CNN在视觉识别任务上取得了显着的成功。尽管如此,它们仍然存在上述两个缺点。它们对几何变换建模的能力主要来自于广泛的数据增强、大的模型容量和一些简单的手工制作的模块(例如,用于小平移不变性的最大池化)。
DCNv1
CNN 本质上仅限于对大型未知变换进行建模。该限制源于 CNN 模块的固定几何结构:卷积单元在固定位置对输入特征图进行采样;池化层以固定比例降低空间分辨率; RoI(感兴趣区域)池化层将 RoI 分成固定的spatial bins等。缺乏处理几何变换的内部机制。
在可变形卷积中,引入了两个新模块,它们极大地增强了 CNN 建模几何变换的能力。

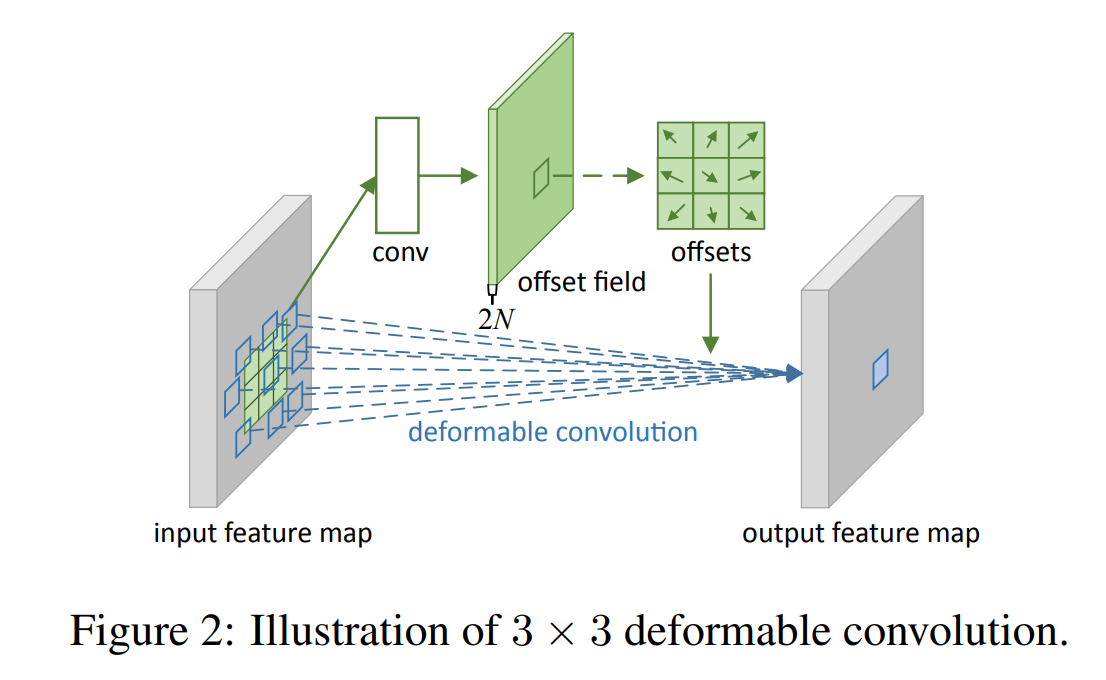
以 3∗3 卷积为例,设 R={(−1,−1),(−1,0),…,(0,1),(1,1)},则卷积和 DCN 可以表示为:
Convolution:y(p0)=Pn∈R∑w(pn)⋅x(p0+pn)deformable conv(v1):y(p0)=Pn∈R∑w(pn)⋅x(p0+pn+Δpn)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import torch
import torch.nn as nn
from torchvision.ops import deform_conv2d
class DeformConv1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__()
self.offset_conv = nn.Conv2d(in_channels, 2 * kernel_size * kernel_size, kernel_size, stride, padding)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
def forward(self, x):
offset = self.offset_conv(x)
x = deform_conv2d(x, offset, self.conv.weight, self.conv.bias,
stride=self.conv.stride, padding=self.conv.padding,
dilation=self.conv.dilation, groups=self.conv.groups)
return x
|
DCNv2
DCNv1存在弊端:通过 PASCAL VOC 图像中偏移采样位置的排列将感受野引起的变化可视化。研究发现,激活单元的样本倾向于聚集在它所在的对象周围。然而,对象的覆盖范围并不精确,样本分布超出了感兴趣的区域:

deformable conv(v2):y(p0)=Pn∈R∑w(pn)⋅x(p0+pn+Δpn)⋅Δmk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import torch
import torch.nn as nn
from torchvision.ops import deform_conv2d
class DeformConv2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__()
self.offset_conv = nn.Conv2d(in_channels, 2 * kernel_size * kernel_size, kernel_size, stride, padding)
self.mask_conv = nn.Conv2d(in_channels, kernel_size * kernel_size, kernel_size, stride, padding)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
def forward(self, x):
offset = self.offset_conv(x)
mask = self.mask_conv(x).sigmoid()
x = deform_conv2d(x, offset, self.conv.weight, self.conv.bias, mask=mask,
stride=self.conv.stride, padding=self.conv.padding,
dilation=self.conv.dilation, groups=self.conv.groups)
return x
|
DCNv3
V2虽然类比于传统CNN在性能有所提升,但是对比Transformer还是有所差距。近年来大规模视觉变换器(ViT)的巨大进步相比,基于卷积神经网络(CNN)的大规模模型仍处于早期状态。为了弥补 CNN 和 ViT 之间的差距,我们首先从两个方面总结它们的差异:
DCNv3:
- 借鉴了可分离卷积的想法,并将原始卷积权重 wk 分离为深度部分和逐点部分,其中深度部分由原始位置感知调制标量 mk 负责,逐点部分是采样点之间共享的投影权重 w
- 引入多组(groups)机制
- 沿采样点标准化调制标量
deformable conv(v3):y(p0)=g=1∑GPn∈R∑wg⋅mgk⋅xg(p0+pn+Δpn)