shared_memory
CUDA共享内存概述
GPU内存按照类型(物理上的位置)可以分为
- 板载内存
- 片上内存
全局内存是较大的板载内存,延迟高,共享内存是片上的较小的内存,延迟低,带宽高。前面我我们讲过工厂的例子,全局内存就是原料工厂,要用车来运输原料,共享内存是工厂内存临时存放原料的房间,取原料路程短速度快。
共享内存是一种可编程的缓存,共享内存通常的用途有:
- 块内线程通信的通道
- 用于全局内存数据的可编程管理的缓存
- 告诉暂存存储器,用于转换数据来优化全局内存访问模式
基础知识快速记录
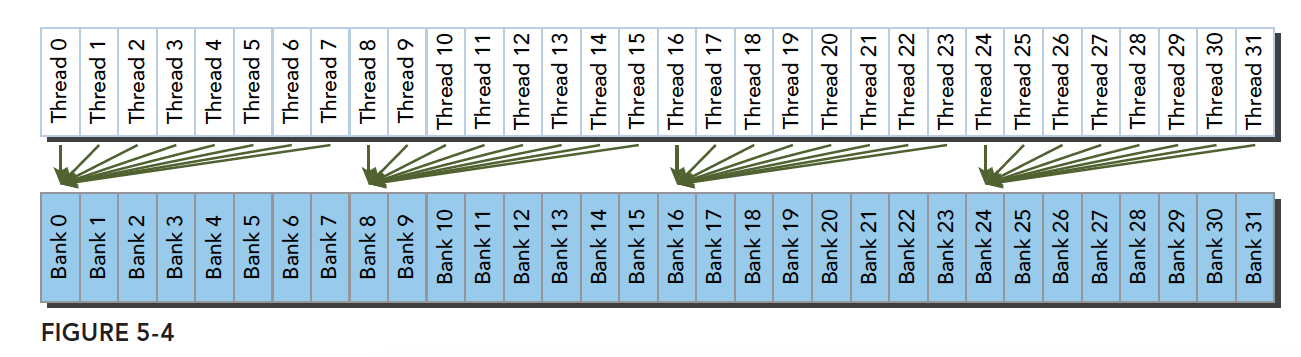
- Shared Memory 可被同一个线程块(block)内的所有线程访问。这意味不仅一个 warp 中的32个线程可以访问共享内存,同一个线程块内的所有线程都可以访问这块共享内存
- 共享内存在硬件层面被划分为多个“bank”(存储库)。每个bank可以独立地进行访问,多个线程在同一时钟周期内访问同一个 bank 的不同地址,就会发生bank冲突(bank conflict)
共享内存
