cuda-2-程序框架
cuda 程序框架
1 | |
一些常用函数
限定符的使用
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
__global__ |
设备端执行 | 可以从主机调用也可以从计算能力3以上的设备调用 | 必须有一个void的返回类型 |
__device__ |
设备端执行 | 设备端调用 | |
__host__ |
主机端执行 | 主机调用 | 可以省略 |
获取GPU设备数量
1 | |
功能描述:
- 输入参数
int* count是一个指向整型变量的指针,用于接收当前系统的CUDA设备数量 - 函数执行成功时,将填充
count变量 - 如果没有可用的CUDA设备,那么
count将被设置为0,并返回相应的错误状态
1 | |
设置GPU执行时使用的设备
1 | |
cudaSetDevice只能在主机上运行(不然已经到GPU上哪还需要设置)
内存管理(操作 global memory)
CUDA通过内存分配,数据传递,内存初始化,内存释放进行内存管理
| C语言 | CUDA语言 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
数据分配:
1 | |
devPtr:用于接受分配内存的地址(是一个指向指针的指针,类型为 void)size:用于指定内存分配的大小
1 | |
数据拷贝:
1 | |
dest:用于接受拷贝的目的地址src:用于拷贝的源地址count:用于指定拷贝的长度kind:用于指定拷贝从哪里到哪里,有四种可能:
| Kind | 拷贝方向 |
|---|---|
| cudaMemcpyHostToHost | 主机->主机 |
| cudaMemcpyHostToDevice | 主机->设备 |
| cudaMemcpyDeviceToHost | 设备->主机 |
| cudaMemcpyDeviceToDevice | 设备->设备 |
| cudaMemcpyDefault | 默认 |
默认方式只允许在支持同意虚拟寻址的系统上使用(自动判断拷贝方向)
内存初始化:
1 | |
devPtr:用于接受内存初始化的地址value:用于指定内存初始化的值count:用于指定内存初始化的长度
内存释放:
1 | |
devPtr:用于接受内存释放的地址
一个经常会发生的错误就是混用设备和主机的内存地址!
为了避免这个情况,建议每个地址后面接上一个 _d 或者 _h 表示是主机端(host)还是设备端(device)
核函数
核函数就是在CUDA模型上诸多线程中运行的那段串行代码,这段代码在设备上运行,用NVCC编译,产生的机器码是GPU的机器码,所以我们写CUDA程序就是写核函数,第一步我们要确保核函数能正确的运行产生正确的结果,第二优化CUDA程序的部分,无论是优化算法,还是调整内存结构,线程结构都是要调整核函数内的代码来完成这些优化的
Kernel核函数编写有以下限制
- 只能访问设备内存
- 必须为 void 返回类型
- 不支持静态变量
- 显示异步行为
启动核函数
启动核函数,通过的以下的 ANSI C 扩展出的 CUDA C 指令:
1 | |
其标准C的原型就是C语言函数调用
1 | |
<<<grid,block>>> 内是对设备代码执行的线程结构的配置(或者简称为对内核进行配置),也就是我们上一篇中提到的线程结构中的 grid,block。我们通过 CUDA C 内置的数据类型 dim3 类型的变量来配置 grid 和 block
线程管理
当核函数开始执行,组织 GPU 的线程就变成了最主要的问题了,我们必须明确,一个核函数只能有一个 grid,一个 grid 可以有很多个块,每个块可以有很多的线程,这种分层的组织结构使得我们的并行过程更加自如灵活:
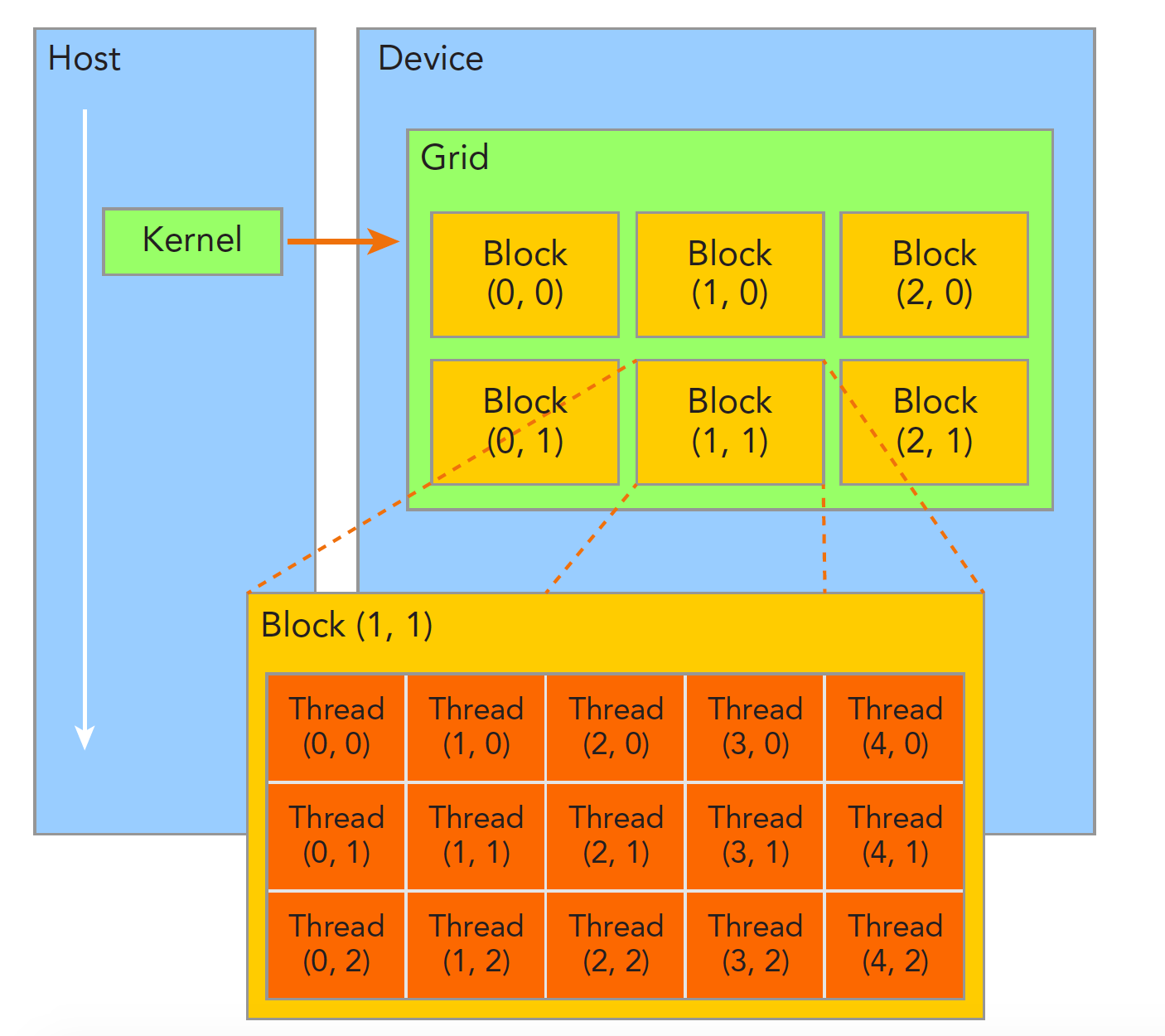
一个线程块block中的线程可以完成下述协作:
- 同步(相互影响,注意竞争冒险的问题)
- 共享内存
不同块内线程不能相互影响!他们是物理隔离的!
1 | |
线程布局是:

为了给每个线程一个编号了,我们知道每个线程都执行同样的一段串行代码,那么怎么让这段相同的代码对应不同的数据呢?首先第一步就是让这些线程彼此区分开,才能对应到相应从线程,使得这些线程也能区分自己的数据。如果线程本身没有任何标记,那么没办法确认其行为。
依靠下面两个内置结构体确定线程标号:
- blockIdx(线程块在线程网格内的位置索引)
- threadIdx(线程在线程块内的位置索引)
这两个内置结构体基于 uint3 定义,包含三个无符号整数的结构,通过三个字段来指定:
- blockIdx.x,blockIdx.y,blockIdx.z
- threadIdx.x,threadIdx.y,threadIdx.z
上面这两个是坐标,当然我们要有同样对应的两个结构体来保存其范围,也就是 blockIdx 中三个字段的范围 threadIdx 中三个字段的范围:
- blockDim,gridDim
他们是 dim3 类型(基于uint3定义的数据结构)的变量,也包含三个字段 x,y,z
1 | |
dim3数据类型是通过括号进行初始化(顺序为 x,y,z ),通过结构体访问属性的方式修改的
1 | |
应用实例:cuda实现矩阵加法
1 | |
在开发阶段,每一步都进行验证是绝对高效的,比把所有功能都写好,然后进行测试这种过程效率高很多,同样写CUDA也是这样的每个代码小块都进行测试,看起来慢,实际会提高很多效率
CUDA小技巧,当我们进行调试的时候可以把核函数配置成单线程的:
1 | |