[s∣y=1]+Var[s∣y=−1](E[s∣y=1]−E[s∣y=−1])2=wTΣ1w+wTΣ−1wwT(μ1−μ−1)(μ1−μ−1)Tw
定义类间散度矩阵 SB,类内散度矩阵 Sw 为(每个组数据 SB,Sw 都是定值):
SB=(μ1−μ−1)(μ1−μ−1)TSw=Σ1+Σ−1
则优化问题进一步转化:
J(w)=wTSwwwTSBw
我们将 wTSww 固定,优化问题改为:
w=argwmaxwTSBwSubject to: wTSww=K
使用拉格朗日乘子法:
L(w,λ)=wTSBw+λ(K−wTSww)=wT(SB−λSw)w+λK∂w∂L(w,λ)=0T⇒2(SB−λSw)w=0⇒SBw=λSBw
我们不关心 w 的大小,我们只关系 w 的方向,问题是该如何用 w 的方向值去掉一个 w 让我们接触一个方向?
Sw−1SBw=λw⇒Sw−1(μ1−μ−1)(μ1−μ−1)Tw=λw⇒Sw−1(μ1−μ−1)a=λw⇒w=Sw−1(μ1−μ−1)
- 考虑到 SB 不可逆,因此我们对 Sw 取逆而非 SB(只有 Sw 可逆才能进行上面的推导)
- (μ1−μ−1)Tw=const 这一步挺有技巧性的,可以记一下
- 最后一步我们省去了 w 的模长,只关注了投影向量的方向
SW=c=1∑Cxi∈Dc∑(xi−μc)(xi−μc)T.
类间散度矩阵(between-class scatter matrix)SB 定义为:
SB=c=1∑CNc(μc−μ)(μc−μ)T
Fisher准则函数 Fisher准则函数 J(w) 定义为类间散度与类内散度的比例:
J(w)=wTSWwwTSBw
4. 最优化问题 为了最大化 Fisher 准则函数,我们需要解下列广义特征值问题:
SBw=λSWw,
其中 λ 是广义特征值,w 是对应的广义特征向量。 通过求解上述方程,我们可以找到最优的投影方向 w。在实际应用中,通常会将 SW 进行逆变换,然后将其转化为标准特征值问题进行求解:
(SW−1SB)w=λw.
最终,选择具有最大 λ 值的特征向量作为最优的投影向量 w,它对应于最大化 Fisher 准则函数的方向。
PCA:主成分分析
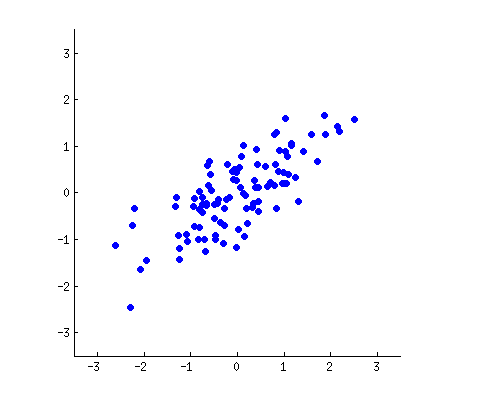
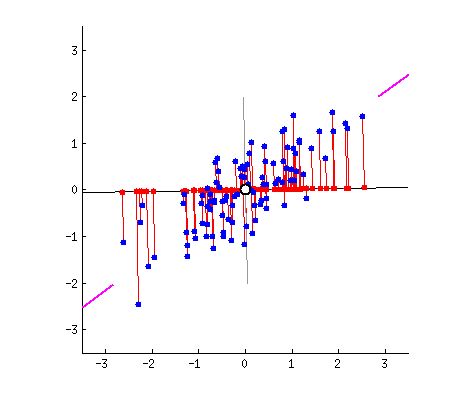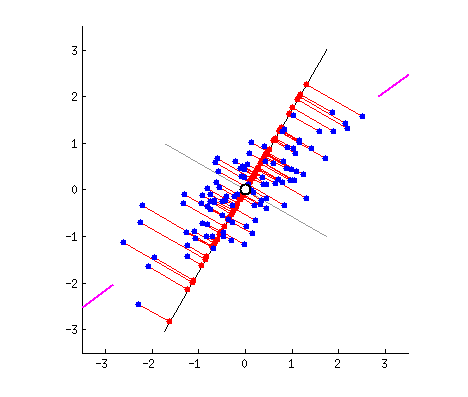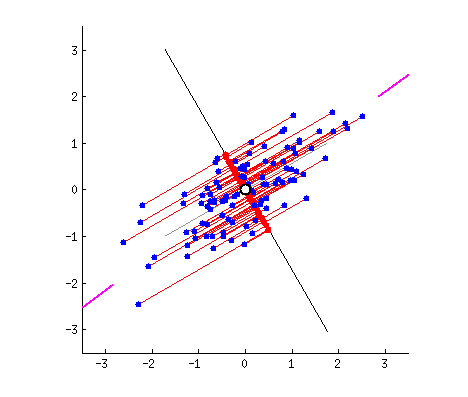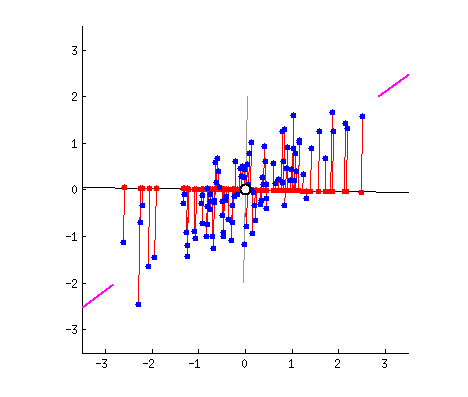
假设我们的数据分布如上图所示,我们想把数据的维度从二维降维到一维,我们尝试画一条线代表数据特征分布,那么我们可以感觉到“能将数据尽可能离散地分布到一个轴上,那个轴就是好的投影轴”,下面我们尝试去建模这个过程:
借助 logistic 回归的思想,我们想将对于删去的维度使数据尽可能集中,设数据为 D={x1,…,xn},xi=(xi1,xi1,…,xid)T 代表我们的数据点,我们的目标就是找到一个轴使数据
我们将数据去中心化处理:
m=n1i=1∑nxiLet xi~=xi−mX~=[x1~,x2~,…,xn~]T
则数据的协方差为:
Σ=n−11X~X~T
其中协方差矩阵除以除以 n−1 而不是 n 是为了获得无偏估计:
Cov(X,Y)=n−11i=1∑n(xi−x)(yi−y)
后面我们都是对中心化之后的数据进行计算,所有的 x 默认为 x~
假如我们对数据进行正交变换:
⎩⎪⎪⎪⎨⎪⎪⎪⎧z1=l11x~1+l12x~2+⋯l1dx~dz2=l21x~1+l22x~2+⋯l2dx~d⋯zd=ld1x~1+ld2x~2+⋯lddx~dz=Lx⇒z=Lx
协方差矩阵的变化为:
Λ=n−11zzT=n−11LxxTLT=LΣLT
