excute_model
CUDA编程的组件与逻辑
下图从逻辑角度和硬件角度描述了CUDA编程模型对应的组件。
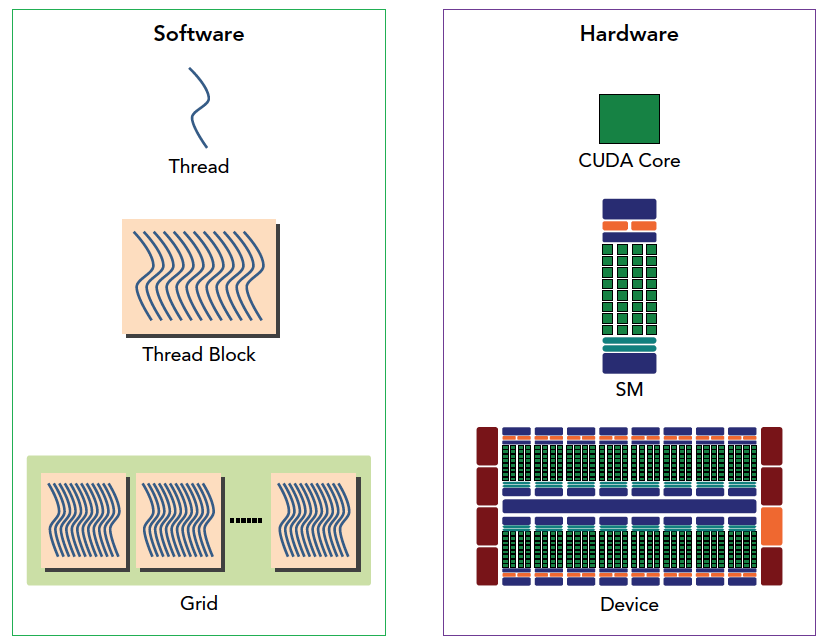
SM 中共享内存,和寄存器是关键的资源,线程块中线程通过共享内存和寄存器相互通信协调。寄存器和共享内存的分配可以严重影响性能!
因为SM有限,虽然我们的编程模型层面看所有线程都是并行执行的,但是在微观上看,所有线程块也是分批次的在物理层面的机器上执行,线程块里不同的线程可能进度都不一样,但是同一个线程束内的线程拥有相同的进度。
并行就会引起竞争,多线程以未定义的顺序访问同一个数据,就导致了不可预测的行为,CUDA只提供了一种块内同步的方式,块之间没办法同步!
同一个 SM上可以有不止一个常驻的线程束,有些在执行,有些在等待,他们之间状态的转换是不需要开销的。
SM 架构
GPU 架构是围绕一个流式多处理器(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件并行。
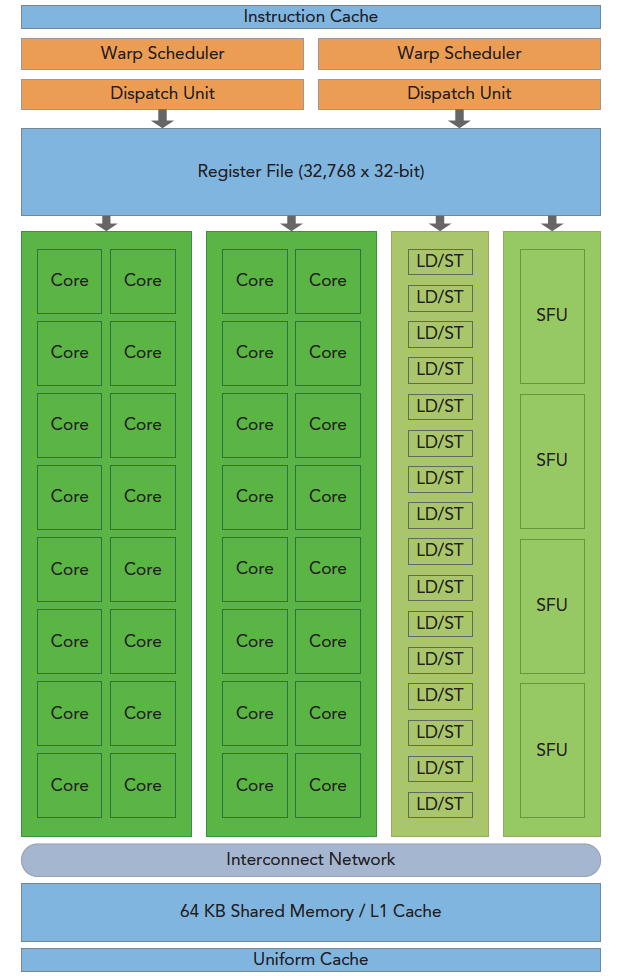
上图包括关键组件:
- CUDA核心
- 共享内存/一级缓存(L1 cache 也称 shared memory)
- 寄存器文件
- 加载/存储单元
- 特殊功能单元
- 线程束调度器
GPU 中每个 SM 都能支持数百个线程并发执行,每个 GPU 通常有多个 SM,当一个核函数的网格被启动的时候,多个 block 会被同时分配给可用的 SM 上执行
注意: 当一个block被分配给一个 SM 后,他就只能在这个 SM 上执行了,不可能重新分配到其他 SM 上了,多个线程块可以被分配到同一个 SM 上
在SM上同一个块内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
SIMD vs SIMT
单指令多数据的执行属于向量机,比如我们有四个数字要加上四个数字,那么我们可以用这种单指令多数据的指令来一次完成本来要做四次的运算。这种机制的问题就是过于死板,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外
相比之下单指令多线程 SIMT 就更加灵活了,虽然两者都是将相同指令广播给多个执行单元,但是SIMT的某些线程可以选择不执行,也就是说同一时刻所有线程被分配给相同的指令,SIMD规定所有人必须执行,而SIMT则规定有些人可以根据需要不执行,这样 SIMT 就保证了线程级别的并行,而 SIMD 更像是指令级别的并行。SIMT 包括以下 SIMD 不具有的关键特性:
