多模态论文综述
多模态综述——模型架构
过去三年多模态模型获得了巨大的发展
从模型输入输出的视角:
输入单图 + 文本,输出文本
在多模态发展的早期阶段,模型的输入和输出主要集中在图像加文本的形式上,且输出通常是文本。这种设计主要是由于当时的技术限制,特别是缺乏有效的图像生成模型和技术(diffusion,consistency models 等)。因此,研究焦点更多地放在如何有效地将图像信息映射到文本信息上,以完成如图像字幕生成(image captioning)、简单的视觉问答(VQA)、图像-文本检索等任务。
早期的研究工作通常围绕着如何提取和表示图像特征,以及如何将这些特征与文本信息进行融合,从而实现对图像内容的理解和描述。这包括探索不同的视觉编码器架构,比如使用预训练的卷积神经网络(CNN)来提取图像特征,以及通过各种方式将这些特征与文本编码相结合,例如通过注意力机制或特定的多模态融合层。
此外,在那个时期,评估模型性能的数据集也主要关注于这些文本生成任务,如COCO Captions 和 VQA 数据集
从模型结构的视角
dual embedding + modality interaction
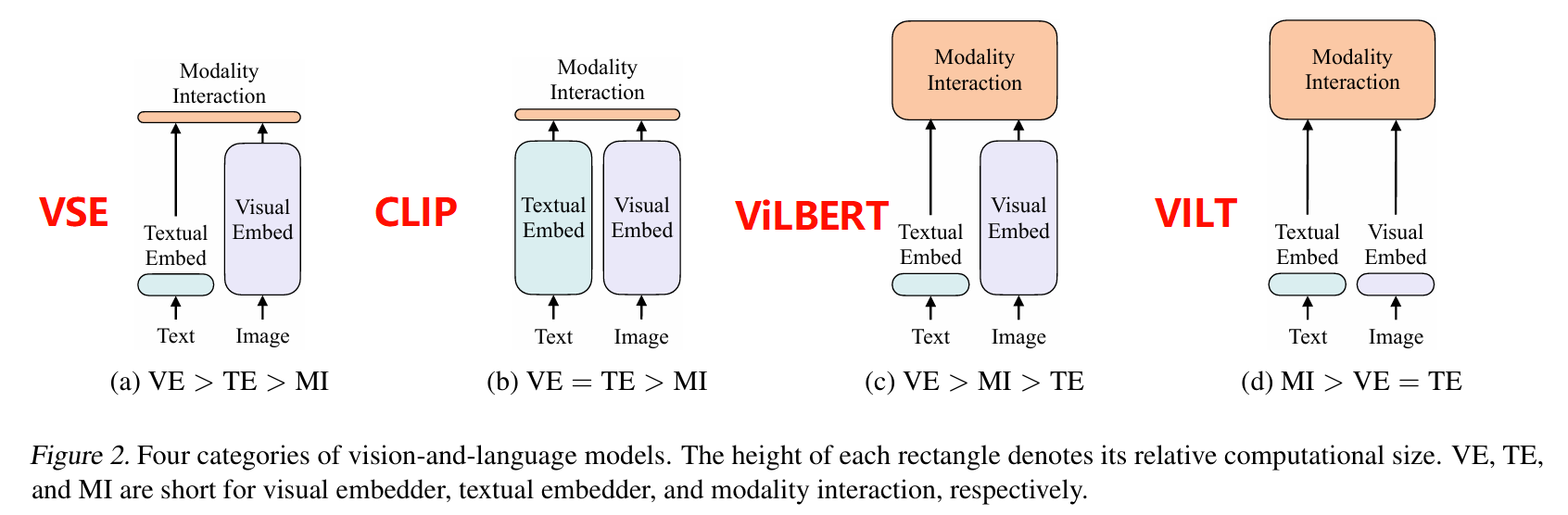
- 模态信息交互:VSE 和 CLIP 在模态融合中只是对不同模态信息进行简单的计算相似度,这是远远不够的,后续的工作发现了模态融合是非常重要的一个过程,于是到后续的 ViLT 的工作,模态交互模块的计算量逐渐增加,表明模型对模态交互的重视程度不断提高