由 Σ 为一个实对称矩阵,假设其特征值均不相同,存在正交矩阵 V 使它能正交对角化:
Σ=VΛVTΛ=diag(λ1,λ2,…,λd)
其中 V=[v1,v2,…,vd],v1,v2,…,vd 是 $\Sigma $ 的 d 个单位长度的特征向量,λ1,λ2,…,λd 是对应的特征值,那么我们可以写出
为什么我们要对协方差矩阵进行对角化?
当我们对协方差矩阵 Σ 进行特征值分解对角化时,我们实际上是在寻找一组正交基(特征向量),使得在这组基下,协方差矩阵除了对角元素以外的值都为零,即不同维度之间是不相关的;且对于对角元素的值,就是它对应所在方向上数据的方差:
现在考虑将原始数据投影到某一个特征向量 vk 上。如果我们有一个中心化后的数据点 x ,它在 vk 方向上的投影长度是 xTvk 。那么所有数据点在 vk 方向上投影的方差可以表示为:
Var(xTvk)=E[(xTvk)2]−[E(xTvk)]2
由于数据已经中心化,所以 E(xTvk)=E(xT)vk=0,因此上式简化为:
Var (\boldsymbol{x}^T \boldsymbol{v}_k) = \mathbb{E} ( \boldsymbol{x}^T \boldsymbol{v}_k)^2 = \mathbb{E} \left[ \boldsymbol{x}^T \boldsymbol{v}_k \boldsymbol{v}_k^T \boldsymbol{x} \right] \\
= \mathbb{E} \left[ \tr (\boldsymbol{x}^T \boldsymbol{v}_k \boldsymbol{v}_k^T \boldsymbol{x}) \right] = \mathbb{E} \left[ \tr (\boldsymbol{x}^T \boldsymbol{x}) \boldsymbol{v}_k \boldsymbol{v}_k^T \right] = \mathbb{E} \left[ \tr (\boldsymbol{x}^T \boldsymbol{x}) \right] \boldsymbol{v}_k \boldsymbol{v}_k^T \\
=\tr \left( \mathbb{E} \left[ \boldsymbol{x} \boldsymbol{x}^T \right] \boldsymbol{v}_k \boldsymbol{v}_k^T \right) = \tr \left( \Sigma \boldsymbol{v}_k \boldsymbol{v}_k^T \right) = \tr \left( \boldsymbol{v}_k^T \Sigma \boldsymbol{v}_k \right) = \boldsymbol{v}_k^T \Sigma \boldsymbol{v}_k
根据特征值分解的性质,我们知道 Σvk=λkvk ,因此:
Var(xTvk)=vkT(λkvk)=λk(vkTvk)
因为 vk 是单位向量,所以 vkTvk=1 ,最终我们得到:
Var(xTvk)=λk
假设我们的数据分布如上图所示,我们希望将数据的维度从二维降到一维。为此,我们可以尝试画一条线来代表数据特征的分布。通过这条线,我们可以直观地感受到“能将数据尽可能离散地分布在某个轴上,这个轴就是良好的投影轴”。接下来,我们将建模这一过程。
借鉴逻辑回归的思想,我们希望通过保留一个轴使数据尽可能集中。设数据集为 D={x1,…,xn},其中每个数据点 xi=(xi1,xi2,…,xid)T。再设数据服从分布 xi∼x,i.i.d 我们的目标是找到这样一个轴,使得数据在该轴上的投影能够最大化数据的分散程度。
首先,我们需要对数据进行中心化处理:
m=n1i=1∑nxi令 xi~=xi−mX~=[x1~,x2~,…,xn~]T
