LLama-Omni论文阅读
LLama-Omni论文阅读
论文介绍了 LLaMA-Omni 模型,这是一种新颖的模型架构,设计用于实现与大型语言模型(LLMs)之间的低延迟(low latency)、高质量语音交互。LLaMA-Omni 集成了预训练的 audio encoder、audio adaptor、LLM 以及 streaming audio decoder(流式语音解码器),从而消除了对语音转录的需求,能够直接从语音指令生成文本和语音响应,且具有极低的延迟
个人理解:主要工作就是在于使用很少的 module 就在 LLM 中加入了 audio 模态,与直接加一个语音识别和语音合成模块的区别在于:
就是把 embedding 的部分集成到一个 module 内部去了,由于没有改变 LLM 的内部结构,因此我觉得这个不算真正的多模态
网络结构:
LLaMA-Omni 模型架构包括以下模块
- Speech Encoder:此模块使用预训练模型将原始语音输入转换成紧凑的表示形式,捕捉语义信息。使用的编码器基于 Whisper-large-v3模型
- Speech Adapter:语音适配器对编码后的语音表示进行下采样。这一步骤减少了语音输入的维度,以便后续组件能更有效地处理
- Large Language Model (LLM):系统的核心是 Llama-3.1-8B-Instruct模型,它是主要的语言模型,负责直接从处理过的语音输入生成文本响应,全程没有改变它的模型权重
- Speech Decoder:语音解码器是一个添加在 LLM 之后的流式组件,由几个与 LLaMA 相同架构的变换器层组成。它的作用是从 LLM 输出的隐藏状态中生成相应的语音响应的离散单元序列。该模块以非自回归方式运行,作为输入的是来自LLM的输出隐藏状态
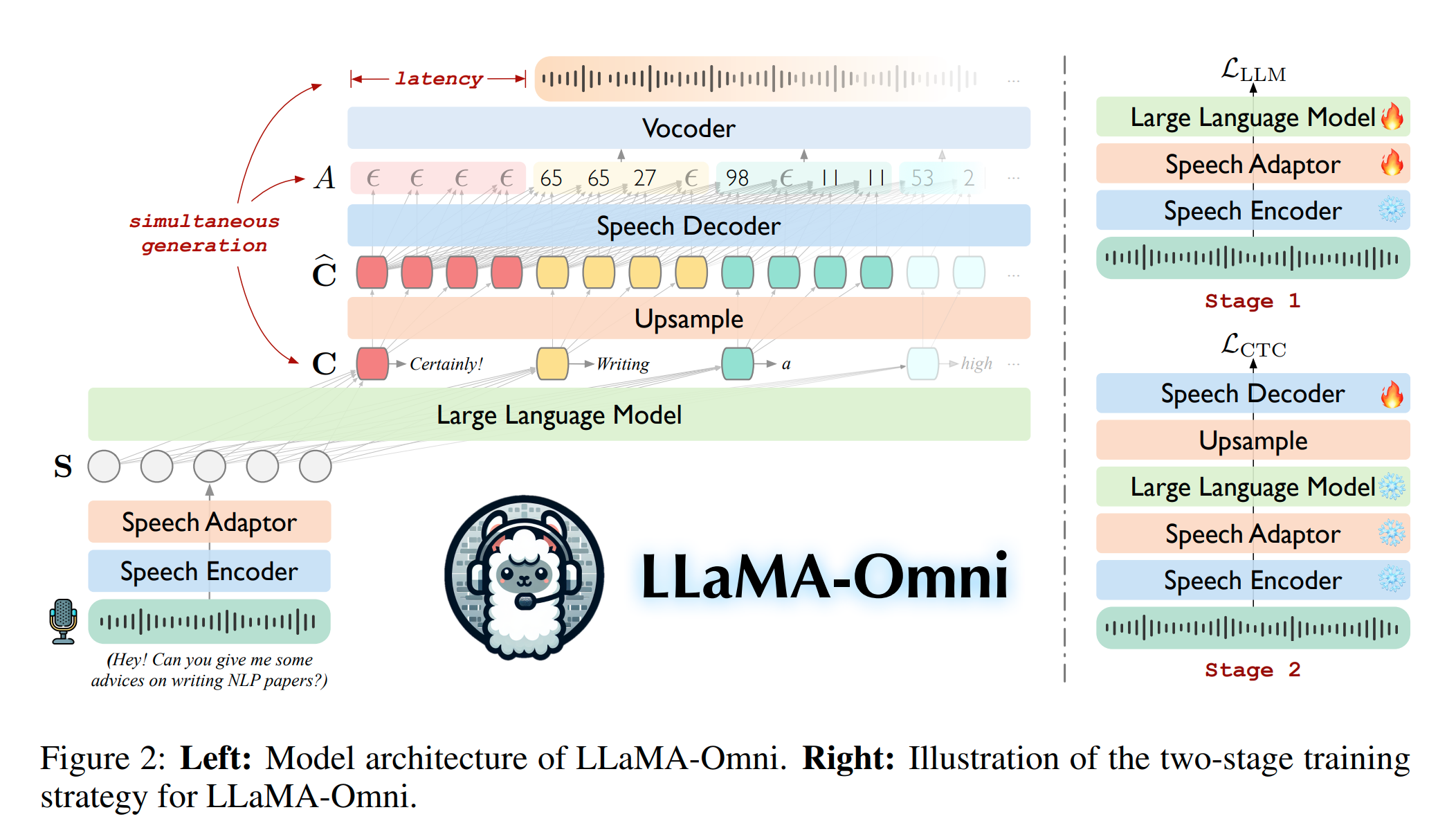
整个架构的设计目的是最小化延迟,允许几乎实时的交互,通过直接从语音指令同时生成文本和语音响应来实现这一点
符号声明:
代表输入, 代表输出,上标 分别代表 speech,text。用户的语音输入为 ,模型的语音和文本输出为
Speech Encoder:
使用 Whisper-large-v3 的编码器作为语音编码器 (Whisper是一个通用的语音识别模型,经过大量音频数据训练)。则通过语音编码器输出为 ,其中 。 为输入语音 compact representation vector length。 Speech Encoder 的参数从头到尾不改变
Speech Adaptor:
