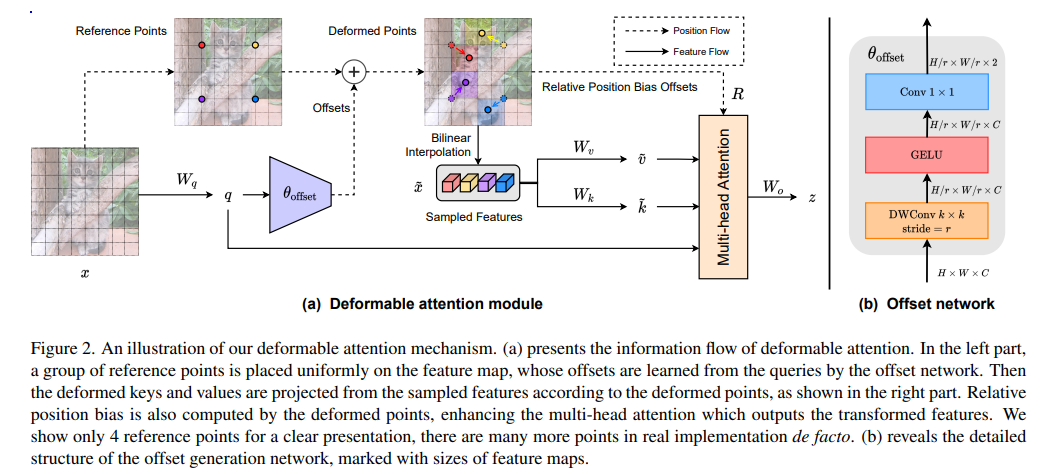
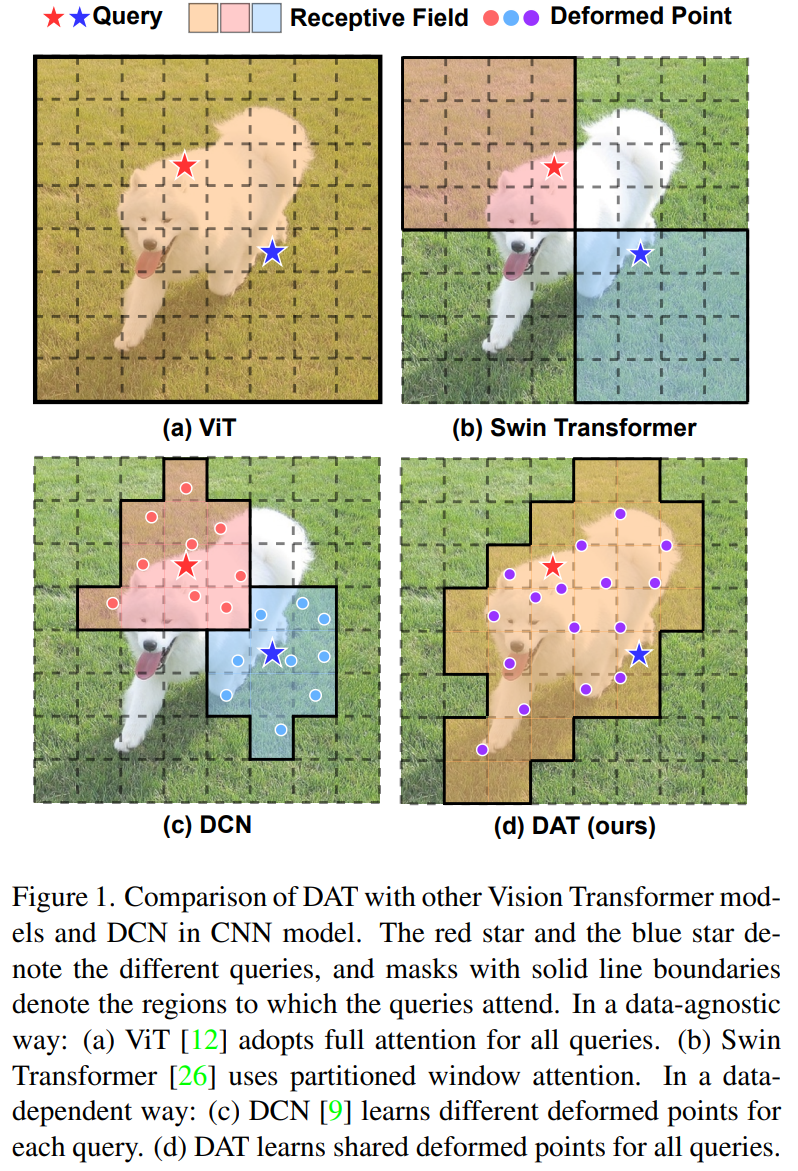
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
| import torch
import torch.nn.functional as F
import torch.nn as nn
import einops
class CPB(nn.Module):
def __init__(self, dim, *, heads, offset_groups, depth):
super().__init__()
self.heads = heads
self.offset_groups = offset_groups
self.mlp = nn.ModuleList([])
self.mlp.append(nn.Sequential(
nn.Linear(2, dim),
nn.ReLU()
))
for _ in range(depth - 1):
self.mlp.append(nn.Sequential(
nn.Linear(dim, dim),
nn.ReLU()
))
self.mlp.append(nn.Linear(dim, heads // offset_groups))
def forward(self, grid_q, grid_kv):
grid_q = einops.rearrange(grid_q, 'h w c -> 1 (h w) c')
grid_kv = einops.rearrange(grid_kv, 'b h w c -> b (h w) c')
pos = einops.rearrange(grid_q, 'b i c -> b i 1 c') - einops.rearrange(grid_kv, 'b j c -> b 1 j c')
bias = torch.sign(pos) * torch.log(pos.abs() + 1)
for layer in self.mlp:
bias = layer(bias)
bias = einops.rearrange(bias, '(b g) i j o -> b (g o) i j', g = self.offset_groups)
return bias
class DeformableAttention(nn.Module):
def __init__(
self,
dim,
dim_head=64,
heads=8,
dropout=0.,
downsample_factor=4,
offset_kernel_size=6,
group_queries=True,
group_key_values=True
):
super().__init__()
self.offset_scale = downsample_factor
assert self.offset_scale - downsample_factor // 2
offset_groups = heads
inner_dim = dim_head * heads
self.offset_groups = offset_groups
self.scale = dim_head ** -0.5
self.heads = heads
self.downsample_factor = downsample_factor
offset_dims = inner_dim // offset_groups
self.to_offset = nn.Sequential(
nn.Conv2d(offset_dims, offset_dims, offset_kernel_size, groups=offset_dims, stride=downsample_factor, padding=(offset_kernel_size - downsample_factor) // 2),
nn.GELU(),
nn.Conv2d(offset_dims, 2, 1, bias=False),
nn.Tanh(),
)
self.rel_pos_bias = CPB(dim // 4, offset_groups=offset_groups, heads=heads, depth=2)
self.dropout = nn.Dropout(dropout)
self.to_q = nn.Conv2d(dim, inner_dim, 1, groups = offset_groups if group_queries else 1, bias = False)
