MULTIMODAL LEARNING ACROSS LANGUAGES论文阅读
MULTIMODAL LEARNING ACROSS LANGUAGES
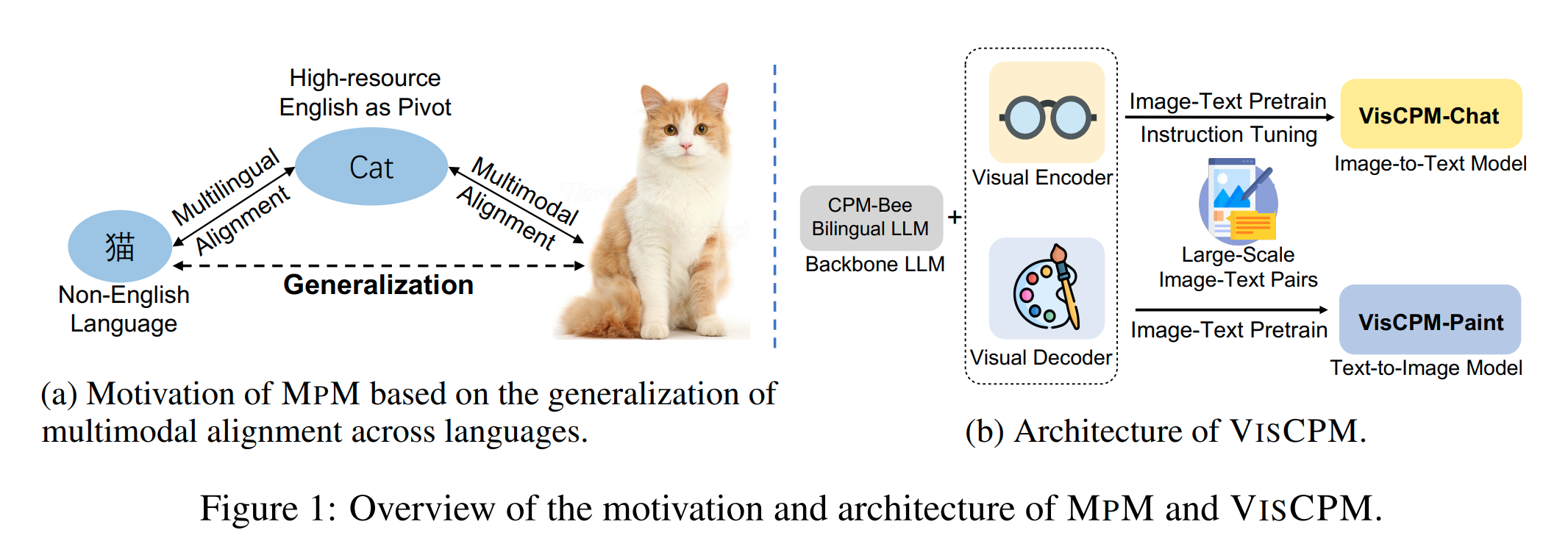
本文提出了一种有效的训练范式MPM(Multilingual language models can Pivot zero-shot Multimodal learning across languages),用于非英语语言的大规模多模态模型训练。MPM展示了如何利用强大的多语言大语言模型,使得仅在英文图像文本数据上预训练的多模态模型能够以准零样本的方式推广到其他语言,并且在某些情况下,其性能甚至可以超过使用本语言图像文本数据训练的模型。该工作通过中文训练出了 VISCPM 模型,在图像到文本和文本到图像生成方面达到了中文领域的最先进水平
解决的问题:大型多模态模型的成功主要是在英语环境中取得的,而在其他非英语语言中的多模态能力则显著落后。原因在于训练多模态模型需要大量的图像-文本对数据。例如,BLIP-2的预训练涉及 1亿个高质量的图像-文本对,而Stable Diffusion 使用了超过20亿对数据。由于非英语语言中缺乏这样的多模态数据资源,这些语言的多模态研究进展因此受到了限制。本文的研究工作就是解决了这样的问题
问题建模
视觉-文本的多模态学习可以认为是在图像数据 和文本数据 之间建模,对于某一个特定的语言(target language)。对于一个 image-to-text generation,可以认为是学习在 target language 下的条件分布 ,这个条件分布参数化为 ;对于一个 text-to-image generation,也可以认为是学习一个条件分布 ,参数化为
在 vanilla 设置中,这些条件分布通常是用高质量的 text-image pairs 来训练的(在 target language 下),但是高质量的 text-image pairs 对于除了英语以外的语言来说都十分稀少。为了减少训练对语言种类的依赖(先前有研究表明对于 semantic information 不依赖于特定的语言种类),我们引入 pivot language 的概念,对于 pivot language ,有大量的高质量的 text-image pairs 多模态训练数据 。类似人类能够快速学习对于一个事物的不同语言的表达(例如🐱),MpM 的想法就是从 pivot language 的视觉概念拓展到 target language(MPM aims to transfer visual concepts learned in the pivot language to the target language)(下面都用“跨语言多模态学习”这个说法表示)
解决思路
MpM 将跨语言多模态学习问题解耦为两个部分:
- Multilingual alignment:MPM 的目标是为语言 和 建立跨语言的一致性。这是通过直接利用预训练的多语言 LLM 来实现的,该模型能够为具有相似语义的文本对 和 提供 similar semantics,即 。这意味着 MPM 使用这样一个多语言模型可以确保在语义层面上对齐
