MMEvol论文阅读
MMEvol
论文地址:MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
该论文的工作在于提出 MMEvol 的新框架(有点像教师-学生模型训练方法),一个用于多模态大语言模型(MLLMs)的图像-文本指令数据进化的框架。其主要目标是通过自动化生成开放域的图像-文本指令数据,来增强现有数据集的多样性和复杂性,从而克服手动创建多模态指令数据耗时且低效的问题
MMEvol 框架结合了细粒度感知进化、认知推理进化以及交互进化三个操作,以生成复杂和多样的指令数据。这三个操作通过给MLLM提供特定的提示来实现。由于进化过程中生成的指令偶尔会失败,因此还使用了一个指令消除器来过滤掉不成功的指令。这一进化过程会重复多次,以获得足够数量的涵盖不同复杂度级别的指令数据集。
为什么要进行指令进化?因为目前 SOTA 的多模态大模型不开源数据集,而且直接从商业大模型中 distill prompts 产生的问题是指令过于简单,复杂性和广泛性不高(商业大模型倾向于回答人类的常见问题),因此需要生成 open-domain and complex instructions
为了生成这样数据,作者提出了 MMEvol 框架,包含 instruction evolution 和 instruction elimination,instruction evolution 用于生成更复杂和更具有多样性的指令,instruction elimination 用于过滤掉大模型生成失败的指令(比如错误的回答)
论文提出了三种 evolution directions:
- fine-grained perceptual evolution
- cognitive reasoning evolution
- interactive evolution
论文的启示:高质量的 image-text instruction 数据集对于训练一个多模态大模型的作用非常大
实现方式:
Prefix-Prompt of MMEvol:
Prefix-Prompt 是用于指导 MLLM 生成高质量指令数据的结构,而不是直接用于训练模型的多模态数据。即 Prefix-Prompt 是一种提示结构,它包含了一系列信息,用于指导模型如何生成新的、更复杂的指令数据。

Prefix-Prompt 结构解析
- 顶部区块:提供语境上下文信息,提供关于图像的基本描述以及图像内重要对象的位置信息。这部分信息为模型提供了图像的背景和语境
- 中间区块:列举语言/视觉为中心的原子命题和视觉为中心的操作,声明 Prefix-Prompt 结构在指导模型生成指令数据时的关键要素
- 语言/视觉为中心的原子命题(Language/Centric Atomic Propositions):这部分强调了在生成指令时需要关注的基本命题,这些命题围绕语言和视觉信息展开,包括:Relationship Description Ability,Context Understanding Ability,Behavior Prediction Ability,Knowledge Integration Ability
- 视觉为中心的操作(Vision-Centric Manipulations):通过伪函数调用(pseudo-function calls)来模拟视觉能力,目的是增强模型在生成指令时的视觉推理能力。具体操作包括:
- 定位(grounding):用于识别图像中的特定对象,返回对象的 boundary box
- 参照(referring):用于标识图像中的小而微妙的对象,通过放大感兴趣的区域并返回放大的结果
- 计算(calculate):用于计算图像中指定目标所表示的公式,并返回计算结果
- 光学字符识别(OCR):用于识别图像中自然文本的内容,并返回识别出的文本
- 底部区块:组织好的种子样本:进一步说明组织好的初始指令数据样本,这些样本随后被发送给 MLLM 进行改写(进一步 evolution)
伪函数调用(Pseudo-function Calls)是什么?
