合并mmseg的backbone和encoder
合并mmseg的backbone和encoder
问题来源
由于我的这段科研工作主要围绕上下采样同时建模(协同上下采样)来展开的,我在小模型上跑出了很好的效果,想在大模型大数据集上进一步验证他的有效性,我选择了 mask2former 模型作为分割任务的 baseline,我尝试从 mask2former 官方 repo 下载代码后在他上面修改,但是这个代码封装极其深而且工程化,这个仓库是基于一个 detectron2 这个算法框架库开发的,首先解析这个算法框架库就极其耗时,而且由于耦合极其深也不好修改。这时候我发现 mmseg 这个框架库内有 mask2former 模型而且这个框架更好理解一些(但也是耦合太深封装过度),我就决定在 mmseg 这个算法框架下修改代码加入协同算子
这里引出了第二个问题,如果我只是单纯地做一个上采样算子就非常好说了,但是我将上下采样算子同时建模了,而 mmseg 这个框架库实例化模型的时候是将 backbone(ResNet50) 和 encoder(MSDeformableAttentionPixelDecoder) 分别生成的(解耦了),而我的协同算子既不能单独属于 backbone 也不能单独属于 encoder,这就意味着我的 Sampler 需要和 backbone 和 encoder 平级来实例化(因为不想改动最顶层的接口,也就是 EncoderDecoder 类,如果要改最顶层工作量会奇大无比)
因此最终设计是将 backbone 和 sampler,pixel decoder 封装为一个新的 backbone,并将原来的 encoder 内部把 pixel decoder 给除去作为一个新的 decode_head。这样能最大化减少工作量
修改方案实现
我们先看在 mmseg 内部 mask2former 的 Config 配置:
1 | |
对应的论文中网络结构图如下:
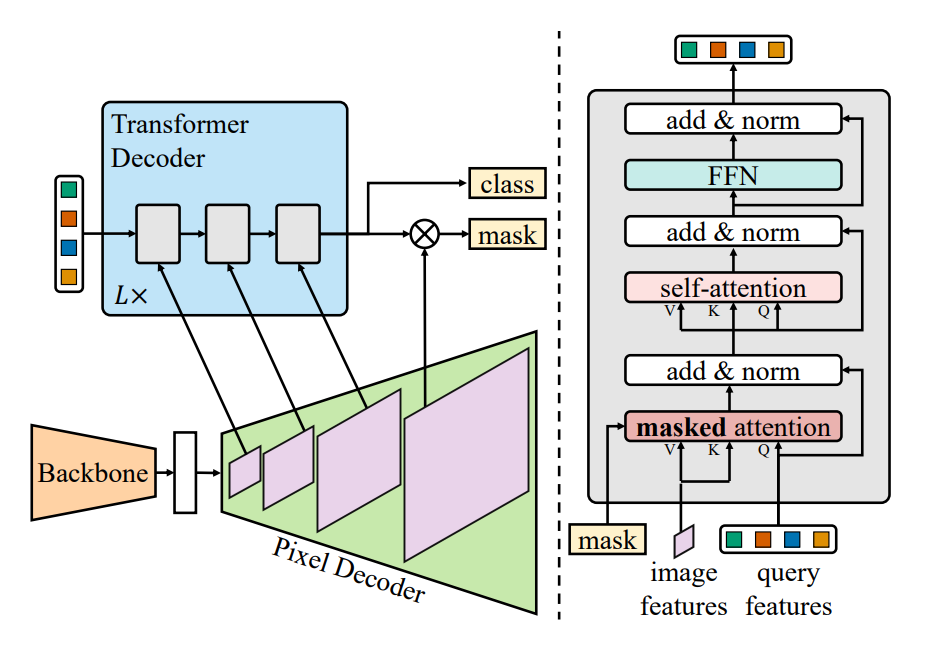
可以看到上面的结构是非常不适合我们修改的,论文把 ResNet 称为 backbone 而不是 ResNet+Pixel Decoder,对应 config 的层级关系是:backbone - Pixel Decoder - Transformer Decoder,而我们需要将 backbone 与 Pixel Decoder 同时考虑进来(因为要加入上下采样管理),因此我们需要的层级关系是 (backbone - Pixel Decoder) - Transformer Decoder,即把 backbone 与 pixel decoder 合起来的一级和 Transformer Decoder 同级
**那么最简单的设计就是把Backbone和Pixel Decoder封装为一个新的Backbone,Transfomer Decoder就当做唯一的Decoder就行了!**修改配置文件结构如下:
1 | |
其中我重写的 ResNetWithPixelDecoder 类如下,其实只要熟悉一下 mmcv 框架写得就会很简单,会用 build_from_cfg 函数就好了:
1 | |
代码经验
- mmcv 框架使用方式自定义模块的一些注意事项:
- 类继承于
BaseModule而不是nn.Module(目的是不改变训练框架的情况下调用父类的初始化函数) - 如果要使用一个
list装内部的多个模块,使用nn.ModuleList而不用List,因为这个涉及build_from_cfg的内部实现,他会遍历模块内部的所有nn.Module对象进行初始化,使用list就不算nn.Module,就不能触发内部的初始化方式 - 创建自定义模块使用
config和registry机制就行了,注意在__init__.py中加上对应的模块
- 类继承于
- 对于陌生的框架,发生了无法理解的错误的话多 debug 一步一步找问题是什么,要学会去看源码(理解工程代码也是一个重要的能力)