Wandb教程(3)
本篇文章用于介绍Wandb如何进行网格超参数搜索,主要使用了Wandb中的Sweep功能:
Sweep配置:
定义 Sweeps 配置
Wandb的配置文件支持YAML和Python等多种文件格式,关于如何配置Sweep可见[官方文档](Define sweep configuration for hyperparameter tuning. (wandb.ai)),下面是两种文件配置的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| program: train.py
method: grid
parameters:
learning_rate:
distribution: uniform
min: 0.0001
max: 0.01
batch_size:
values: [32, 64, 128]
dropout_rate:
distribution: log_uniform
min: 0.001
max: 0.5
metric:
name: val_accuracy
goal: maximize
|
1
2
3
4
5
6
7
8
9
10
| import wandb
sweep_config = {
"method": "grid",
"metric": {"name": "val_loss", "goal": "minimize"},
"parameters": {
"learning_rate": {"distribution": "uniform", "min": 1e-4, "max": 1e-2},
"dropout_rate": {"distribution": "categorical", "values": [0.2, 0.3, 0.4]},
},
}
|
初始化 Sweep
对于Python文件,初始化则需要使用wandb.sweep函数
1
2
3
4
5
6
7
8
9
10
11
12
13
| import wandb
sweep_id = wandb.sweep(sweep_config)
def train(hparams):
wandb.init(config=hparams)
wandb.agent(sweep_id, function=train)
|
常用配置:
1,选择一个调优算法
Sweep支持如下3种调优算法:
-
网格搜索:grid. 遍历所有可能得超参组合,只在超参空间不大的时候使用,否则会非常慢
-
随机搜索:random. 每个超参数都选择一个随机值,非常有效,一般情况下建议使用
-
贝叶斯搜索:bayes. 创建一个概率模型估计不同超参数组合的效果,采样有更高概率提升优化目标的超参数组合。对连续型的超参数特别有效,但扩展到非常高维度的超参数时效果不好
1
2
3
| sweep_config = {
'method': 'random'
}
|
2,定义调优目标
设置优化指标,以及优化方向。
sweep agents 通过 wandb.log 的形式向 sweep controller 传递优化目标的值
1
2
3
4
5
| metric = {
'name': 'val_acc',
'goal': 'maximize'
}
sweep_config['metric'] = metric
|
3,定义超参空间
超参空间可以分成 固定型,离散型和连续型
- 固定型:指定 value
- 离散型:指定 values,列出全部候选取值
- 连续性:需要指定 分布类型 distribution, 和范围 min, max。用于 random 或者 bayes采样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| sweep_config['parameters'] = {}
sweep_config['parameters'].update({
'project_name':{'value':'wandb_demo'},