self.to_k = nn.Conv2d(dim, inner_dim, 1, groups = offset_groups if group_key_values else 1, bias = False)
self.to_v = nn.Conv2d(dim, inner_dim, 1, groups = offset_groups if group_key_values else 1, bias = False)
self.to_out = nn.Conv2d(inner_dim, dim, 1)
@staticmethod
def make_grid_like(x):
_, _, h, w = x.shape
coord_h = torch.arange(h, device=x.device)
cooor_w = torch.arange(w, device=x.device)
grid = torch.stack(torch.meshgrid(coord_h, cooor_w, indexing='ij'), dim=0)
grid.requires_grad = False
grid = grid.type_as(x)
return grid
@staticmethod
def normalize_grid(grid, unpack_dim=1):
h, w = grid.shape[-2:]
grid_h, grid_w = grid.unbind(dim=unpack_dim)
grid_h = 2.0 * grid_h / max(h - 1, 1) - 1.0
grid_w = 2.0 * grid_w / max(w - 1, 1) - 1.0
return torch.stack((grid_h, grid_w), dim=unpack_dim)
def forward(self, x, return_vgrid=False):
b, _, h, w = x.shape
group_c2b = lambda t: einops.rearrange(t, 'b (g d) ... -> (b g) d ...', g=self.offset_groups)
q = self.to_q(x)
grouped_queries = group_c2b(q)
offsets = self.to_offset(grouped_queries)
grid = self.make_grid_like(offsets)
vgrid = grid + offsets
vgrid_scaled = self.normalize_grid(vgrid, 1).permute(0, 2, 3, 1)
kv_feats = F.grid_sample(group_c2b(x), vgrid_scaled, mode='bilinear', align_corners=False)
kv_feats = einops.rearrange(kv_feats, '(b g) d ... -> b (g d) ...', b=b)
k = self.to_k(kv_feats)
v = self.to_v(kv_feats)
q, k, v = map(lambda t: einops.rearrange(t, 'b (h d) ... -> b h (...) d', h=self.heads), (q, k, v))
sim = torch.einsum('b h i d, b h j d -> b h i j', q, k)
grid = self.make_grid_like(x)
grid_scaled = self.normalize_grid(grid, 0).permute(1, 2, 0)
rel_pos_bias = self.rel_pos_bias(grid_scaled, vgrid_scaled)
sim = sim + rel_pos_bias
attn = sim.softmax(dim=-1)
attn = self.dropout(attn)
out = torch.einsum('b h i j, b h j d -> b h i d', attn, v)
out = einops.rearrange(out, 'b h (x y) d -> b (h d) x y', x=h, y=w)
out = self.to_out(out)
if return_vgrid:
return out, vgrid
else:
return out
if __name__ == '__main__':
x = torch.randn(1, 64, 32, 48)
model = DeformableAttention(dim=64, dim_head=64, heads=8, downsample_factor=4)
out = model(x)
print(out.shape)
|