- Multimodal alignment:MPM 利用了 pivot language 中的丰富多模态资源 ,并优化了图像到文本的目标 和文本到图像的目标 。接下来的部分将介绍多模态对齐阶段的训练过程
MPM 是一个框架,并不依赖于对特定的模型架构和训练方法,这使它能够灵活地在每个任务中使用现有的高效模型架构和训练技术
IMAGE-TO-TEXT GENERATION
设 image encoder module 由 参数化,则 visual feature ,visual features 和 text embedding 会拼接在一起输入 multilingual LLM,使用最新的多模态模型的训练方法,MPM 的训练方式可以分解为两步:
- Multimodal pretraining:这个阶段训练 visual module 而将 LLM 的参数冻结,即 (防止LLM的强大能力受到图像-文本对中短文本的影响),损失函数设置为:
- Instruction Tuning:为了增强模型遵循人类指令的能力,论文在精心编排的多模态指令调整数据集上进行了指令调整。这个数据集是通过混合 pivot language 中的现有多模态指令调整数据集(elaborately curated multimodal instruction tuning datasets),和多模态指令调整数据集在 target language 中的翻译版本构建的。将这个多语言指令调整数据集记为 ,其中 是 instruction 而 是 response(对于特定语言 )。视觉模块和 LLM 都通过最大化 response 的似然概率进行微调,即 :
( 不应该奇大无比吗,真的要把所有的交叉熵损失加起来吗…)
在这种情况下,作者发现了多语言多模态模型的一种准零样本迁移能力(quasi-zero-shot transfer capability)。如果排除 target language 中的翻译变体数据,仅使用 pivot languege 进行指令调整,当给定一张图片 和 target language 中的一个问题或指令 时,所得到的模型虽然大多数情况下用 pivot language 回应,但仍能准确地作出反应(思维不依赖于语言而存在!)
作者把这个现象归因于多语言大语言模型所提供的两种语言中指令的隐藏表示之间的高度相似性,即 。因此,有 。也就是说,模型在处理目标语言的问题时,尽管它能够理解问题,但由于预训练和指令调整阶段都只使用了 pivot language 的文本组件,所以它不能在同一语言中校准其回答。
简单来说,模型通过 pivot language 学习到了足够强的语义表示,以至于即使在没有 target训练数据的情况下,它也能够理解目标语言中的指令,并给出准确的回答,尽管回答通常是用 pivot language 而不是 target language。这表明,即使没有直接的目标语言训练数据,多语言多模态模型依然能够展现出一定程度的跨语言理解和生成能力