共享内存(shared memory,SMEM)物理层面上,每个 SM 都有一个小的内存池,这个线程池(block)被次SM上执行的线程块中的所有线程所共享。共享内存使同一个线程块中可以相互协同,便于片上的内存可以被最大化的利用,降低回到全局内存读取的延迟
- 共享内存是被我们用代码控制的
- 共享内存是一个 block 内共用的
- 共享内存是在他所属的线程块被执行时建立,线程块执行完毕后共享内存释放,线程块和他的共享内存有相同的生命周期
一级缓存,二级缓存,共享内存,只读和常量缓存的关系如下图:
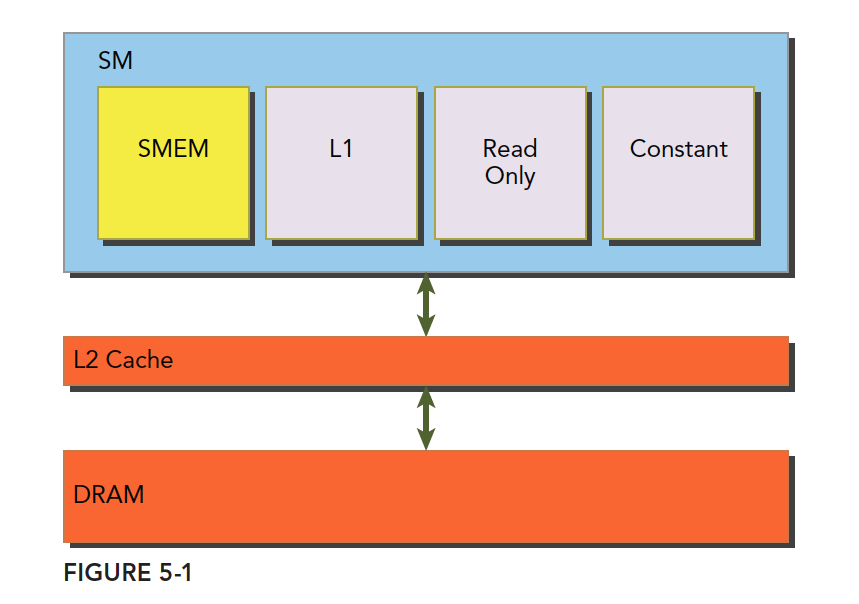
SM 上有共享内存,L1 一级缓存,ReadOnly 只读缓存,Constant常量缓存。所有从 DRAM 全局内存中过来的数据都要经过二级缓存,相比之下,更接近 SM 计算核心的 SMEM,L1,ReadOnly,Constant 拥有更快的读取速度,SMEM 和 L1 相比于 L2 延迟低大概 20~30 倍,带宽大约是10倍
对于每个线程对共享内存的访问请求
- 最好的情况是当前线程束中的每个线程都访问一个不冲突的共享内存,具体是什么样的我们后面再说,这种情况,大家互不干扰,一个事务完成整个线程束的访问,效率最高
- 当有访问冲突的时候,这时候一个线程束32个线程,需要32个事务
- 如果线程束内32个线程访问同一个地址,那么一个线程访问完后以广播的形式告诉其他线程
