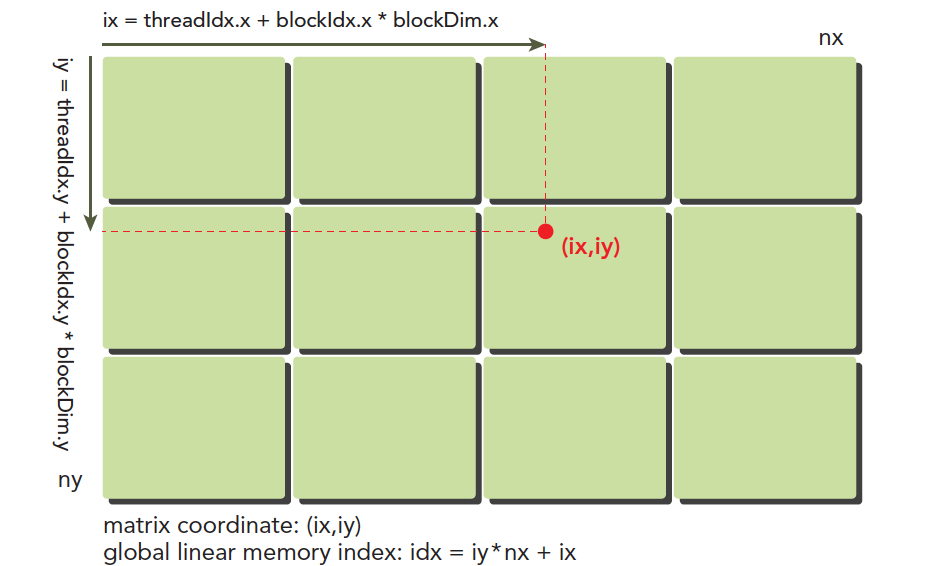
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
| #include <cuda_runtime.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#define CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error: %s in %s at line %d\n", cudaGetErrorString(err), __FILE__, __LINE__); \
exit(EXIT_FAILURE); \
} \
} while (0)
__global__ void sumMatrix(float *MatA, float *MatB, float *MatC, int nx, int ny) {
int ix = threadIdx.x + blockDim.x * blockIdx.x;
int iy = threadIdx.y + blockDim.y * blockIdx.y;
int idx = ix + iy * ny;
if (ix < nx && iy < ny) {
MatC[idx] = MatA[idx] + MatB[idx];
}
}
void initialData(float *ip, int size) {
for (int i = 0; i < size; i++) {
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
}
void checkResult(float *hostRef, float *gpuRef, const int N) {
double epsilon = 1.0E-8;
for (int i = 0; i < N; i++) {
if (abs(hostRef[i] - gpuRef[i]) > epsilon) {
printf("Arrays do not match!\n");
printf("host %f gpu %f at current %d\n", hostRef[i], gpuRef[i], i);
return;
}
}
printf("Arrays match.\n");
}
double cpuSecond() {
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec * 1.e-6);
}
void initDevice(int devNum) {
int dev = devNum;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
}
void sumMatrixOnCPU(float *A, float *B, float *C, int nx, int ny) {
for (int i = 0; i < nx * ny; i++) {
C[i] = A[i] + B[i];
}
}
int main() {
initDevice(0);
int nx = 1 << 12;
int ny = 1 << 12;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
float *A_host = (float *)malloc(nBytes);
float *B_host = (float *)malloc(nBytes);
float *C_host = (float *)malloc(nBytes);
float *C_from_gpu = (float *)malloc(nBytes);
initialData(A_host, nxy);
initialData(B_host, nxy);
float *A_dev = NULL;
float *B_dev = NULL;
float *C_dev = NULL;
CHECK(cudaMalloc((void **)&A_dev, nBytes));
CHECK(cudaMalloc((void **)&B_dev, nBytes));
CHECK(cudaMalloc((void **)&C_dev, nBytes));
CHECK(cudaMemcpy(A_dev, A_host, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(B_dev, B_host, nBytes, cudaMemcpyHostToDevice));
int dimx = 32;
int dimy = 32;
double iStart = cpuSecond();
sumMatrixOnCPU(A_host, B_host, C_host, nx, ny);
double iElaps = cpuSecond() - iStart;
printf("CPU Execution Time elapsed %f sec\n", iElaps);
dim3 block_0(dimx, dimy);
dim3 grid_0((nx - 1) / block_0.x + 1, (ny - 1) / block_0.y + 1);
iStart = cpuSecond();
sumMatrix<<<grid_0, block_0>>>(A_dev, B_dev, C_dev, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = cpuSecond() - iStart;
printf("GPU Execution configuration<<<(%d,%d),(%d,%d)>>> Time elapsed %f sec\n",
grid_0.x, grid_0.y, block_0.x, block_0.y, iElaps);
CHECK(cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost));
checkResult(C_host, C_from_gpu, nxy);
dimx = 32;
dim3 block_1(dimx);
dim3 grid_1((nxy - 1) / block_1.x + 1);
iStart = cpuSecond();
sumMatrix<<<grid_1, block_1>>>(A_dev, B_dev, C_dev, nx * ny, 1);
CHECK(cudaDeviceSynchronize());
iElaps = cpuSecond() - iStart;
printf("GPU Execution configuration<<<(%d,%d),(%d,%d)>>> Time elapsed %f sec\n",
grid_1.x, grid_1.y, block_1.x, block_1.y, iElaps);
CHECK(cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost));
checkResult(C_host, C_from_gpu, nxy);
dimx = 32;
dim3 block_2(dimx);
dim3 grid_2((nx - 1) / block_2.x + 1, ny);
iStart = cpuSecond();
sumMatrix<<<grid_2, block_2>>>(A_dev, B_dev, C_dev, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = cpuSecond() - iStart;
printf("GPU Execution configuration<<<(%d,%d),(%d,%d)>>> Time elapsed %f sec\n",
grid_2.x, grid_2.y, block_2.x, block_2.y, iElaps);
CHECK(cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost));
checkResult(C_host, C_from_gpu, nxy);
cudaFree(A_dev);
cudaFree(B_dev);
cudaFree(C_dev);
free(A_host);
free(B_host);
free(C_host);
free(C_from_gpu);
cudaDeviceReset();
return 0;
}
|