直接从 Triton 的官方教程入手。对 MM 做优化, 不论用的是 Triton, 还是 CUDA 目标都是一样的,一句话概括:计算一般是没办法省的, 主要是优化内存的使用, 尽可能的用高速但是比较小的 shared memory
驱动程序(Driver Program):这是在 CPU 上运行的 Python 代码,用于准备数据、配置内核参数,并调用 Triton 内核
算子(Operator)本身:这是用 Triton 编写的 GPU 内核,实际执行高性能计算
核函数定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
@triton.jit defmatmul_kernel( # Pointers to matrices a_ptr, b_ptr, c_ptr, # Matrix dimensions M, N, K, # The stride variables represent how much to increase the ptr by when moving by 1 # element in a particular dimension. E.g. `stride_am` is how much to increase `a_ptr` # by to get the element one row down (A has M rows). stride_am, stride_ak, # stride_bk, stride_bn, # stride_cm, stride_cn, # Meta-parameters BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, # GROUP_SIZE_M: tl.constexpr, # ACTIVATION: tl.constexpr # ):
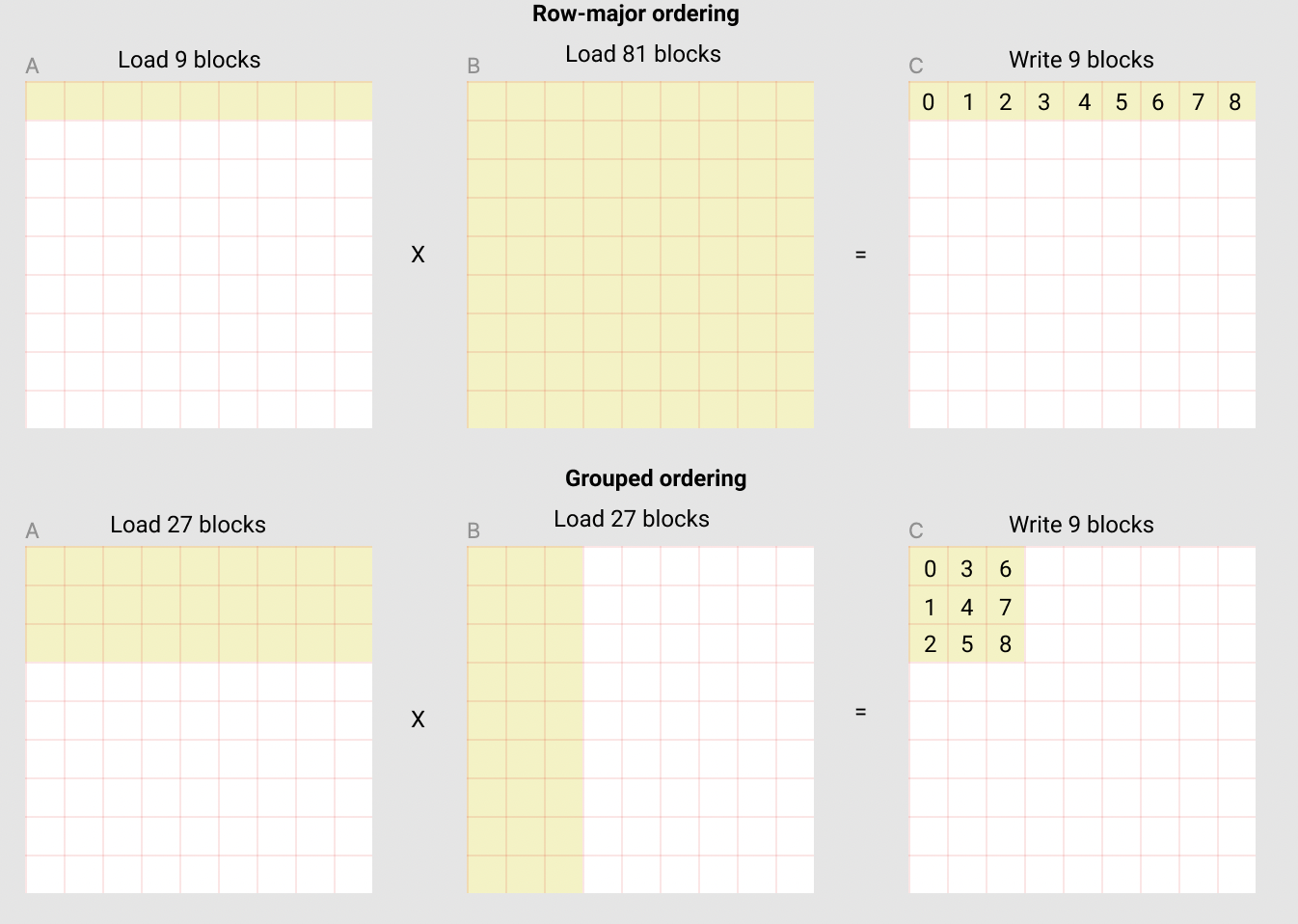
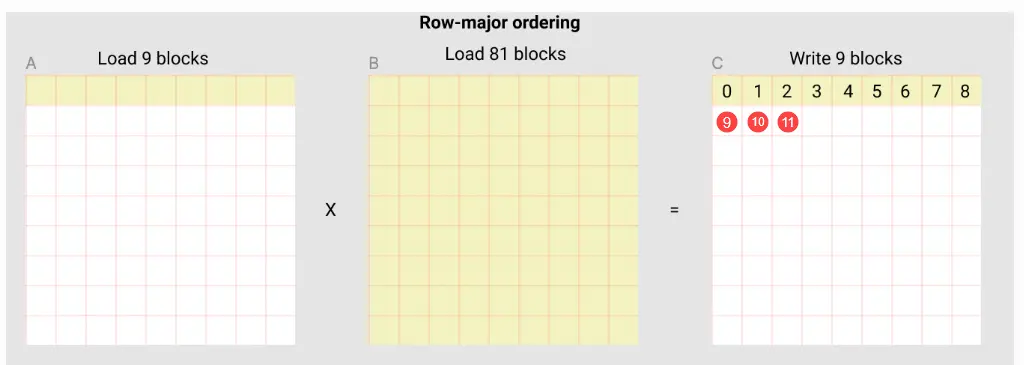
我们要算的是矩阵乘法 A×B=C,A 的大小是 M x K,B 是 K x N,C 的大小是 M x N, kernel function 的要义不是要一把算完,而是每次算出 C 的一部分,我们假设每次"循环"算的大小是 BLOCK_SIZE_M x BLOCK_SIZE_N,那么总共要 “循环” BLOCK_SIZE_MM×BLOCK_SIZE_NN 次
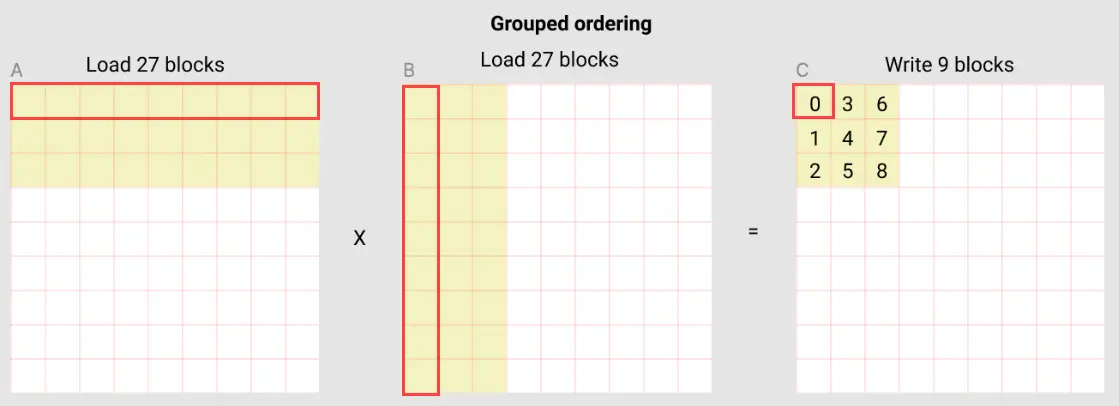
前面讲的,是 kernel function 不同 call 之间的关系(pid 和网格序号之间的关系),实际上还没有具体到当前的这次 call。kernel function 的每次 call,对应于一个 pid,前面讲的其实就是找到当前这个 pid 对应 C 中的哪个 block (黄色小块)。现在我们具体到 block 内部. 假设我们要计算 C 中的第一个 block,block-0
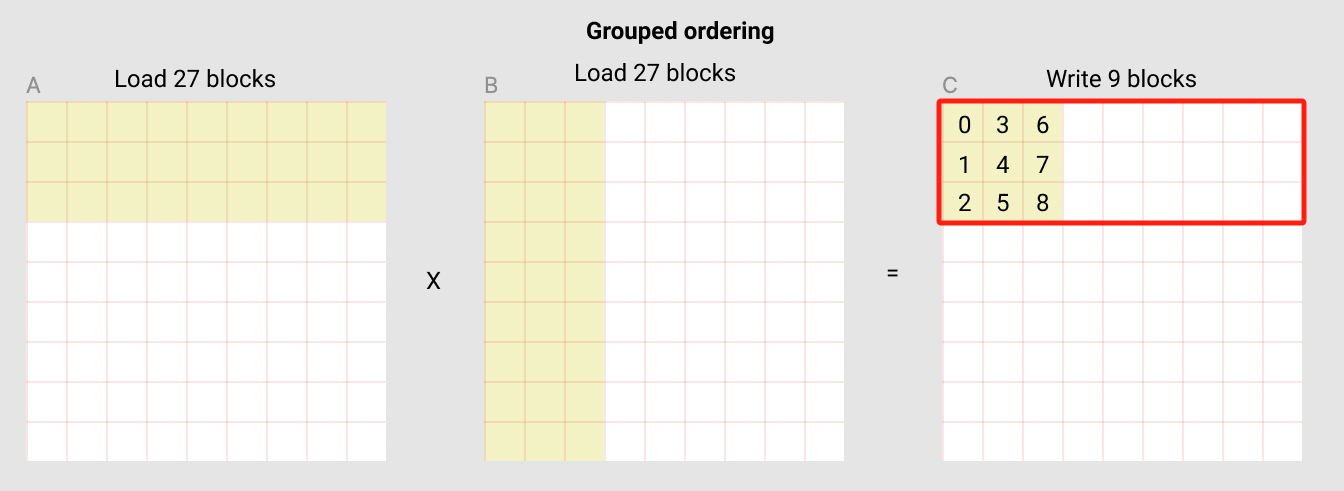
计算这个 block 需要的 A 和 B 矩阵中的 9 个 block:
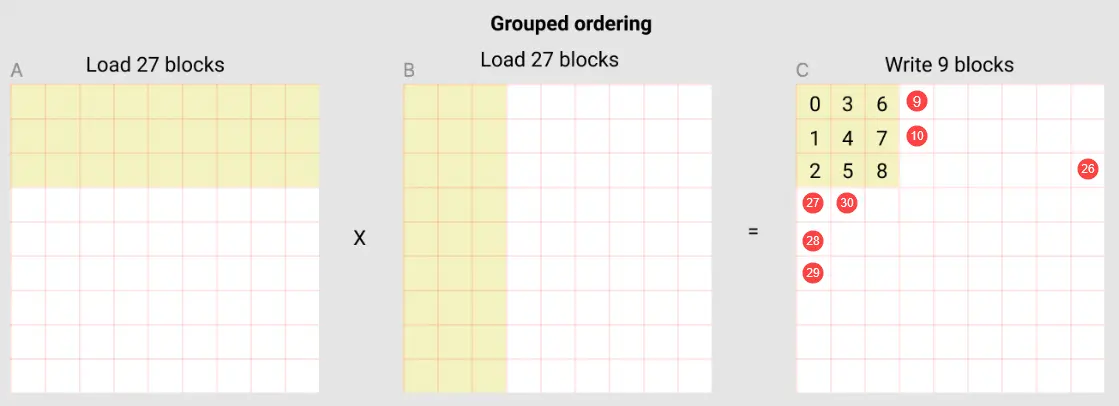
先从 A 中取 9 个 block 中的第一个 block,从 B 中取 9 个 block 中的第一个 block,然后二者相乘,加到一个 accumulator 中,直到 9 个 block 做完, 就得到了 C 中的第一个 block
所以,在每个 pid 内部也是需要循环的,这个循环是在 9 个 block 上面做的。但是,为了让这个循环开始, 我们要先 load A 和 B 中 9 个 block 中的第一个 block
一个 block 中, 有多个 elements,接下来要找到每个 element 的 pointer
1 2 3 4 5 6 7 8 9 10 11 12