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
而上面这三个特性在编程模型可用的方式就是给每个线程一个唯一的标号 ,并且这三个特性保证了各线程之间的独立
Warp
SM 采用的 SIMT(Single-Instruction, Multiple-Thread,单指令多线程) 架构,warp(线程束) 是最基本的执行单元,一个 warp 包含32个并行 thread,这些 thread 以不同数据资源执行相同的指令
当一个 kernel 被执行时,grid 中的线程块被分配到 SM 上,一个线程块的 thread 只能在一个 SM 上调度,SM 一般可以调度多个线程块,大量的 thread 可能被分到不同的 SM 上。每个 thread 拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的 Single Instruction Multiple Thread(SIMT)
一个 CUDA core 可以执行一个 thread,一个 SM 的 CUDA core 会分成几个 warp(即 CUDA core 在 SM 中分组),由 warp scheduler 负责调度。尽管 warp 中的线程从同一程序地址开始执行,但可能具有不同的行为,比如分支结构,因为 GPU 规定 warp 中所有线程在同一周期执行相同的指令,warp 发散会导致性能下降。一个 SM 同时并发的 warp 是有限的,因为资源限制,SM 要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以 SM 的配置会影响其所支持的线程块和 warp 并发数量
每个 block 的 warp 数量可以由下面的公式计算获得:
一个 warp 中的线程必然在同一个 block 中,如果 block 所含线程数目不是 warp 大小的整数倍,那么多出的那些 thread 所在的 warp 中,会剩余一些 inactive 的 thread,也就是说,即使凑不够 warp 整数倍的 thread,硬件也会为 warp 凑足,只不过那些 thread 是 inactive 状态,需要注意的是,即使这部分 thread 是 inactive 的,也会消耗 SM 资源。由于warp的大小一般为32,所以 block 所含的 thread 的大小一般要设置为32的倍数