共享内存分配
分配和定义共享内存的方法有多种,动态的声明,静态的声明都是可以的。可以在核函数内,也可以在核函数外(也就是本地的和全局的,这里是说变量的作用域,在一个文件中),CUDA支持1,2,3维的共享内存声明
声明共享内存通过关键字:
1 | |
声明一个二维浮点数共享内存数组的方法是:
1 | |
这里的 size_x,size_y 和声明 c++ 数组一样,要是一个编译时确定的数字,不能是变量
共享内存存储体和访问模式
声明和定义是代码层面上的产生了共享内存,接下来看看共享内存是怎么存储以及是如何访问的。
内存存储体
共享内存是一个一维的地址空间,共享内存有个特殊的形式是,分为 32 个同样大小的内存模型,称为存储体,可以同时访问。32个 存储体的目的是对应一个线程束中有 32 个线程,这些线程在访问共享内存的时候,如果都访问不同存储体(无冲突),那么一个事务就能够完成,否则(有冲突)需要多个内存事务了,这样带宽利用率降低
是否有冲突,以及冲突如何发生我们下面介绍
存储体冲突
当多个线程要访问一个存储体的时候,冲突就发生了,注意这里是说访问同一个存储体,而不是同一个地址,访问同一个地址不存在冲突(广播形式)。当发生冲突就会有等待和更多的事务产生,这是严重影响效率的