- 视觉与文本编码:CLIP 和 ViLT 中视觉和文本编码模块的计算量相当,而 VSE 和 ViLBERT 中视觉编码模块的计算量大于文本编码模块,直观理解上视觉模态的信息是更难编码的,因此应该使用的视觉模态 encoder 的结构应该比文本模态 embedder 结构更大
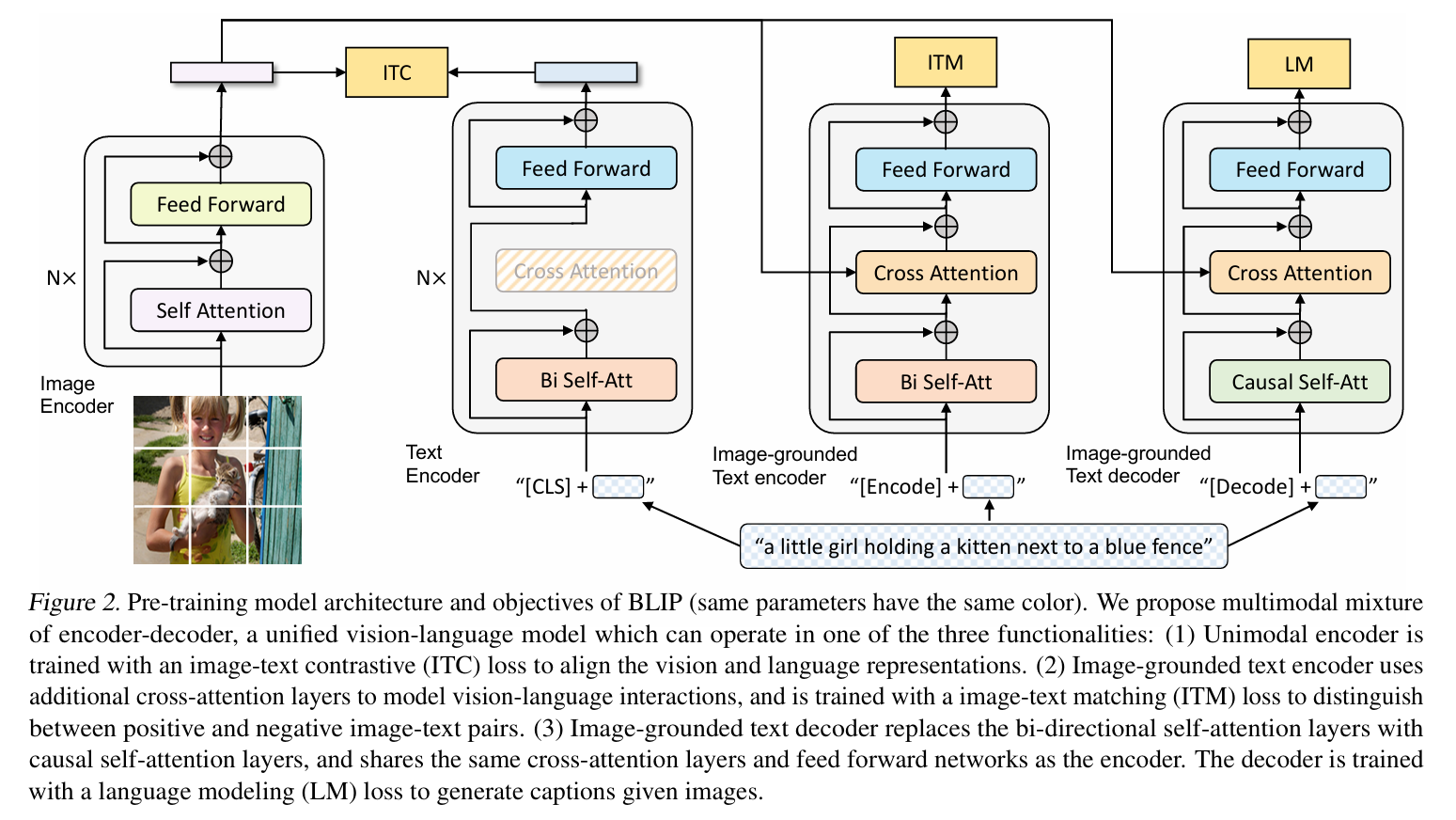
总结上面的两点经验,ALBEF 的模型结构就可以提出来了,一个较大视觉的 embedder 加上一个较小文本的 embedder,最后加上一个大的模态交互融合模块,BLIP 模型也是使用了类似的思想,再加上从 VLMo 工作的启发,将不同阶段的 block 共享参数(和 transformer 架构唯一的不一样就是 FFN 结构,对于不同的模态数据有不同的 FFN 层,但是在模型前面的 self-attention 模块中,所有模态的数据是共用 weight 的):
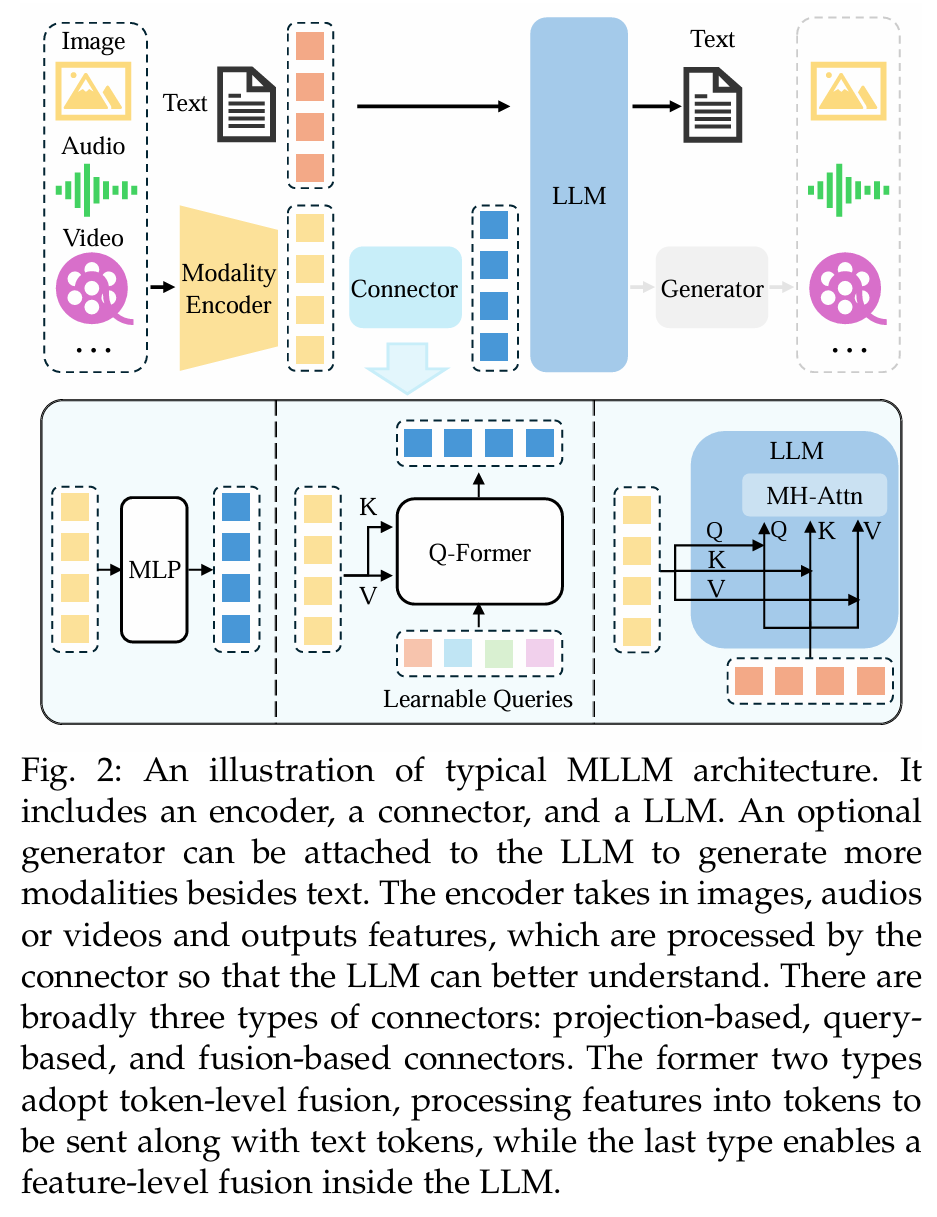
Modality Encoder + LLM
在现代多模态发展中,我们往往不再使用上面的多模态模型结构,因为基于视觉模态的数据不好用用语训练推理能力,于是后续的工作中往往使用了预训练好的 LLM(展现出一定的推理能力)为基础构建有更强推理能力的多模态模型,结构如下图所示:
-
模型的大部分都类似 LLM,LLM 的架构大多数是采用了 decoder-only 的架构,极少数的模型使用了 encoder-decoder 的架构
-
Modality Encoder 是一个对应模态预训练好的强大的模态提取器,对于视觉模态信息往往使用 VIT
值得一提的是,经验证明,对于其他模态的数据,输入 LLM 的数据的分辨率对性能有非常大的影响,提高分辨率的方式分为两类:
