torch.autograd.Function解析
pytorch的灵活性体现在它可以任意拓展我们所需要的内容,包括自定义模型(nn.Module)、自定义函数(nn.Function)、自定义损失函数(nn.Module)、自定义求导方式(torch.autograd.Function),本节内容介绍torch.autograd.Function自定义求导的使用方法
为什么需要torch.autograd.Function?虽然pytorch可以自动求导,但是有时候一些操作是不可导的,这时候你需要自定义求导方式
使用模板:
- 继承
torch.autograd.Function: 自定义的类需要继承自torch.autograd.Function。这样,你的类就可以使用PyTorch自动微分系统提供的所有功能
- 定义前向传播逻辑: 自定义函数必须实现一个
forward方法,该方法定义了如何计算输入张量的输出。这个方法中可以定义任何需要的操作,并且返回输出结果,注意要保存信息
- 定义反向传播逻辑: 自定义函数必须实现一个
backward方法,该方法是反向传播的核心,定义了如何根据输出张量的梯度来计算输入张量的梯度。backward方法通常接收一个参数,输出张量的梯度,并返回输入张量的梯度
- 创建并使用自定义函数: 在定义了
forward和backward方法之后,你可以创建自定义函数的实例,并像使用普通的PyTorch操作一样使用它。当你调用这个实例的apply方法时,它会执行前向传播,并返回输出张量。在反向传播时,PyTorch会自动调用你的backward方法
事例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import torch
class MyCustomFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input1, input2):
ctx.save_for_backward(input1, input2)
output = input1 * input2
return output
@staticmethod
def backward(ctx, grad_output):
input1, input2 = ctx.saved_tensors
grad_input1 = grad_output * input2
grad_input2 = grad_output * input1
return grad_input1, grad_input2
x1 = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
x2 = torch.tensor([4.0, 6.0, 7.0], requires_grad=True)
custom_op = MyCustomFunction.apply
y = custom_op(x)
print(y)
y.backward(torch.ones_like(y))
print(x.grad)
|
解析含义:
- 该代码可以与正常的其他 Pytorch 模块融合使用,而不产生任何副作用,这部分代码只会影响自定义的这部分梯度传播
ctx为一个上下文管理器,他负责保存前向传播的信息,用于反向传播,需要记住ctx.save_for_backward和ctx.saved_tensors的用法- 使用
@staticmethod装饰器是为了定义一个静态方法。静态方法不需要一个类实例就可以被调用,而且它不会自动传递实例(self)或类(cls)作为第一个参数。在torch.autograd.Function的上下文中,这正是我们需要的,因为我们希望forward和backward方法能够独立于类的任何实例而被调用
return grad_input1, grad_input2会在后续反向传播过程中返回上一级计算图(这个过程是隐藏的),知道达到源节点(对应输入顺序input1,input2)
为什么使用 staticmethod:
自定义 torch.autograd.Function 类时,使用 staticmethod 而不是实例方法,是为了简化函数的调用过程,并且不需要在每次调用时创建类的实例。当使用静态方法 (@staticmethod) 时,调用 forward 和 backward 方法不需要访问类实例的状态(就像我们在 Pytorch 内调用 Sigmoid 函数从来没有过创建实例)
.apply方法:
.apply 是一个特殊的方法,用于调用自定义的 torch.autograd.Function。当定义了一个自定义的 autograd.Function 类之后,需要通过 .apply 方法来实例化并调用这个类。.apply 方法确保了你在前向传播过程中保存的所有信息都可以在反向传播过程中被正确使用