# ---------------------------------------------------------- # Create pointers for the first blocks of A and B. # We will advance this pointer as we move in the K direction # and accumulate # `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers # `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers # See above `Pointer Arithmetics` section for details offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N offs_k = tl.arange(0, BLOCK_SIZE_K) a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak) b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
以 A 的第一个 block 为例,a_ptr 是整个 A 矩阵第一个元素的地址,offs_am 和 offs_bn 是 A 矩阵 9 个 block 中第一个 block 中,每个元素在整个 A 矩阵中的坐标 (也就是 m 维度的 index 和 k 维度的 index),所以,它们其实是一个 list,这里用的是 tl.arange, 其实和 numpy.arange 差不多,Triton 之所以自己搞了 tl.arange 为了后面 compile 的时候比较方便
有了 m 维度 和 k 维度的 index,就可以让它们各自和 m 维度 和 k 维度的 stride 相乘,然后和 a_ptr 相加,就可以得到 A 矩阵 9 个 block 中第一个 block 中每个 element 的地址
# Iterate to compute a block of the C matrix. # We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block # of fp32 values for higher accuracy. # `accumulator` will be converted back to fp16 after the loop. accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32) for k inrange(0, tl.cdiv(K, BLOCK_SIZE_K)): # Load the next block of A and B, generate a mask by checking the K dimension. # If it is out of bounds, set it to 0. a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0) b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0) # We accumulate along the K dimension. accumulator += tl.dot(a, b) # Advance the ptrs to the next K block. a_ptrs += BLOCK_SIZE_K * stride_ak b_ptrs += BLOCK_SIZE_K * stride_bk
if ACTIVATION == "leaky_relu": accumulator = leaky_relu(accumulator)
在外部, 你可以定义 leaky_relu
1 2 3 4 5
# We can fuse `leaky_relu` by providing it as an `ACTIVATION` meta-parameter in `_matmul`. @triton.jit defleaky_relu(x): x = x + 1 return tl.where(x >= 0, x, 0.01 * x)
@triton.jit defmatmul_kernel( # Pointers to matrices a_ptr, b_ptr, c_ptr, # Matrix dimensions M, N, K, # The stride variables represent how