- direct-scaling:直接提高输入的分辨率,例如 CogAgent 中的 CogVLM,通过使用 dual-encoder mechanism(对低分辨率图像使用强大的 backbone 提取丰富语义信息,再让高分辨率图像通过一个 lite-encoder 出来的图与丰富语义信息的低分辨率特征图作 cross-attention 丰富细节信息,类似 VITMatte)
- patch-division:将大图像分成小 patch,再将大的图像和小 patch 进行特征融合,提取特征之后输入 Connector,例如 Monkey 的工作
-
Connector 是需要训练的一部分,他将多模态的数据对齐到文本模态,让 LLM 能够理解,Connector 有三种连接方式:
- 暴力 MLP 层:基于 token 层面融合,往往对语音等模态的数据使用,例如 llama-omni 的将语音模态对齐到文本模态就是暴力 MLP 层,原因在于语音模态数据和文本模态数据天生有很强相似性,llava 也是这种方式
- Learnable Queries:基于 token 层面融合,往往对图像模态的数据使用,类似 DETR 的框架,使用可学习的 query 提取特征 token 输入 LLM
- Fusion Base:基于 feature 层面融合,将 embedding 输入 LLM 内部,在 LLM 内部进行特征融合
-
Generator 往往是一个 diffusion
从训练数据清洗的视角
从训练数据来看,多模态的数据集其实是非常脏的,由于多模态的数据集数据量非常大,数据集是从网络上爬下来的,因此混入了非常多的噪声数据
pseudo target