应用实例1:ReLU函数的反向求导:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import torch
from torch import nn
from torch.autograd import Function
import torch
class MyReLU(Function):
@staticmethod
def forward(ctx, input_):
ctx.save_for_backward(input_)
output = input_.clamp(min=0)
return output
@staticmethod
def backward(ctx, grad_output):
input_, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input_ < 0] = 0
return grad_input
x = torch.rand(4,3,5,5)
myrelu = MyReLU.apply
output = myrelu(x)
print(output.shape)
|
应用实例2:自定义反向传播函数:
在实际情况中,我遇到过想要通过把权值全部化为 -1,0,1 三个值,以实现高效计算效率的情况,于是我自定义了一个类似于 Sigmoid 函数将阶梯函数平滑化,一个简单的想法就是把两个 Sigmoid 函数用一个斜率很小的线性函数拼起来:
f(x)=⎩⎪⎪⎨⎪⎪⎧−1+e−x−5e−x−5 x<−50.1x −5≤x<51+ex−5ex−5 x≥5
函数图像如下所示:
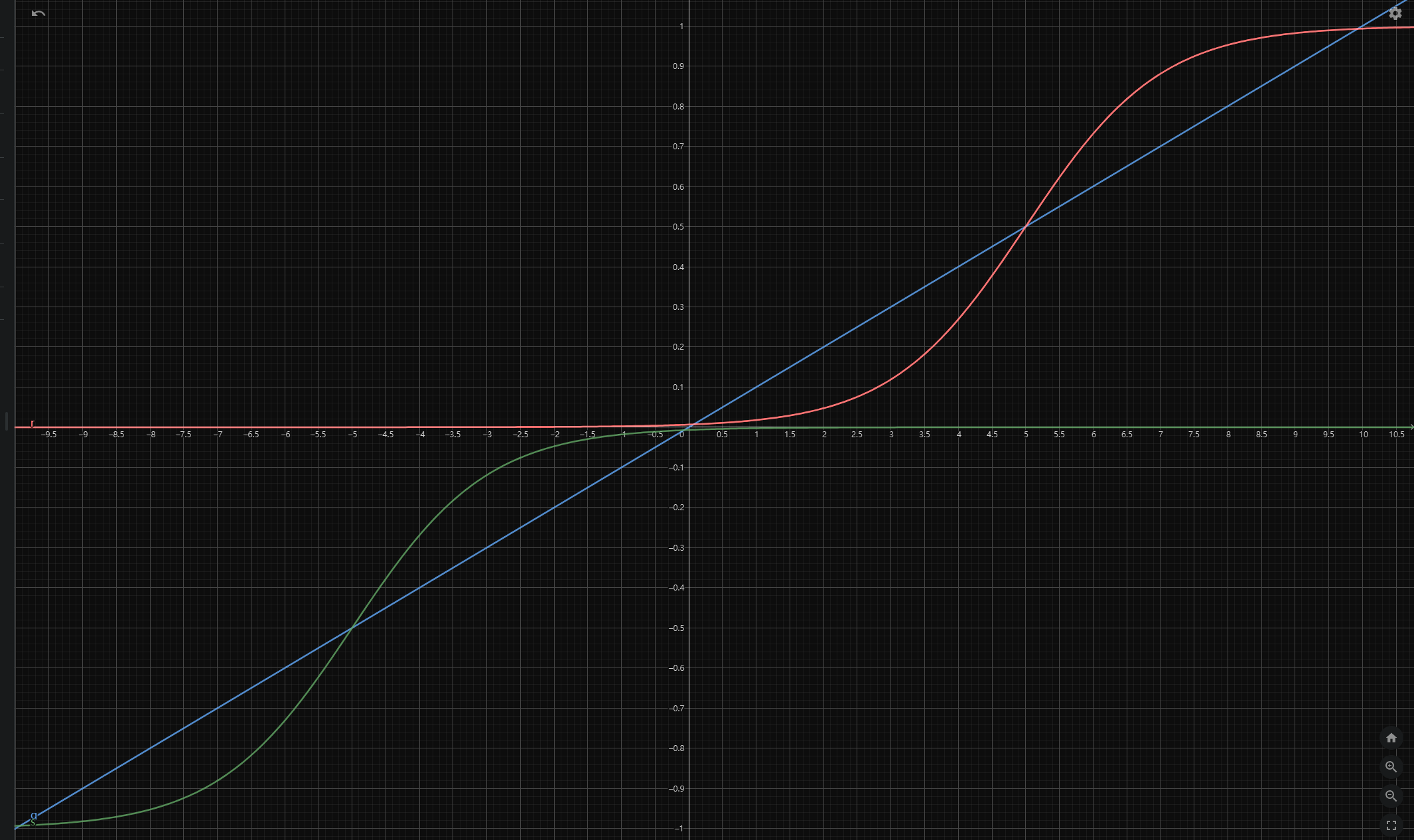
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| import torch
from torch.autograd import Function
class CustomActivation(Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
result = torch.zeros_like(x)
mask_lt = x < -5
mask_between = (x >= -5) & (x < 5)
mask_ge = x >= 5
result[mask_lt] = -torch.sigmoid(-x[mask_lt] - 5)
result[mask_between] = 0.1 * x[mask_between]
result[mask_ge] = torch.sigmoid(x[mask_ge] - 5)
return result
@staticmethod
def backward(ctx, grad_output):
x, = ctx.saved_tensors
grad_input = torch.zeros_like(x)
mask_lt = x < -5
mask_between = (x >= -5) & (x < 5)
mask_ge = x >= 5
grad_input[mask_lt] = (
-torch.exp(-x[mask_lt] - 5) /
(1 + torch.exp(-x[mask_lt] - 5))**2
) * grad_output[mask_lt]
grad_input[mask_between] = 0.1 * grad_output[mask_between]
grad_input[mask_ge] = (
torch.exp(x[mask_ge] - 5) /
(1 + torch.exp(x[mask_ge] - 5))**2
) * grad_output[mask_ge]
return grad_input
custom_activation = CustomActivation.apply
x = torch.tensor([-10, -6, -3, 0, 2, 4, 6, 10], requires_grad=True)
y = custom_activation(x)
print('Forward Pass Output:', y)
y.sum().backward()
print('Gradient:', x.grad)
|
需要注意的点:
- 在
backward 方法中使用 ctx.saved_tensors 时,它总是返回一个元组,即使你只保存了一个张量,也要使用解包语法来获取保存的张量:使用 x, = ctx.saved_tensors 而不是 x = ctx.saved_tensors
mask_lt = x < -5 是一个 bool 类型的 torch.Tensor,上面代码使用通过布尔索引来实现分段函数的输出