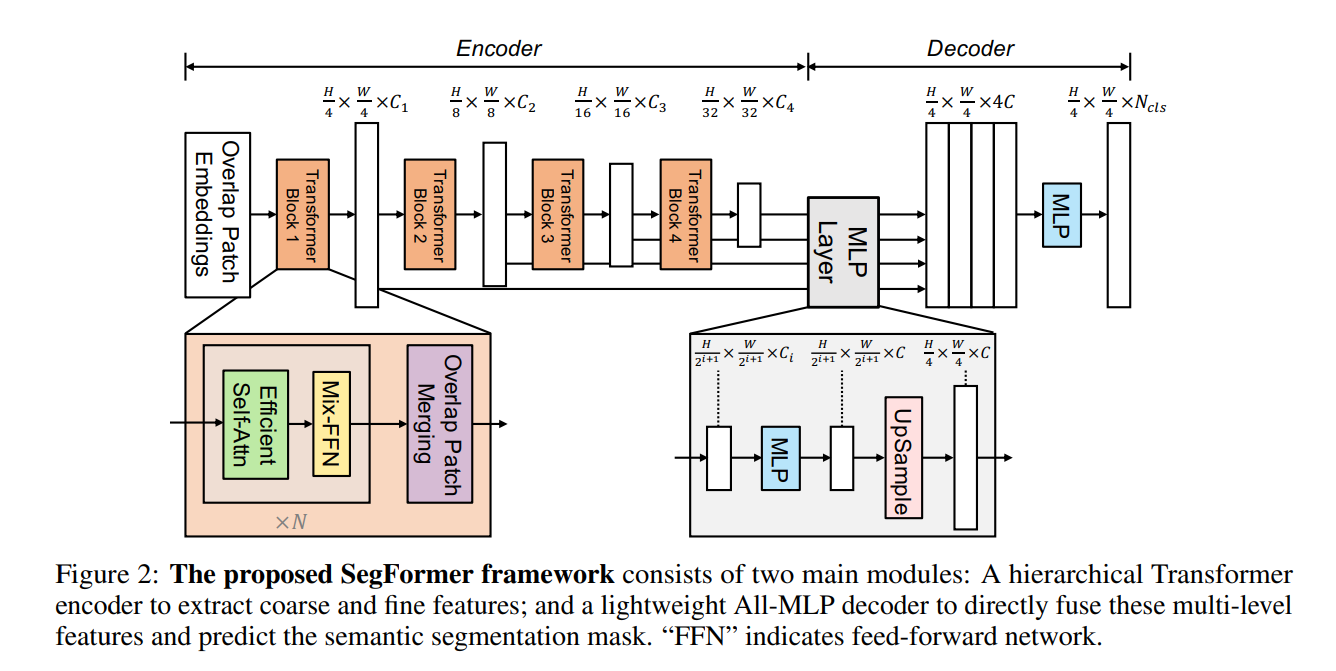
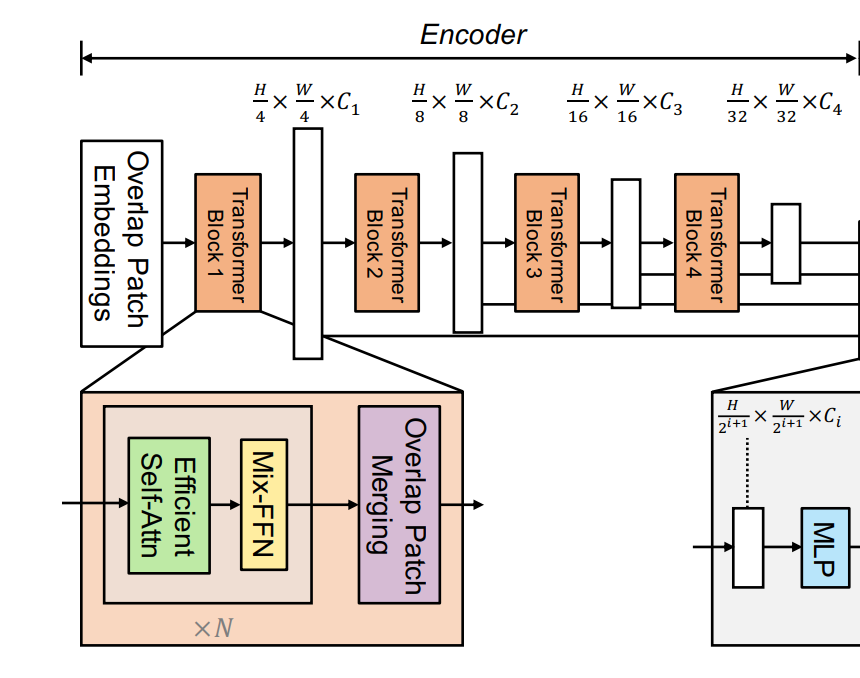
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
| from math import sqrt
from functools import partial
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, reduce
from einops.layers.torch import Rearrange
def exists(val):
return val is not None
def cast_tuple(val, depth):
return val if isinstance(val, tuple) else (val,) * depth
class DsConv2d(nn.Module):
def __init__(self, dim_in, dim_out, kernel_size, padding, stride=1, bias=True):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size=kernel_size, padding=padding, stride=stride, bias=bias),
nn.Conv2d(dim_in, dim_out, kernel_size=1, bias=bias)
)
def forward(self, x):
return self.net(x)
class LayerNorm(nn.Module):
def __init__(self, dim, eps = 1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
std = torch.var(x, dim = 1, unbiased = False, keepdim = True).sqrt()
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) / (std + self.eps) * self.g + self.b
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = LayerNorm(dim)
def forward(self, x):
return self.fn(self.norm(x))
"""
下面是Segformer的核心部分
"""
class EfficientSelfAttention(nn.Module):
def __init__(self, *, dim, heads, reduction_ratio):
super().__init__()
self.scale = (dim // heads) ** -0.5
self.heads = heads
self.to_q = nn.Conv2d(dim, dim, 1, bias=False)
self.to_k = nn.Conv2d(dim, dim, reduction_ratio, stride=reduction_ratio, bias=False)
self.to_v = nn.Conv2d(dim, dim, reduction_ratio, stride=reduction_ratio, bias=False)
self.to_out = nn.Conv2d(dim, dim, 1, bias=False)
def forward(self, x):
h, w = x.shape[-2:]
heads = self.heads
q, k, v = (self.to_q(x), self.to_k(x), self.to_v(x))
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = heads), (q, k, v))
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
attn = sim.softmax(dim=-1)
out = einsum('b i j, b j d -> b i d', attn, v)
out = rearrange(out, '(b h) (x y) c -> b (h c) x y', h=heads, x=h, y=w)
return self.to_out(out)
class MixFeedForward(nn.Module):
def __init__(self, *, dim, expansion_factor):
super().__init__()
hidden_dim = dim * expansion_factor
self.net = nn.Sequential(
nn.Conv2d(dim, hidden_dim, 1),
DsConv2d(hidden_dim, hidden_dim, 3, padding=1),
nn.GELU(),
nn.Conv2d(hidden_dim, dim, 1)
)
def forward(self, x):
return self.net(x)
"""
MixVision Transformer
结合了 CNN 和 Transformer 的优势,用于高效地提取图像的多尺度特征
就是整个模型的 encoder 部分
"""
class MiT(nn.Module):
def __init__(self, *, channels, dims, heads, ff_expansion, reduction_ratio, num_layers):
super().__init__()
stage_kernel_stride_pad = ((7, 4, 3), (3, 2, 1), (3, 2, 1), (3, 2, 1))
dims = (channels, *dims)
dim_pairs = list(zip(dims[:-1], dims[1:]))
self.stages = nn.ModuleList([])
for (dim_in, dim_out), (kernel, stride, padding), num_layers, ff_expansion, heads, reduction_ratio in zip(dim_pairs, stage_kernel_stride_pad, num_layers, ff_expansion, heads, reduction_ratio):
get_overlap_patches = nn.Unfold(kernel, stride = stride, padding = padding)
overlap_patch_embed = nn.Conv2d(dim_in * kernel ** 2, dim_out, 1)
layers = nn.ModuleList([])
for _ in range(num_layers):
layers.append(nn.ModuleList([
PreNorm(dim_out, EfficientSelfAttention(dim = dim_out, heads = heads, reduction_ratio = reduction_ratio)),
PreNorm(dim_out, MixFeedForward(dim = dim_out, expansion_factor = ff_expansion)),
]))
self.stages.append(nn.ModuleList([
get_overlap_patches,
overlap_patch_embed,
layers
]))
def forward(self, x, return_layer_outputs = False):
h, w = x.shape[-2:]
layer_outputs = []
for (get_overlap_patches, overlap_embed, layers) in self.stages:
x = get_overlap_patches(x)
num_patches = x.shape[-1]
ratio = int(sqrt((h * w) / num_patches))
x = rearrange(x, 'b c (h w) -> b c h w', h = h//ratio)
x = overlap_embed(x)
for (attn, ff) in layers:
x = attn(x) + x
x = ff(x) + x
layer_outputs.append(x)
ret = x if not return_layer_outputs else layer_outputs
return ret
class Segformer(nn.Module):
def __init__(
self,
*,
dims = (32, 64, 160, 256),
heads = (1, 2, 5, 8),
ff_expansion = (8, 8, 4, 4),
reduction_ratio = (8, 4, 2, 1),
num_layers = 2,
channels = 3,
decoder_dim = 256,
num_classes = 4
):
super().__init__()
dims, heads, ff_expansion, reduction_ratio, num_layers = map(partial(cast_tuple, depth=4), (dims, heads, ff_expansion, reduction_ratio, num_layers))
assert all([*map(lambda t: len(t) == 4, (dims, heads, ff_expansion, reduction_ratio, num_layers))]),\
'only four stages are allowed, all keyword arguments must be either a single value or a tuple of 4 values'
self.mit = MiT(
channels = channels,
dims = dims,
heads = heads,
ff_expansion = ff_expansion,
reduction_ratio = reduction_ratio,
num_layers = num_layers
)
self.to_fused = nn.ModuleList([nn.Sequential(
nn.Conv2d(dim, decoder_dim, 1),
nn.Upsample(scale_factor = 2 ** i)
) for i, dim in enumerate(dims)])
self.to_segmentation = nn.Sequential(
nn.Conv2d(4 * decoder_dim, decoder_dim, 1),
nn.Conv2d(decoder_dim, num_classes, 1),
)
def forward(self, x):
layer_outputs = self.mit(x, return_layer_outputs = True)
fused = [to_fused(output) for output, to_fused in zip(layer_outputs, self.to_fused)]
fused = torch.cat(fused, dim = 1)
return self.to_segmentation(fused)
|