从 ALBEF 开始,由于 ALBEF 的时代并没有 LAION 数据集,它的训练数据全是网络上爬取的,数据集格外 noisy,于是论文中对数据集的质量进行了考虑,使用一个动量模型预测一个 pseudo target,对 ITC loss 进行加权修改

Caption Filter Model
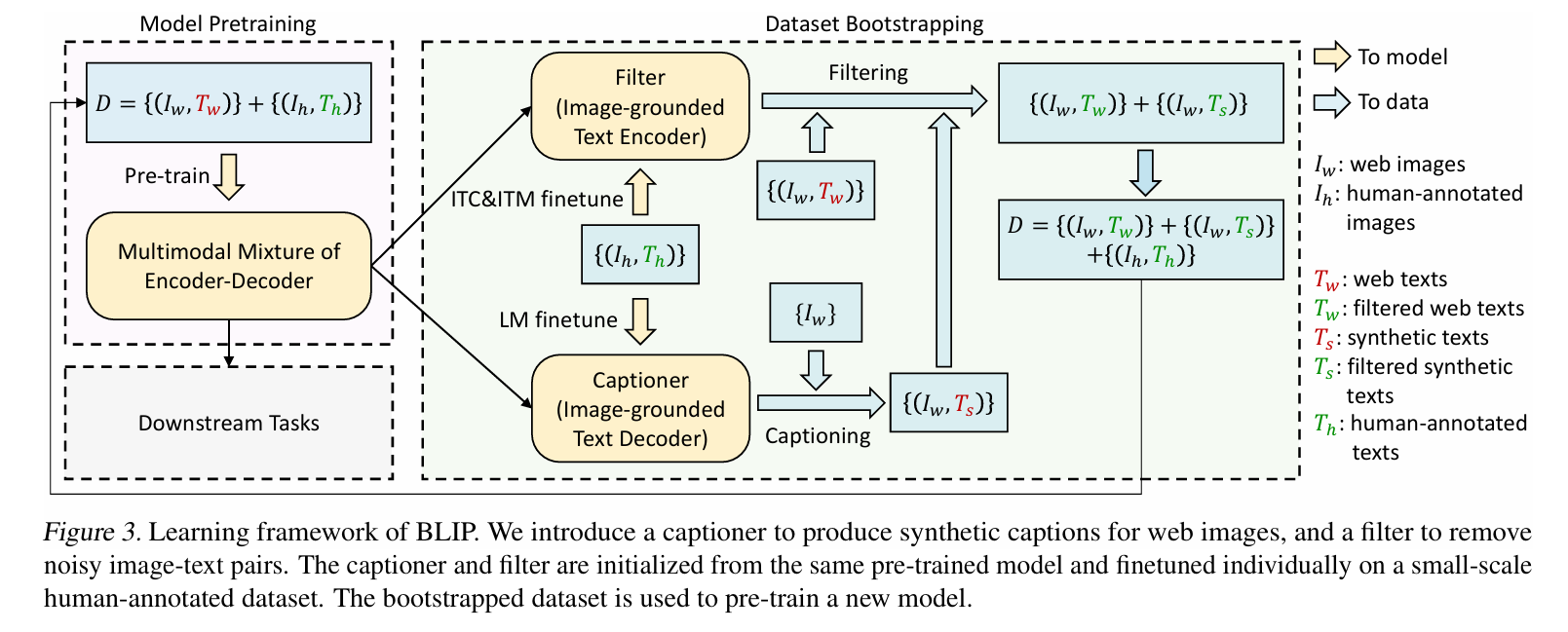
对数据集清洗贡献最大的就是 BLIP 模型了,下图表示了 BLIP 模型对训练数据清洗的过程,BLIP模型通过整合网络爬取的图像-文本对 与人工标注的高质量图像-文本对 ,爬取的图像-文本对有非常多的不匹配,因此使用红色标注,另外手工标注的图像-文本对是精心标注的,完全匹配,干净的新数据有两个来源:
- 从原数据集中过滤:先对多模态混合编码器-解码器架构进行预训练。在此基础上,使用图像引导的文本编码器筛选网络文本(计算文本图像相似度)。比如就采用一个 BLIP,先在 noisy 数据集上训练一个 BLIP,再用这个 BLIP 过滤数据,在训练一个新的效果更好的 BLIP,注意这个预训练模型还进行了一次微调(在 coco 数据集上进行的微调)
- 从 captioner 中进行提取:即使从 noisy dataset 训练出来的 BLIP 仍然有很强的图像描述能力,BLIP 的工作中还使用了一部分 BLIP 自身生成的一些模型进行训练(不能完全保证质量,因此也要进行 filter)
LAION数据就也使用了 caption + filter 的技巧制作了一个非常强大的 LAION-coco 数据集:
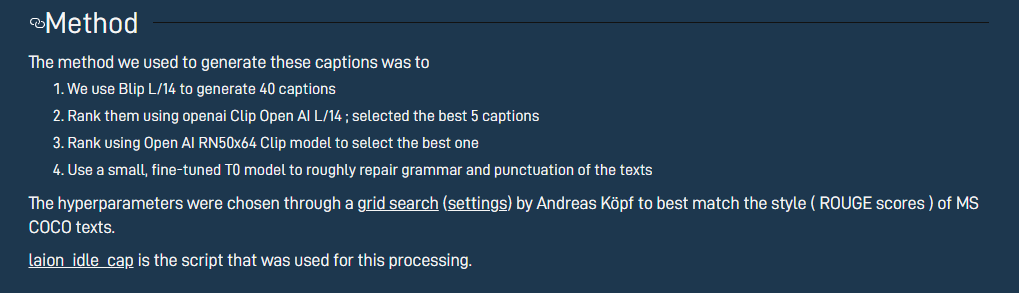
该工作同时揭示了用模型自身产生的数据训练一个新模型,进行迭代训练,训练出一个更好的模型的可能性