much to increase the ptr by when moving by 1 # element in a particular dimension. E.g. `stride_am` is how much to increase `a_ptr` # by to get the element one row down (A has M rows). stride_am, stride_ak, # stride_bk, stride_bn, # stride_cm, stride_cn, # Meta-parameters BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, # GROUP_SIZE_M: tl.constexpr, # ACTIVATION: tl.constexpr # ): """Kernel for computing the matmul C = A x B. A has shape (M, K), B has shape (K, N) and C has shape (M, N) """ # ----------------------------------------------------------- # Map program ids `pid` to the block of C it should compute. # This is done in a grouped ordering to promote L2 data reuse. # See above `L2 Cache Optimizations` section for details. pid = tl.program_id(axis=0) num_pid_m = tl.cdiv(M, BLOCK_SIZE_M) num_pid_n = tl.cdiv(N, BLOCK_SIZE_N) num_pid_in_group = GROUP_SIZE_M * num_pid_n group_id = pid // num_pid_in_group first_pid_m = group_id * GROUP_SIZE_M group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M) pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m) pid_n = (pid % num_pid_in_group) // group_size_m
# ---------------------------------------------------------- # Create pointers for the first blocks of A and B. # We will advance this pointer as we move in the K direction # and accumulate # `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers # `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers # See above `Pointer Arithmetic` section for details offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N offs_k = tl.arange(0, BLOCK_SIZE_K) a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak) b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
# ----------------------------------------------------------- # Iterate to compute a block of the C matrix. # We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block # of fp32 values for higher