由于 Speech Encoder 和 LLM 的参数都没有改变,因此需要一个过渡层来将语音向量映射到 LLM 的 embedding,同时为了高效性,representation vector length 会进一步减少,设计的网络过程为:
- 先进行一步下采样:,其中
- 再通过两个 Linear 层:
LLM:
使用了 Llama-3.1-8B-Instruct,符号记为 ,输入该模型的 prompt 格式如下:

部分就是通过 Speech Adaptor 输出的 embeddings,设 prompt 输入记号为 ,为了训练 speech adaptor,loss 使用 LLM 的输出产生的 loss,设 LLM 自回归(autogressively)产生的文本输出为 ,则 loss 使用交叉熵损失函数:
Speech Decoder:
为了生成 speech response ,论文使用了 audio 的方法将语音离散化为离散单元(discrete unit)。即,先使用预训练的 HuBERT 模型来提取语音的连续表示,然后使用 K-means 模型将这些表示转换为离散的聚类索引。再将连续相同的索引合并成单一单元,得到最终的离散单元序列 ,其中 是聚类的数量,而 是离散单元序列的长度。这些离散单元可以通过附加的基于单元的声码器(vocoder) 转换为声音波形(waveform)。
为了同时生成语音响应和文本响应,论文在 LLM 之后增加了一个流式语音解码器 。它包含几个与LLaMA 相同架构的标准Transformer 层,每层包含一个因果自我注意模块*(causal self-attention)和一个前馈网络。语音解码器以非自回归方式运行,接受来自LLM的输出隐藏状态作为输入,并生成对应的语音响应的离散单元序列。“隐藏状态”表示为:。autogressive 对应 LLM 生成 的过程,这个过程是串行执行的,non-autoregressive 对应 speech decoder 解码 的过程,这个过程是并行执行的
causal self-attention。“causal”指的是因果关系。在 NLP 中,“causal”意味着模型在生成或处理序列中的某个位置时,只能访问该位置之前的信息,而不能看到当前位置及之后的信息。这是为了模拟自然语言生成的真实过程
还有一个实现细节,hidden state 输入给 speech decoder 前需要进行一次上采样,我对这个上采样和下采样的理解:语音模态的数据相对于文本模态的数据存在着大量的噪声和冗余信息,为了将语音模态对齐到文本模态,因此才有这个下采样和上采样