TEXT-TO-IMAGE GENERATION
(为什么这篇论文不配图啊。。。)
在 text-to-image generation 这个阶段,论文采用了类似 stable diffusion 的模型架构,由一个去噪网络 和一个 UNet 结构组成(参数化为 ),整个 module 作为一个 image decoder 来依据输入的 prompt 生成图像。LLM 和 image decoder 在内部用 cross-attention 进行数据交换。训练目标为:
这个阶段 ,即 image decoder 训练的时候不改变 LLM 的参数。通过这种方式,当输入 target language 中未见过的提示 时,多语言大语言模型 可以 inherently provide a representation 与 pivot language 中具有相似语义的提示 的表示。因此,目标语言中的文本到图像的能力可以无缝地(seamlessly)以零样本的方式从 pivot language 转移过来,这可以表示为 。
理论实践
MPM 在几个模型上进行了实验,本文开发了一系列大规模的中文多模态模型,称为 VISCPM。我们使用中文作为 target language,英文作为 pivot language。双语语言模型 CPM-Bee 作为基础的多语言大语言模型。我们有两个模型变体:用于图像到文本多模态对话的VISCPM-Chat 和用于文本到图像合成的 VISCPM-Paint
VISCPM-CHAT
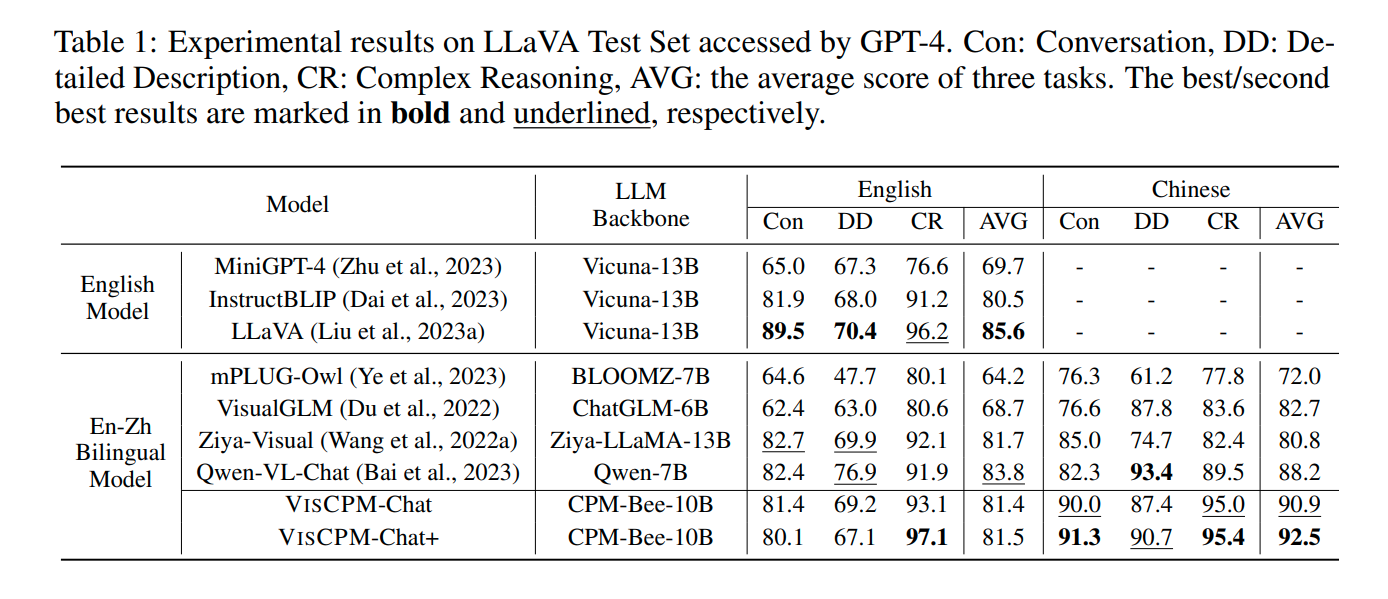
VISCPM-Chat 取得了相当大的提点了(好夸张)。不同于 VisualGLM 和 Qwen-VL-Chat 在预训练期间利用了大量的中文图像-文本对,VISCPM-Chat 在预训练过程中并没有纳入任何中文多模态数据。但 VISCPM-Chat 仍然表现突出。证明了 MPM 在将视觉知识从英语转移到中文上的有效性。在英语中的表现也很强大
VISCPM-PAINT
Ablation Study
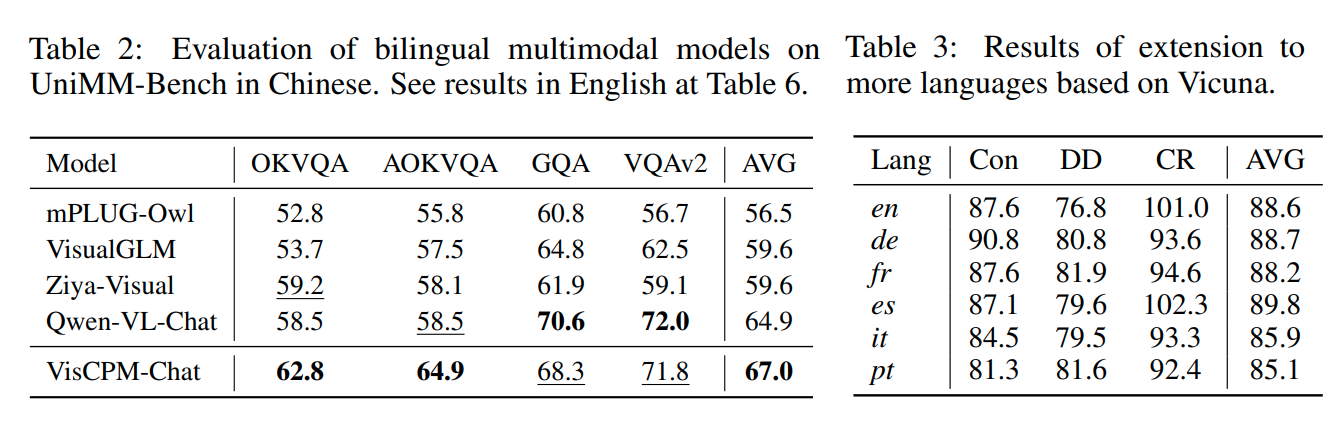
- 仅仅依靠单一语言的本地数据集不足以在图像到文本和文本到图像任务中取得较好的效果。使用单一语言本地数据集训练的模型在两个方向上的表现都不尽如人意
- 英语数据在指令调整阶段对于提高模型的中文对话能力很重要。如果图像到文本模型在大量英语数据上预训练后,再使用单一语言的中文数据集进行微调,其整体性能会有所下降
- 对本地数据集应用过滤过程对于中文的表现也很重要。如果在预训练阶段使用英语数据,然后在微调阶段使用未经筛选的本地中文数据对,那么文本到图像任务的表现会比零样本情形下更差
- 结合本地中文数据集和翻译后的中文数据集对模型性能的提升有限。仅在图像到文本模型的预训练阶段或文本到图像模型的微调阶段加入本地中文数据,对指标的改变不大,而进一步混合翻译数据集则可以稍微改善图像质量
问题:它的参数用一个集合表示代表着这个阶段训练这个参数吗?