此时,数据的协方差矩阵为:
Σ=n−11X~X~T
这里,协方差矩阵除以 n−1 而不是 n 是为了获得无偏估计:
Cov(X,Y)=n−11i=1∑n(xi−xˉ)(yi−yˉ)
后续的所有计算都将基于中心化后的数据,因此默认情况下所有 x 均指代 x~。接下来,如果我们对数据进行正交变换:
⎩⎪⎪⎪⎨⎪⎪⎪⎧z1=l11x~1+l12x~2+⋯l1dx~dz2=l21x~1+l22x~2+⋯l2dx~d⋯zd=ld1x~1+ld2x~2+⋯lddx~dz=Lx
则协方差矩阵的变化为:
Λ=n−11zzT=n−11LxxTLT=LΣLT
由于 Σ 是一个实对称矩阵,假设其特征值互不相同,则存在正交矩阵 V 使其能够正交对角化:
Σ=VΛVTΛ=diag(λ1,λ2,…,λd)
其中 V=[v1,v2,…,vd],v1,v2,…,vd 是 $\boldsymbol{\Sigma} $ 的 d 个单位长度的特征向量,而 λ1,λ2,…,λd 则是对应的特征值。
那么,为什么要对协方差矩阵进行对角化呢?
当我们对协方差矩阵 Σ 进行特征值分解时,实际上是在寻找一组正交基(即特征向量),使得在这组基下,协方差矩阵除了对角元素外均为零,这意味着不同维度间相互独立;同时,这些对角元素正是对应方向上数据的方差。
现在考虑将原始数据投影到某一特定特征向量 vk 上。对于一个已中心化的数据点 x,它在 vk 方向上的投影长度为 xTvk。因此,所有数据点在 vk 方向上投影的方差可以表示为:
Var(xTvk)=E[(xTvk)2]−[E(xTvk)]2
由于数据已经进行了中心化处理,故有 E(xTvk)=E(xT)vk=0,于是上述公式简化为:
Var (\boldsymbol{x}^T {\boldsymbol{v}}_k) = \mathbb{E} ( \boldsymbol{x}^T {\boldsymbol{v}}_k)^2 = \mathbb{E} \left[ \boldsymbol{x}^T {\boldsymbol{v}}_k {\boldsymbol{v}}_k^T \boldsymbol{x} \right] \\
= \mathbb{E} \left[ \tr (\boldsymbol{x}^T {\boldsymbol{v}}_k {\boldsymbol{v}}_k^T \boldsymbol{x}) \right] = \mathbb{E} \left[ \tr (\boldsymbol{x}^T \boldsymbol{x}) {\boldsymbol{v}}_k {\boldsymbol{v}}_k^T \right] = \mathbb{E} \left[ \tr (\boldsymbol{x}^T \boldsymbol{x}) \right] {\boldsymbol{v}}_k {\boldsymbol{v}}_k^T \\
=\tr \left( \mathbb{E} \left[ \boldsymbol{x} \boldsymbol{x}^T \right] {\boldsymbol{v}}_k {\boldsymbol{v}}_k^T \right) = \tr \left( \Sigma {\boldsymbol{v}}_k {\boldsymbol{v}}_k^T \right) = \tr \left( {\boldsymbol{v}}_k^T \Sigma {\boldsymbol{v}}_k \right) = {\boldsymbol{v}}_k^T \Sigma {\boldsymbol{v}}_k
根据特征值分解的性质,我们知道 Σvk=λkvk,因此:
Var(xTvk)=vkT(λkvk)=λk(vkTvk)
又因为 vk 是单位向量,所以 vkTvk=1,最终得到:
Var(xTvk)=λk