线程束访问共享内存的时候有下面3种经典模式:
- 并行访问,多地址访问多存储体
- 串行访问,多地址访问同一存储体
- 广播访问,单一地址读取单一存储体
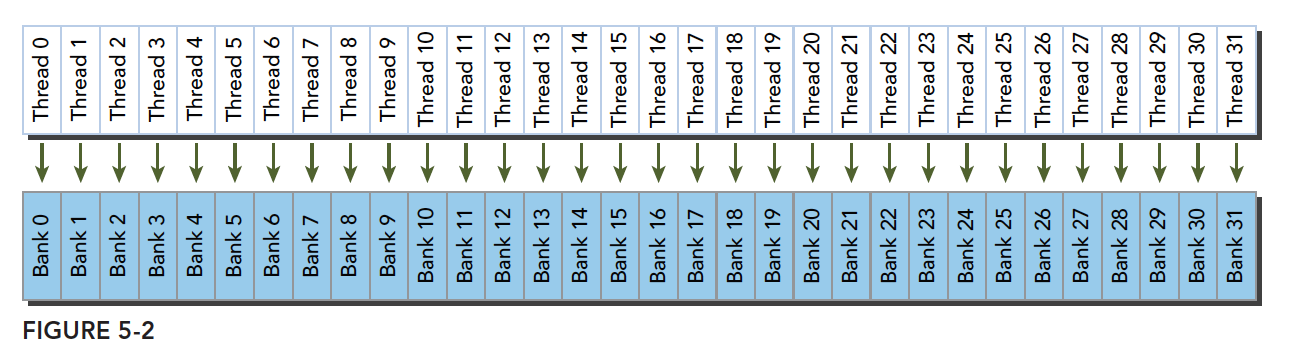
并行访问是最常见,也是效率较高的一种,但是也可以分为完全无冲突,和小部分冲突的情况,完全无冲突是理想模式,线程束中所有线程通过一个内存事务完成自己的需求,互不干扰,效率最高,当有小部分冲突的时候,大部分不冲突的部分可以通过一个内存事务完成,冲突的被分割成另外的不冲突的事务被执行,这样效率稍低
上面的小部分冲突变成完全冲突就是串行模式了,这是最糟糕的形式,所有线程访问同一个存储体,注意不是同一个地址,是同一个存储体,一个存储体有很多地址。这时就是串行访问。广播访问是所有线程访问一个地址,这时候,一个内存事务执行完毕后,一个线程得到了这个地址的数据,他会通过广播的形式告诉其他所有线程,虽然这个延迟相比于完全的并行访问并不慢,但是他只读取了一个数据,带宽利用率很差
最优访问模式(并行不冲突):
不规则的访问模式(并行不冲突):
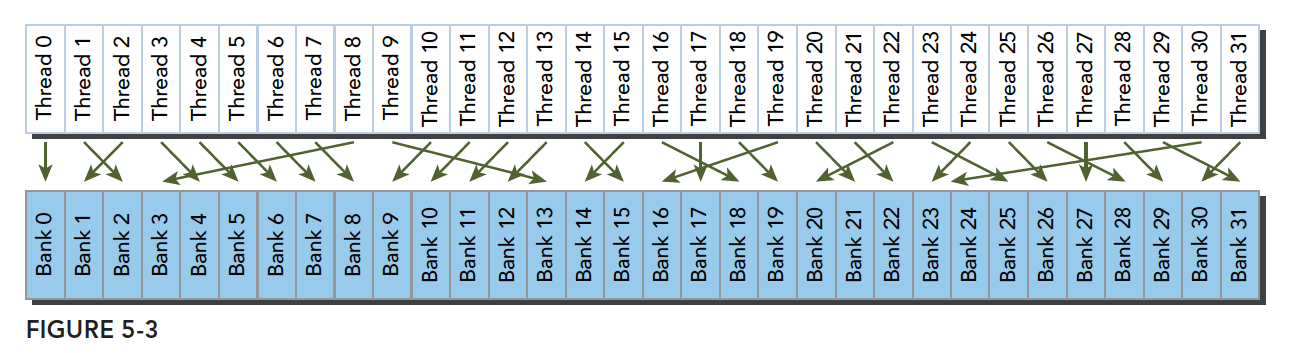
不规则的访问模式(并行可能冲突,也可能不冲突):
访问模式