accuracy. # `accumulator` will be converted back to fp16 after the loop. accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32) for k inrange(0, tl.cdiv(K, BLOCK_SIZE_K)): # Load the next block of A and B, generate a mask by checking the K dimension. # If it is out of bounds, set it to 0. a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0) b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0) # We accumulate along the K dimension. accumulator = tl.dot(a, b, accumulator) # Advance the ptrs to the next K block. a_ptrs += BLOCK_SIZE_K * stride_ak b_ptrs += BLOCK_SIZE_K * stride_bk # You can fuse arbitrary activation functions here # while the accumulator is still in FP32! if ACTIVATION == "leaky_relu": accumulator = leaky_relu(accumulator) c = accumulator.to(tl.float16)
# ----------------------------------------------------------- # Write back the block of the output matrix C with masks. offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M) offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N) c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :] c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N) tl.store(c_ptrs, c, mask=c_mask)
# We can fuse `leaky_relu` by providing it as an `ACTIVATION` meta-parameter in `matmul_kernel`. @triton.jit defleaky_relu(x): return tl.where(x >= 0, x, 0.01 * x)
defmatmul(a, b, activation=""): # Check constraints. assert a.shape[1] == b.shape[0], "Incompatible dimensions" assert a.is_contiguous(), "Matrix A must be contiguous" M, K = a.shape K, N = b.shape # Allocates output. c = torch.empty((M, N), device=a.device, dtype=torch.float16) # 1D launch kernel where each block gets its own program. grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']), ) matmul_kernel[grid]( a, b, c, # M, N, K, # a.stride(0), a.stride(1), # b.stride(0), b.stride(1), # c.stride(0), c.stride(1), # ACTIVATION=activation # ) return c