即输入给 vocoder 的数据是隐藏状态数据 经过上采样之后的数据 。然后将 数据输入进 speech decoder ,再将 speech decoder 的输出 输入给 vocoder 即可输出最终的语音模态数据(这个 speech decoder 可以认为和 speech adapter 对齐 LLM 一样的作用,speech decoder 可以认为是来对齐 vocoder 的中间模块)
对齐语音和文本输出:
由于我们需要对齐输出语音数据和文本数据(如果直接将输出的全部文本数据输入 vocoder 肯定会出问题,到时候输出的语音数据和文本数据不对应)
如下图,语音和文本输出数据对齐的可视化可以用颜色来表示
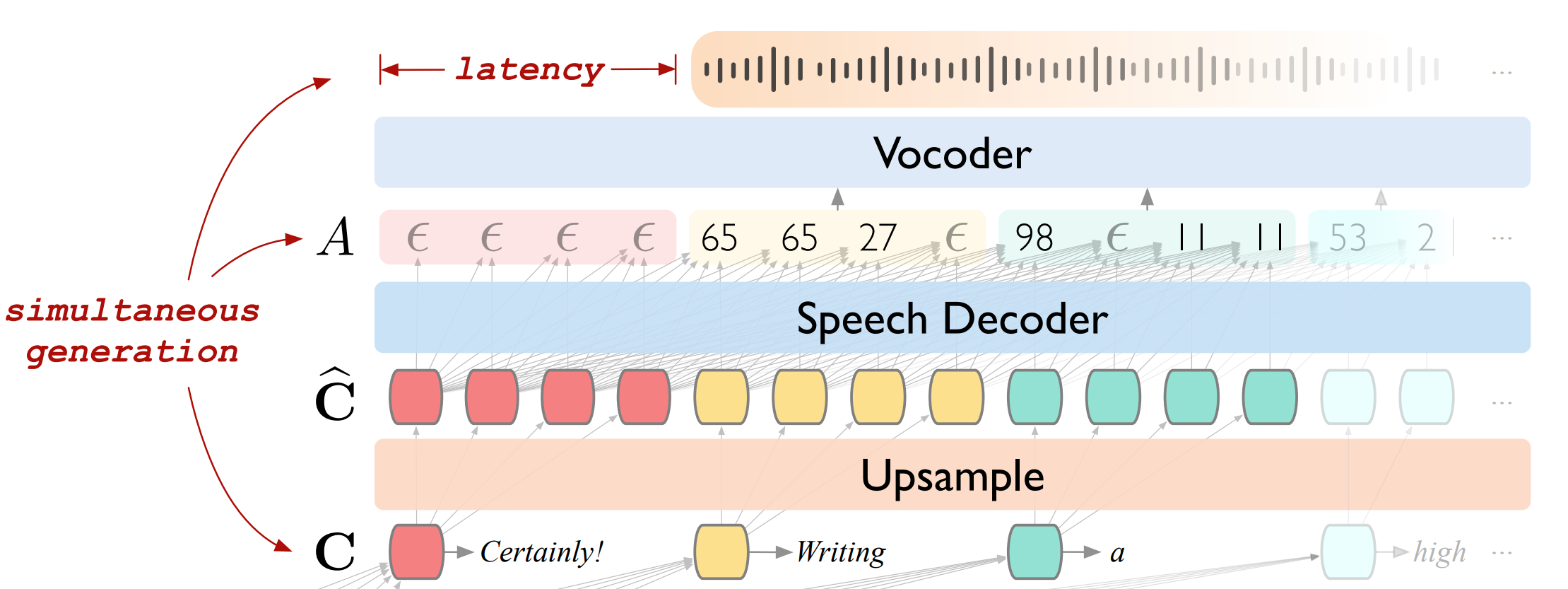
因此使用了一个名为 CTC(connecionist temporal classification)的技术来对齐离散单元序列 ,具体而言,CTC 使用了一个空的 token 来扩展输出维度:
其中 是 Linear 层的参数,输出 是对齐的语音输出,但是如何确保语音输出长度的可变性呢?通过 ,CTC 技术引入了一个 collapsing function ,通过 collaspe 实现可变长的输出:
CTC 模块训练的 loss 设计如下,CTC 会对所有可能的对齐路径求边缘概率(marginalization),loss 被设计为负的对数似然估计:
其中 代表所有的对齐的,可能通过 collapse 成 的序列 。在推理的时候,选取 进行前向传播

inference 阶段的分析:
LLM 根据语音指令 autogressively 生成文本响应。与此同时,由于我们的语音解码器使用了 casual self-attention,LLM 生成了文本的 response prefix ,相应的上采样隐藏状态就可以对齐到 ,输入到语音解码器得到对齐的 ,进而得到对应生成文本前缀的离散单元。当生成的单元数量达到预先定义的 chunk size 时,就将这个单元段输入到 vocoder 中合成语音段落,并立即播放给用户。确保了不受文本响应长度影响的低延迟响应
语音为什么需要流式合成(streaming synthesis)
- 实时性与延迟:语音合成需要尽可能地实时,如果系统在每个字或每个小片段生成后就立即合成并播放语音,可能会导致不流畅的听觉体验
- 平滑度与质量:为了确保合成的语音听起来自然流畅,通常需要处理一定长度的语音数据(比如短期内语调相同)。如果处理的数据过短,可能无法捕捉到语音的完整音节或音调变化