共享内存的存储体和地址有什么关系呢?这个关系决定了访问模式。内存存储体的宽度随设备计算能力不同而变化,有以下两种情况:
- 2.x 计算能力的设备,为4字节(32位)
- 3.x 计算能力的设备,为8字节(64位)
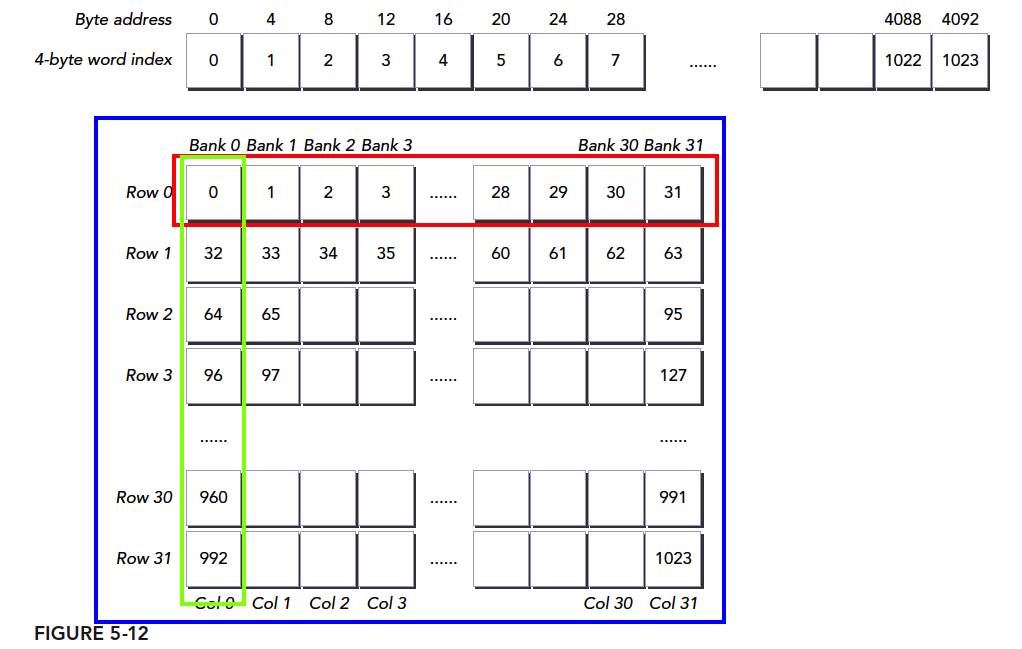
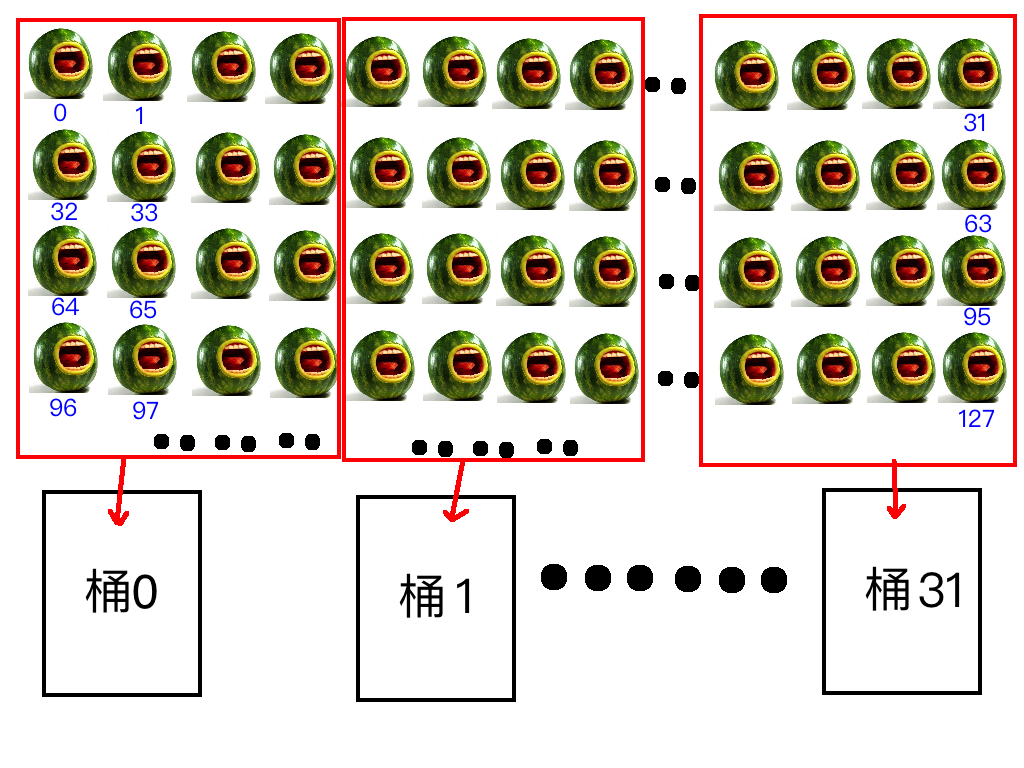
怎么理解宽度呢,我们假设我们这有三十二个水桶,每个水桶当做一个存储体,桶的口大小是固定的,假设我们用桶装西瓜,每个桶的口最多同时能拿出四个西瓜,能拿出四个西瓜,宽度就是4,能拿出八个就是八,这就是宽度的通俗解释。 然后我们将一排西瓜编号,从 0 开始,一直到 n 然后我们有三十二个编了号的桶(0-31号),摆成一排,然后往桶里同时装西瓜,因为一次只能装四个西瓜,那么我们把03号西瓜装到0号桶,4~7 号习惯装入 1 号桶,以此类推,当装到第 31 号桶的时候,我们装 124-127 号西瓜;然后我们每个桶里都有四个西瓜了,接着我们将 128-131 号西瓜装入0号桶,开始下一轮装西瓜。 这就是共享内存的存储体的访问模式
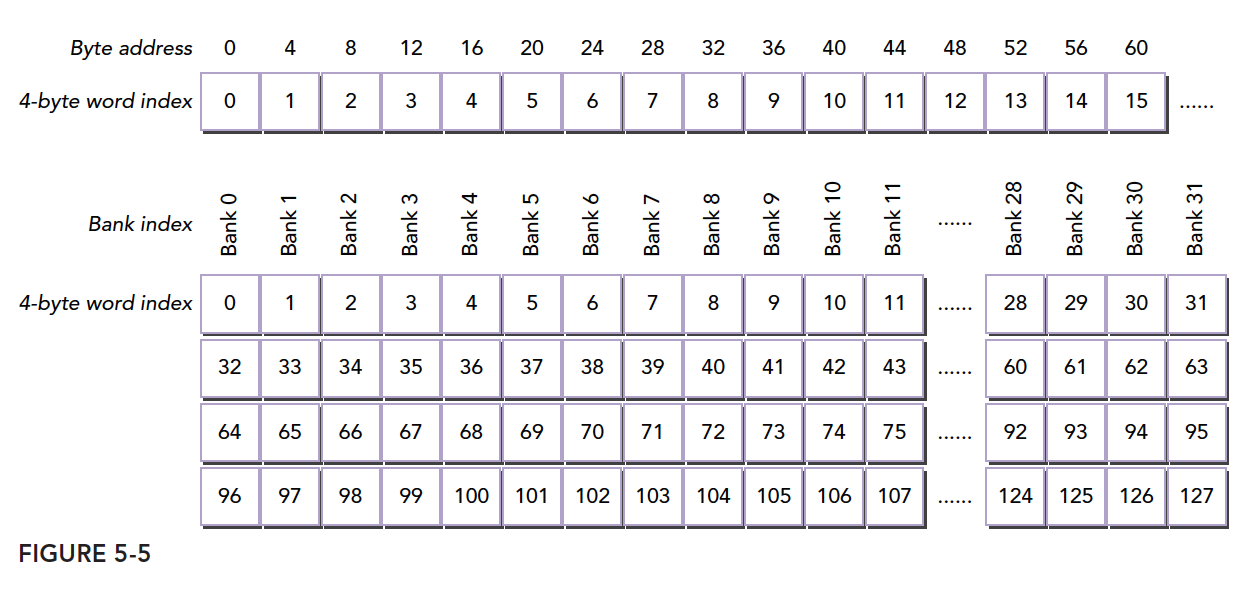
那么已知字节的编号怎么知道对应的存储体编号呢?