从训练方式的视角
MLLM 训练方式和 LLM 相差不大,分为三个部分:pre-training,instruction-tuning,alignment tuning
pre-training
由于 MLLM 模型结构中有很多的部分参数都是需要冻结的,因此在 pre-training 阶段往往只对 connector 进行训练,在这个训练阶段往往使用大规模的 text-paired data,例如 caption data(图像模态和文本模态),但是也有一部分例外,例如 Qwen-VL 模型,它的 pre-training 阶段还训练了 VIT:
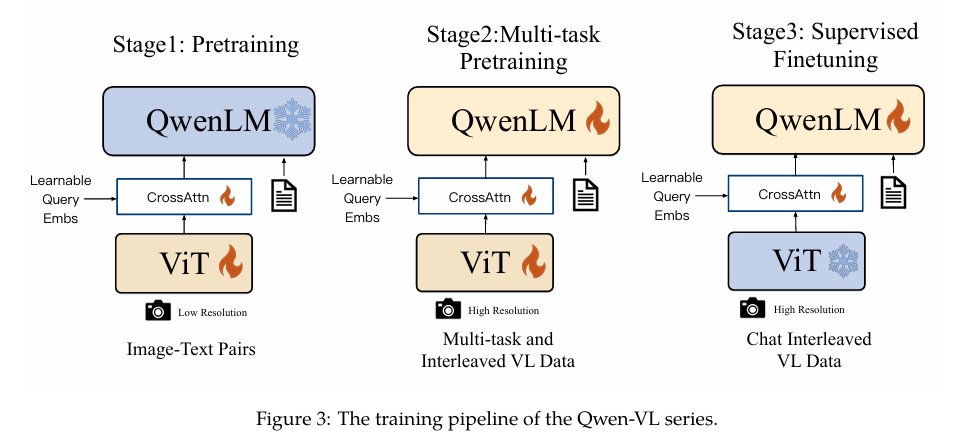
pre-training 阶段一般可以认为有两个作用:
- 将不同模态之间的数据进行对齐
- 给模型提供新的反应客观物理世界的信息
值得一提的是,对于 MLLM,训练数据数据的质量尤其重要,ShareGPT4V 的工作指出使用高质量的数据进行训练,即使模型架构很简单效果也可以非常好,训练数据往往分为粗粒度数据(coarse-grained data)和细粒度数据(fine-grained data)
coarse-grained data 往往是在网络中搜集的大量信息,网络上图像的 caption 往往是简短(描述的信息不够)而且带有大量噪声;而且有时候图像信息的链接丢失,会导致只能使用 alt text,公开数据集包括:CC, SBU Captions,LAION,COYO-700M
instruction-tuning