Instruction Evolution:
- 细粒度感知进化 Fine-grained Perceptual Evolution:目标是提高视觉理解,充分利用图像中的视觉信息,提供包含更多细节目标的新指令
![Fine-grained Perceptual Evolution]2.png)
- 认知推理进化 Cognitive Reasoning Evolution:目标是增强推理能力,通过增加指令中的推理步骤,进行多步推理,来提高其复杂度,使得模型能够处理更复杂的任务

- 交互进化 Interaction Evolution:目标是增加多样性,通过提供更广泛的指令形式,来提高指令的多样性

我对选择这三种进化的理解:Cognitive Reasoning Evolution 用于图像信息的充分理解,图像信息往往含有比文本信息更大的数据量,需要对图像信息进行"偏心"的训练;Cognitive Reasoning Evolution 用于增强大模型的推理能力,这个目的很显然;Interaction Evolution 可能比较抽象,它用于生成更加广泛的指令
Instruction elimination:
Instruction Elimination 的过程可以用下面步骤来说明:
评估进化后的指令
- 难度与复杂度评估:对进化后的每一条指令进行难度和复杂度的评估。评估时比较进化后的指令与原始指令的难度差异,并通过“yes/no”问题来确定进化后的指令是否在质量上有所提升
- 量化评分:对每条进化后的指令进行量化评分,评分范围为1到10,其中较高的分数表示更高的难度和复杂度
淘汰进化失败的指令
只有评分较高且被标记为“yes”的指令才会被保留
类似于 GAN 的思想,指令的生成-淘汰过程,使用一个模型(如LLaVA-Instruct、ShareGPT4V或其他模型)来生成新的、更复杂的指令数据。用另一个模型或一套评估标准来对生成的指令数据进行评估