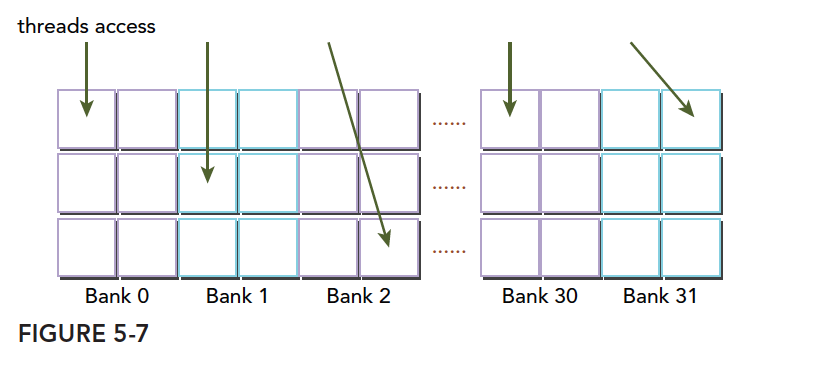
存储体示意正式图:
上图和我们上面的例子相匹配,下面分析冲突的情况:
同一个线程束中的两个线程访问同一个地址不会发生冲突,一个线程读取后广播告诉有相同需求的线程。但是对于写入,这个就不确定了,结果不可预料
上面介绍的存储体宽度是 4 的情况,宽度是 8 的情况同理,但是宽度变宽了,其带宽就有变宽了
冲突的例子
下图显示64位宽的存储体无冲突访问的一种情况,每个bank被划分成了两部分
下图是另一种无冲突方式:
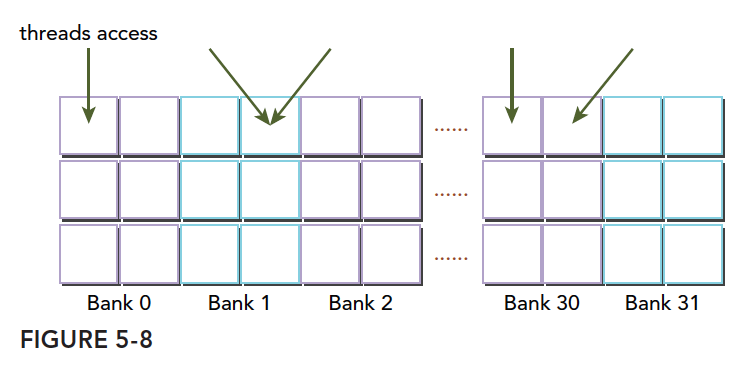
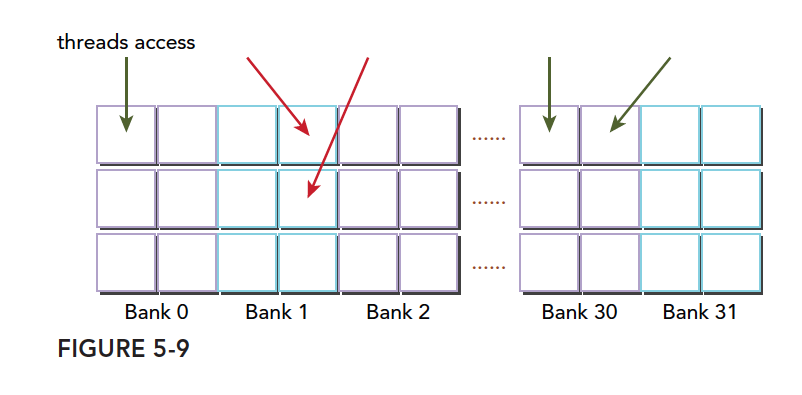
一种冲突方式,两个线程访问同一个小桶:
共享内存的数据布局
方形共享内存
前面说过我们的线程块可以是一维二维和三维的,对应的线程编号是 threadIdx.x, threadIdx.y 以及 threadIdx.z,为了对应一个二维的共享内存,我们假设我们使用二维的线程块,那么对于一个二维的共享内存
1 | |
当我们使用二维块的时候,很有可能会使用下面这种方式来索引x的数据:
1 | |
这个索引就是 对应的,我们也可以用 来索引
- 在CPU中,如果用循环遍历二维数组,尤其是双层循环的方式,我们倾向于内层循环对应x,因为这样的访问方式在内存中是连续的,因为CPU的内存是线性存储的
- 但是GPU的共享内存并不是线性的,而是二维的,分成不同存储体的,并且,并行也不是循环,我们最应该避免的是存储体冲突,我们每次执行的是一个线程束,线程束里面有很多线程,对于一个二维的块,切割线程束有两种方法,顺着 y 切,那么就是
threadIdx.x固定(变化慢),而threadIdx.y是连续的变化,顺着 x 切相反;CUDA 中是顺着x切的,也就是一个线程束中的threadIdx.x连续变化。
我们的数据是按照行放进存储体中的这是固定的,所以我们希望,这个线程束中取数据是按照行来进行的,
1 | |
这种访问方式是最优的,threadIdx.x 在线程束中体现为连续变化的,而对应到共享内存中也是遍历共享内存的同一行的不同列
例子如图所示: