Q-learning 算法中,我们存储每个状态下所有动作的 Q Q Q Q ( s , a ) Q(s, a) Q ( s , a ) s s s a a a
当处理大规模 MDP 或者连续状态空间时,采用的方式往往是参数化值函数估计的方式:
V θ ( s ) ≈ V π ( s ) , Q θ ( s , a ) ≈ Q π ( s , a ) V_\theta(s) \approx V^\pi(s), \quad Q_\theta(s,a) \approx Q^\pi(s,a)
V θ ( s ) ≈ V π ( s ) , Q θ ( s , a ) ≈ Q π ( s , a )
其中这时候就采用了从函数的级别去近似,而不是对维护一张表的级别近似,这里提出两个核心的问题来加深理解
这里先要明确强化学习中收集的数据有两个特点:时变性与非稳定性
我们考虑时变性:策略在迭代过程中,由于策略的改变,占用度量也会发生改变。使用梯度下降法的参数化模型,可以有利于模型适应新的数据(梯度下降法的灾难性遗忘的问题反而变成了它的优势了 )。
同时参数化还有一个好处在于可以将可见的状态泛化到没见过的状态上 ,而参数化模型比树模型的泛化能力更强更适合
我们知道 off-policy 算法有两种策略,行为策略和目标策略,我们使用参数化值函数近似是为了在决策过程中对状态的估计。行为策略的目的是为了探索新的数据(explore),而目标策略才是真正需要去近似的东西。因此选择目标策略的估计而非行为策略
根据我们的学习目标来确定损失函数,学习目标:找到参数向量 θ \theta θ
J ( θ ) = E π [ 1 2 ( V π ( s ) − V θ ( s ) ) 2 ] ⇒ − ∂ J ( θ ) ∂ θ = E π [ ( V π ( s ) − V θ ( s ) ) ∂ V θ ( s ) ∂ θ ] θ ← θ − α ∂ J ( θ ) ∂ θ = θ + α ( V π ( s ) − V θ ( s ) ) ∂ V θ ( s ) ∂ θ J(\theta) = \mathbb{E}_\pi \left[ \frac{1}{2} \left( V^{\pi}(s) - V_{\theta}(s) \right)^2 \right] \\
\Rightarrow -\frac{\partial J(\theta)}{\partial \theta} = \mathbb{E}_{\pi} \left[ \left( V^{\pi}(s) - V_{\theta}(s) \right) \frac{\partial V_{\theta}(s)}{\partial \theta} \right] \\
\theta \leftarrow \theta - \alpha \frac{\partial J(\theta)}{\partial \theta}
= \theta + \alpha \left( V^{\pi}(s) - V_{\theta}(s) \right) \frac{\partial V_{\theta}(s)}{\partial \theta}
J ( θ ) = E π [ 2 1 ( V π ( s ) − V θ ( s ) ) 2 ] ⇒ − ∂ θ ∂ J ( θ ) = E π [ ( V π ( s ) − V θ ( s ) ) ∂ θ ∂ V θ ( s ) ] θ ← θ − α ∂ θ ∂ J ( θ ) = θ + α ( V π ( s ) − V θ ( s ) ) ∂ θ ∂ V θ ( s )
此事还需要估计真实的 V π ( s ) V^\pi(s) V π ( s )
θ ← { θ + α ( 1 n ∑ i = 1 n g i − V θ ( s ) ) ∂ V θ ( s ) ∂ θ θ + α ( r t + γ V θ ( s t + 1 ) − V θ ( s ) ) ∂ V θ ( s ) ∂ θ \theta \leftarrow
\left\{ \begin{array}{c}
\theta + \alpha \left( \frac{1}{n}\sum_{i=1}^n g_i - V_{\theta}(s) \right) \frac{\partial V_{\theta}(s)}{\partial \theta} \\
\theta + \alpha \left( r_t + \gamma V_\theta(s_{t+1}) - V_{\theta}(s) \right) \frac{\partial V_{\theta}(s)}{\partial \theta} \\
\end{array} \right.
θ ← { θ + α ( n 1 ∑ i = 1 n g i − V θ ( s ) ) ∂ θ ∂ V θ ( s ) θ + α ( r t + γ V θ ( s t + 1 ) − V θ ( s ) ) ∂ θ ∂ V θ ( s )
Q-learning
由于 DQN 的环境是会实时改变的,在更新网络参数的同时目标也在不断地改变,这非常容易造成神经网络训练的不稳定性。为了解决这一问题,DQN 便使用了目标网络( target network)的思想: 既然在训练过程中 Q 网络的不断更新会导致目标不断发生改变,不如暂时先将 TD 误差目标中 的 Q 网络固定住。为了实现这一思想,我们需要利用两套 Q 网络
同时我们考虑神经网络输入什么输出什么:
一种方法是:神经网络的输入是状态 s s s a a a s s s a a a
若动作是离散(有限)的,还可以只将状态 s s s Q Q Q 通常 DQN(以及 Q-learning)只能处理动作离散的情况 ,因为在函数 Q 的更新过 程中有 m a x a max_a m a x a
优化过程如下,第 i i i
L i ( θ i ) = E ( s , a , r , s ′ ) ∼ U ( D ) [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ i − ) ) ⏟ 目标Q值 − Q ( s , a ; θ i ) ⏟ 预测Q值 ] 2 L_i(\theta_i) = \mathbb{E}_{(s,a,r,s') \sim U(D)} \left[ \underbrace{\left(r + \gamma \max_{a'} Q(s', a'; \theta_i^-)\right)}_{\text{目标Q值}} - \underbrace{Q(s, a; \theta_i)}_{\text{预测Q值}} \right]^2
L i ( θ i ) = E ( s , a , r , s ′ ) ∼ U ( D ) ⎣ ⎢ ⎢ ⎢ ⎡ 目标 Q 值 ( r + γ a ′ max Q ( s ′ , a ′ ; θ i − ) ) − 预测 Q 值 Q ( s , a ; θ i ) ⎦ ⎥ ⎥ ⎥ ⎤ 2
θ i \theta_i θ i i i i θ i − \theta_i^- θ i − θ i \theta_i θ i C C C ( s , a , r , s ′ ) ∼ U ( D ) (s,a,r,s') \sim U(D) ( s , a , r , s ′ ) ∼ U ( D ) D D D
有几点概念需要强调:
目标网络参数 θ i − \theta_i^- θ i − C C C ,其作用包括:
避免目标值剧烈波动:若目标网络与当前网络参数同步更新(θ i − = θ i \theta_i^- = \theta_i θ i − = θ i Q Q Q θ i − \theta_i^- θ i − C C C
缓解自举偏差:同步更新会导致目标网络与当前网络高度相关,可能放大Q值的高估误差(如“过乐观估计”)。延迟更新通过参数滞后性打破这种耦合,减少误差累积
在一般的有监督学习中,假设训练数据是独立同分布的,每一个训练数 据会被使用多次在原来的 Q-learning 算法中,每一个数据只会用来更新一次Q 值。同样地 DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、 下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练
使样本满足独立假设。在MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。采用经验回放可以一定程度上打破样本之间的相关性
提高样本效率。每一个样本可以被使用多次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 import randomimport gymnasium as gymimport numpy as npimport collectionsfrom tqdm import tqdmimport torchimport torch.nn.functional as Fimport matplotlib.pyplot as pltclass ReplayBuffer (object ):''' 经验回放池 ''' def __init__ (self, capacity ):def add (self, state, action, reward, next_state, done ): def sample (self, batch_size ): zip (*transitions)return np.array(state), action, reward, np.array(next_state), donedef size (self ): return len (self.buffer)class Qnet (torch.nn.Module):def __init__ (self, state_dim, hidden_dim, action_dim ):super (Qnet, self).__init__()def forward (self, x ):return self.fc2(x)class DQN (object ):''' DQN算法 ''' def __init__ (self, state_dim, hidden_dim, action_dim, learning_rate, gamma, epsilon, target_update, device ):0 def take_action (self, state ): if np.random.random() < self.epsilon:else :float ).to(self.device)return actiondef update (self, transition_dict ):'states' ], dtype=torch.float ).to(self.device)'actions' ]).view(-1 , 1 ).to(self.device)'rewards' ], dtype=torch.float ).view(-1 , 1 ).to(self.device)'next_states' ], dtype=torch.float ).to(self.device)'dones' ], dtype=torch.float ).view(-1 , 1 ).to(self.device)1 , actions) max (1 )[0 ].view(-1 , 1 )1 - dones) if self.count % self.target_update == 0 :1 2e-3 500 128 0.98 0.01 10 10000 500 64 "cuda" ) if torch.cuda.is_available() else torch.device("cpu" )'CartPole-v1' 0 )0 )0 )0 ]for i in range (10 ):with tqdm(total=int (num_episodes / 10 ), desc='Iteration %d' % i) as pbar:for i_episode in range (int (num_episodes / 10 )):0 0 ]False while not done:if replay_buffer.size() > minimal_size:'states' : b_s,'actions' : b_a,'next_states' : b_ns,'rewards' : b_r,'dones' : b_dif (i_episode + 1 ) % 10 == 0 :'episode' :'%d' % (num_episodes / 10 * i + i_episode + 1 ),'return' :'%.3f' % np.mean(return_list[-10 :])1 )list (range (len (return_list)))'Episodes' )'Returns' )'DQN on {}' .format (env_name))
普通的 DQN 算法通常会导致对 Q 值的过高估计(overestimation)。原因在与 Q 网络的自举(bootstrapping):
传统 DQN 优化的 TD 误差目标为:
r + γ max a ′ ∈ A Q w − ( s ′ , a ′ ) r+\gamma \max_{a'\in A}Q_{w^-}(s',a')
r + γ a ′ ∈ A max Q w − ( s ′ , a ′ )
其中,max a ′ Q w − ( s ′ , a ′ ) \max_{a'}Q_{w-}(s',a') max a ′ Q w − ( s ′ , a ′ ) w − w^- w − max \max max
选取状态 s ′ s' s ′ a ∗ = arg max a ′ Q a^*=\arg \max_{a'}Q a ∗ = arg max a ′ Q
再计算该动作对应的价值 Q w − ( s ′ , a ′ ) Q_{w^-}(s', a') Q w − ( s ′ , a ′ )
当这两部分共同采用同一套 Q 网络的时候,每次得到的都是神经网络中估算所有动作状态的最大值 ,考虑神经网络会不断累计正误差,DQN 的过高估计问题会非常严重,本质上的原因在于:
探索不足:探索不足导致产生的样本无法反应出概率分布: π : p ( s ′ , r ∣ s , a ) \pi:p\left( s',r {\mid} s,a \right) π : p ( s ′ , r ∣ s , a )
值函数存在方差: Q ( s , a ) Q(s,a) Q ( s , a )
贪心思想将高估的值进行了传递 :训练过程中,实际的 Q ( s ′ , a ′ ) Q\left( s',a' \right) Q ( s ′ , a ′ ) Q ∗ ( s ′ , a ′ ) Q^{*}\left( s',a' \right) Q ∗ ( s ′ , a ′ ) Q ( s , a ) Q(s,a) Q ( s , a ) s ′ s' s ′ max a ′ Q ( s ′ , a ′ ) \max_{a'}Q\left( s',a' \right) max a ′ Q ( s ′ , a ′ )
为了解决这一问题,Double DQN 算法提出利用两套独立训练的神经网络来估算 max a ‘’ Q ∗ ( s ′ , a ′ ) \max\limits_{ a‘’}Q^*\left(s', a' \right) a ‘ ’ max Q ∗ ( s ′ , a ′ ) 利用 一套神经网络 Q ω Q_{\omega} Q ω Q a r Q_{ar} Q a r 。这样即使其中一套神经网络的某个动作存在比较严重的过高估计问题,由于另一套神经网络的存在,这个动作最终使用的 Q Q Q
我们设选取动作网络参数为 w w w w − w^- w −
r + γ Q w − ( s ′ , arg max a ′ Q w ( s ′ , a ′ ) ) r+\gamma Q_{w^-}(s', \arg\max_{a'}Q_{w}(s', a'))
r + γ Q w − ( s ′ , arg a ′ max Q w ( s ′ , a ′ ) )
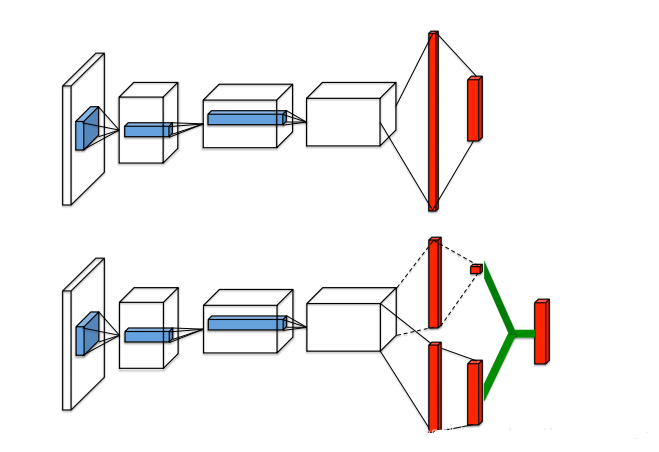
Dueling DQN是 DQN的另一种改进算法,它在传统 DQN 的基础上只进行了微小的改动,但能大幅提升 DQN的表现
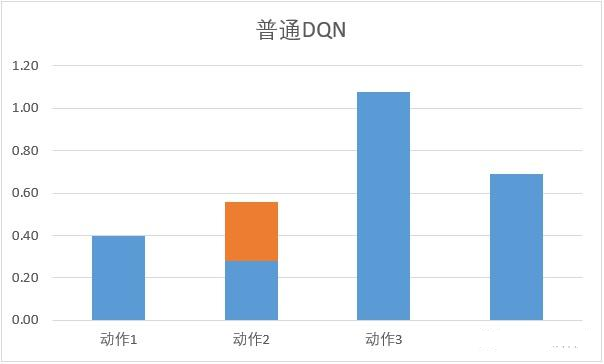
它从另外一个方面考虑 DQN 的问题:每次更新 Q 网络的时候,我们只是对网络中的最大值进行反向传播,而不管其他的 Q 值,这导致不同动作的 Q 值可能相差过大:
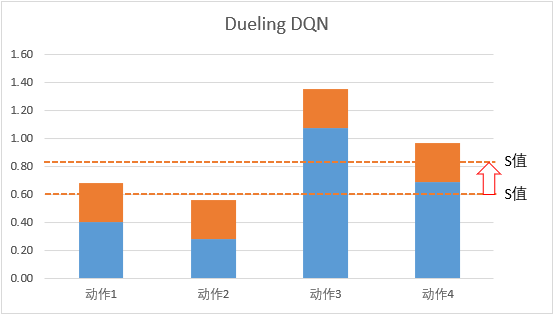
因此在 Dueling DQN 中,引入优势函数的概念:
将动作价值函数 Q Q Q V V V A A A A ( s , a ) = Q ( s , a ) − V ( s ) A(s,a)=Q(s,a)-V(s) A ( s , a ) = Q ( s , a ) − V ( s )
因此 Q 网络被建模为:
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) Q_{\eta, \alpha, \beta}(s,a)=V_{\eta, \alpha}(s)+A_{\eta, \beta}(s,a)
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a )
对于公式 Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) Q_{\eta,\alpha,\beta}\left( s,a\right) = V_{\eta,\alpha}\left( s \right) + A_{\eta,\beta}\left( s,a\right) Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) V V V A A A Q Q Q V V V C C C A A A C C C Q Q Q 导致了训练的不稳定性 。为了解决这一问题,Dueling DQN 强制最优动作的优势函数的实际输出为 0 , 即:
Q_{\eta,\alpha,\beta}\left(s,a \right) = V_{\eta,\alpha}\left( {s} \right) + A_{\eta,\beta}\left( {s}, {a} \right) {-} {\max}\limits_{ {d}}A_{\eta,\beta}\left( {s}, a' \right)
此时 V ( s ) = max a Q ( s , a ) V(s) = \max_aQ(s,a) V ( s ) = max a Q ( s , a ) V V V
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) − 1 ∣ A ∣ ∑ d A η , β ( s , a ′ ) Q_{\eta,\alpha,\beta}\left(s,a\right) = V_{\eta,\alpha}\left( s\right) + A_{\eta,\beta}\left(s, a \right) - \frac{1}{|A|}\sum_dA_{\eta,\beta}\left(s,a' \right)
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) − ∣ A ∣ 1 d ∑ A η , β ( s , a ′ )
此时 V ( s ) = 1 ∣ A ∣ ∑ d Q ( s , a ′ ) V(s) = \frac{1}{|A|}\sum_d Q( s,a') V ( s ) = ∣ A ∣ 1 ∑ d Q ( s , a ′ )