通过不断进化-淘汰生成指令,最后得出一个名为 SEED-163K 的训练指令集(seed 的含义是“源”)
自动化与人工监督
虽然评估和淘汰过程可以通过自动化的方式进行,但依然需要一定程度的人工监督来确保评估标准的准确性和公平性。通过设定合理的评分标准和淘汰规则,可以有效地移除那些进化过程中产生的低质量或无效的指令数据,从而提高整体数据集的质量和有效性。
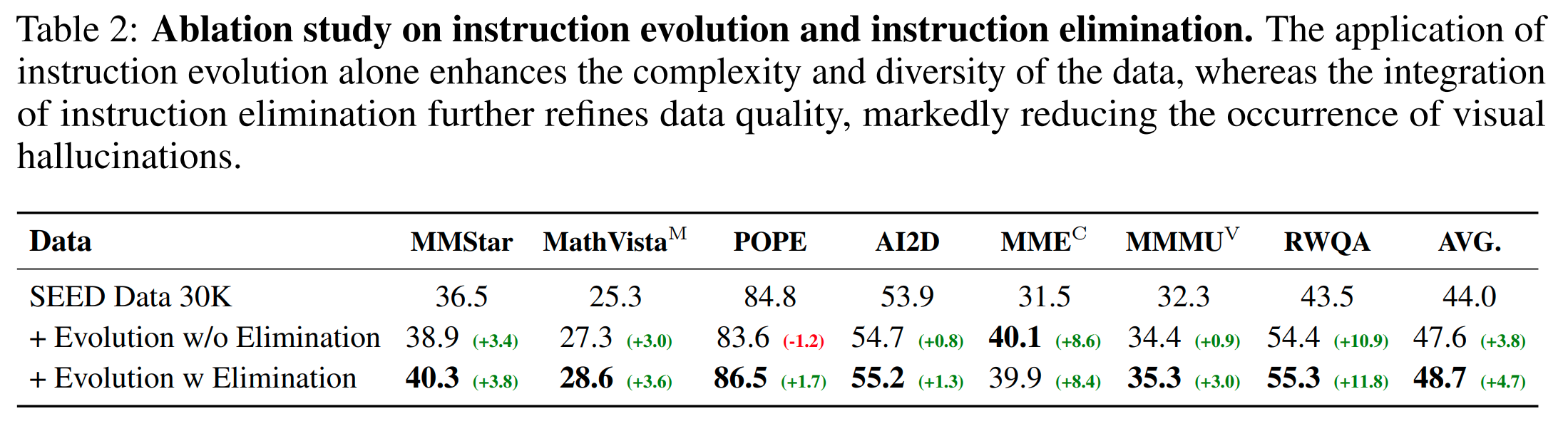
ABLATION STUDY
本文的实验:对七个视觉-语言基准进行了消融实验。仅使用指令进化显著提高了数据的多样性和复杂性,导致在多个视觉-语言基准上的平均性能提高了 3.8。但是缺少指令淘汰会引入失败进化产生的有害数据,在 POPE 上的抗幻觉能力降低了 1.2 。当同时使用指令进化和指令淘汰时,指令淘汰过滤掉了失败进化产生的有害数据,进一步提高了进化数据的质量和密度,进一步提升了 0.9,在抗幻觉能力上提高得尤其多
指令进化提升的可视化:
通过识别生成指令中的动词-名词结构,研究生成指令的类型及其多样性。使用Berkeley神经解析器来解析指令,提取最接近根节点的动词及其第一个直接名词宾语来评估指令。进化后的数据显著提高了指令的多样性,对于视觉信息,粒度感知进化大大改善了长尾部分的视觉对象分布
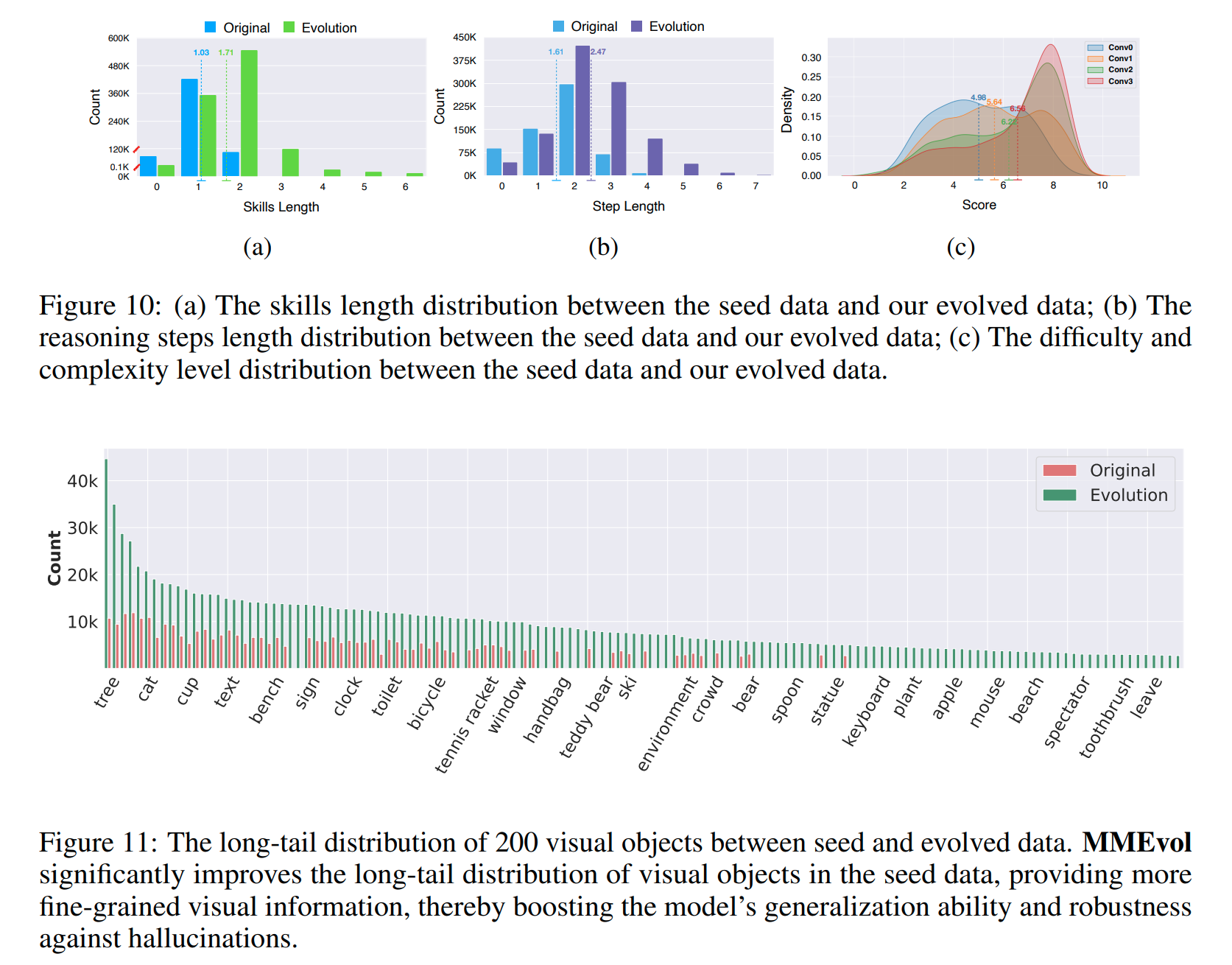
- skills length:评价一条指令涉及到多少个不同的操作或技能
- step length:评价生成的指令中推理或操作步骤的数量。这可以用来衡量指令的复杂度
- score:对生成的每一条指令进行评分,评分范围通常是1到10分,其中较高的分数代表更高的难度和复杂度