完成 pre-training 后,让 MLLM 去完成复杂的 VQA 任务是做不到的,在 instruction tuning 阶段,类似 LLM,训练的目标是在各个不同任务下进行训练获得强大的 zero-shot,few-shot 的能力(教会模型回答规则,怎么样进行对话,即增强模型的指令遵循能力)。MLLM 指令微调的数据 sample 可以记为 ,分别是 instruction,multimodal input,ground truth response,记 MLLM 返回的 predicted response 为:
其中 是 MLLM 返回的预测值, 为模型参数,和 LLM 训练完全一致则,loss 函数表示为:
这个阶段数据的收集往往来自三种:data adaptation,self-instruction,data mixture
- data adaptation 示例如下,看上去它只是加了一些无关痛痒的东西,但是这样的输入格式是非常适合 MLLM 进行训练的,事实证明它十分有效

- self-instruction:使用 LLM 生成 instruction 和数据(用 chatgpt 生成数据,用 ai 生成的数据来训练 ai,MMEVOL 就是属于这一个工作)
alignment tuning
alignment tuning 主要关注使模型的行为与人类的价值观和意图保持一致。这涉及到确保模型输出的内容符合道德、伦理和社会规范,并且可以安全地应用于现实世界中,例如,避免生成有害、不实或偏见的信息,常见的方式有 DPO,RLHF,这里不展开细讲
从训练 Loss 的视角
ITC,WPA,ITM,MLM,Image-Text contrastive loss
Captioning Loss
由于 ALBEF 需要多次 forward 才能进行
VQ,VE,VQA