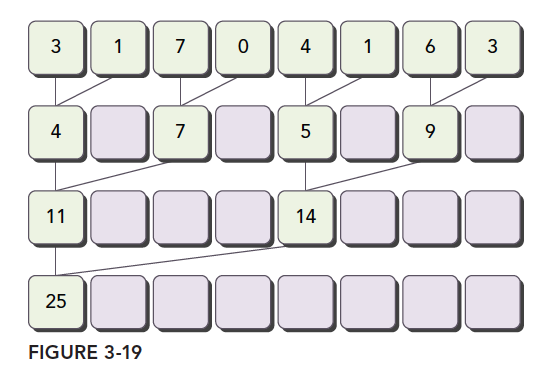
__global__ voidreduceNeighbored(int * g_idata,int * g_odata,unsignedint n){ //set thread ID unsignedint tid = threadIdx.x; //boundary check if (tid >= n) return; //input data pointer int *idata = g_idata + blockIdx.x * blockDim.x; //in-place reduction in global memory for (int stride = 1; stride < blockDim.x; stride *= 2) { if ((tid % (2 * stride)) == 0) { idata[tid] += idata[tid + stride]; } //synchronize within block __syncthreads(); } //write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = idata[0];
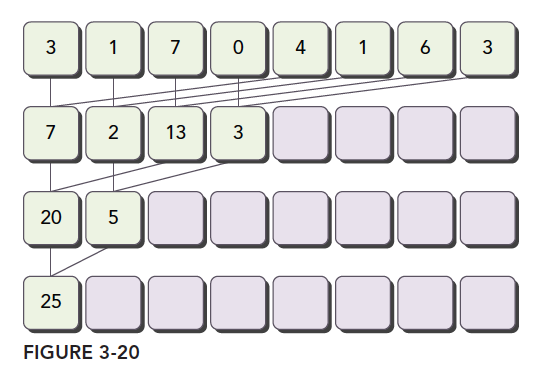
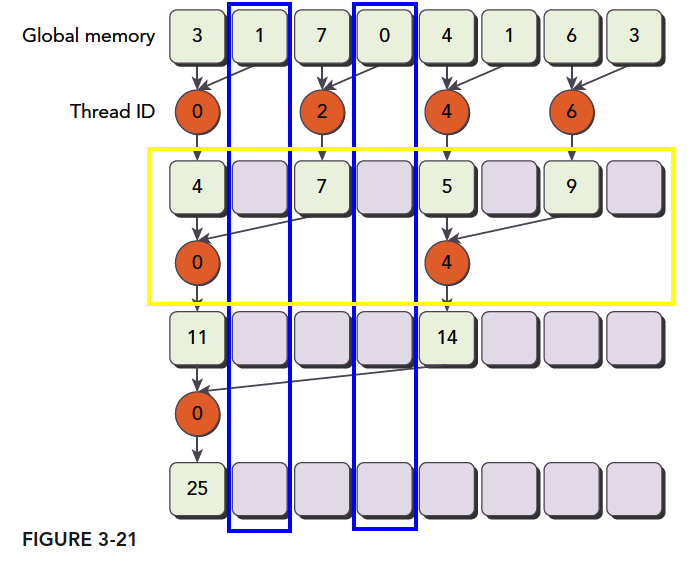
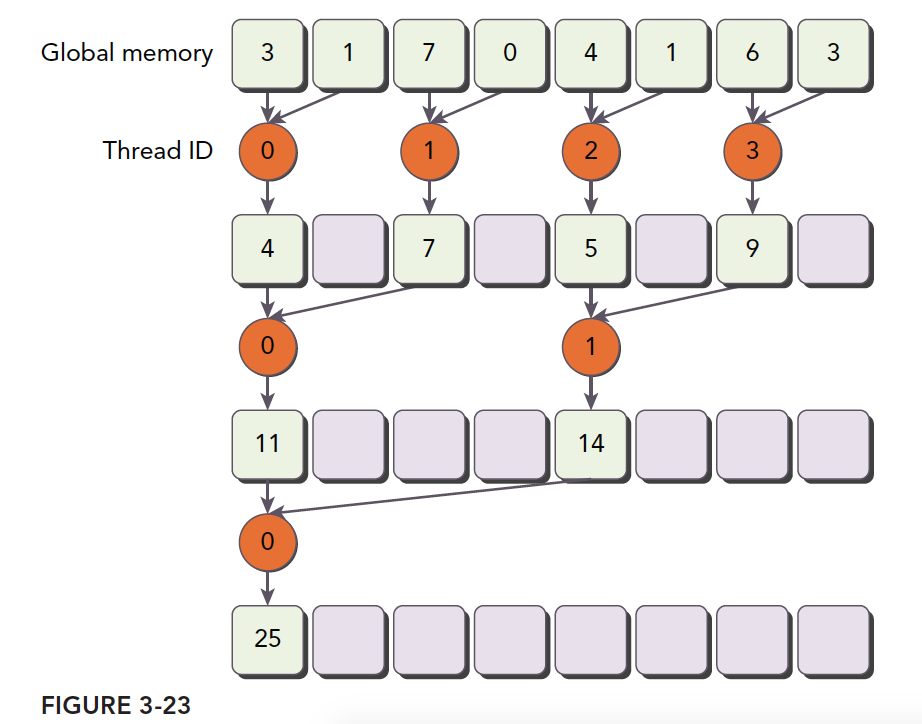
__global__ voidreduceNeighboredLess(int * g_idata,int *g_odata,unsignedint n){ unsignedint tid = threadIdx.x; unsigned idx = blockIdx.x * blockDim.x + threadIdx.x; // convert global data pointer to the local point of this block int *idata = g_idata + blockIdx.x*blockDim.x; if (idx > n) return; //in-place reduction in global memory for (int stride = 1; stride < blockDim.x; stride *= 2) { //convert tid into local array index int index = 2 * stride * tid; if (index < blockDim.x) { idata[index] += idata[index + stride]; } __syncthreads(); } //write result for this block to global men if (tid == 0) g_odata[blockIdx.x] = idata[0]; }
最关键的一步就是
1
int index = 2 * stride *tid;
这一步保证 index 能够向后移动到有数据要处理的内存位置,而不是简单的用 tid(thread id)对应内存地址,导致大量线程空闲