'epochs': {'value': 10},
'ckpt_path': {'value':'checkpoint.pt'}})
sweep_config['parameters'].update({
'optim_type': {
'values': ['Adam', 'SGD','AdamW']
},
'hidden_layer_width': {
'values': [16,32,48,64,80,96,112,128]
}
})
sweep_config['parameters'].update({
'lr': {
'distribution': 'log_uniform_values',
'min': 1e-6,
'max': 0.1
},
'batch_size': {
'distribution': 'q_uniform',
'q': 8,
'min': 32,
'max': 256,
},
'dropout_p': {
'distribution': 'uniform',
'min': 0,
'max': 0.6,
}
})
|
4,定义剪枝策略 (可选)
可以定义剪枝策略,提前终止那些没有希望的任务。
1
2
3
4
5
6
| sweep_config['early_terminate'] = {
'type':'hyperband',
'min_iter':3,
'eta':2,
's':3
}
|
启动Sweep:
初始化 sweep controller
wandb.sweep 用于创建和管理超参数搜索(Hyperparameter Sweeps)的主要接口。它允许定义搜索空间、选择搜索策略,并启动一个或多个 Agent 来执行一系列训练试验,以寻找最优模型配置
1
| wandb.sweep(sweep_config: Union[str, Dict[str, Any]], project: Optional[str] = None) -> str
|
参数:
sweep_config: 定义超参数搜索的配置。可以是 YAML 文件的路径(字符串)或直接提供一个 Python 字典。该配置包含搜索空间、搜索算法、调度策略等信息project: 可选的字符串,指定 wandb 项目名称。如果不指定,将使用当前默认项目
返回值:返回一个字符串,表示新创建的 Sweep 的唯一 ID (sweep_id)。这个 ID 用于后续通过 wandb.agent 启动 Agent 时关联到该 Sweep
注意:name 在 sweep_config 里面配置
启动 Sweep agent
我们需要把模型训练相关的全部代码整理成一个 train函数,再将train函数传入 sweep agent:
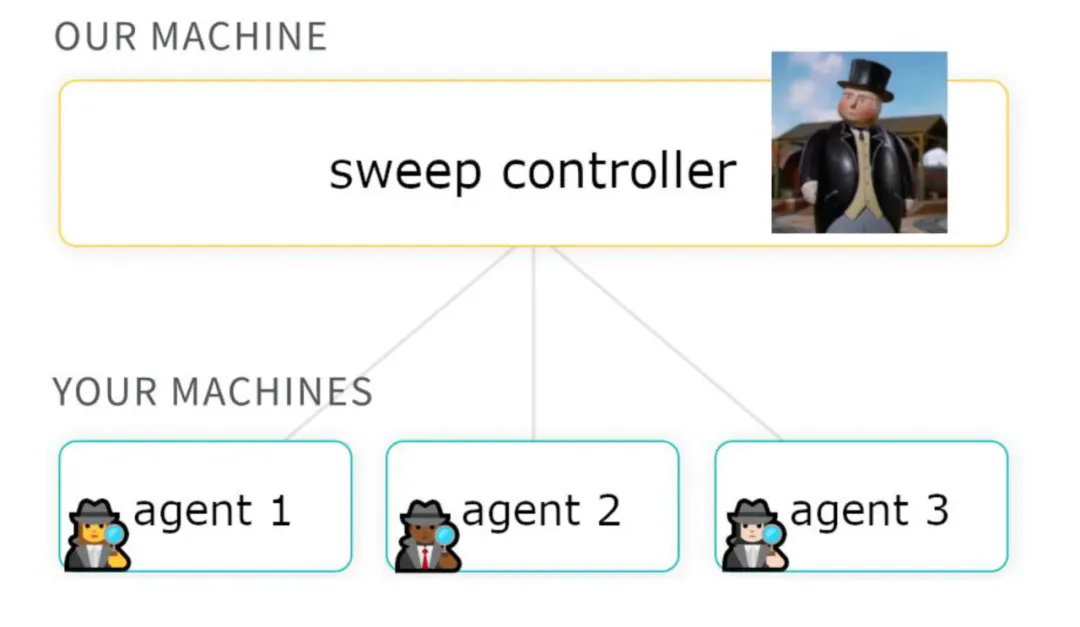
sweep_id就是一个 sweep controller,wandb.agent就是用于创建 sweep agent 的函数它和 sweep agent 的关系如下:
Sweep Controller 负责定义超参数搜索的整体策略、配置搜索空间,并根据策略分配具体的超参数组合给 Agent 执行Agent 根据 Sweep Controller 分配的超参数组合执行相应的训练任务,将训练过程中的数据同步回 wandb 平台
wandb.agent() 主要接收参数:
sweep_id:这是你之前创建或通过 API 获取到的 Sweep 的唯一标识符function:这是一个可调用对象,通常是train函数,并且可以访问当前 sweep 运行时传入的超参数- 后面的参数可以用关键字参数传入 train 函数的配置参数
修改训练脚本以接收超参数
确保训练脚本(例如上述的 train.py)能够从 wandb.config 中读取超参数值,并根据这些值来配置模型和训练过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import wandb
cofig = {
...
}
def train(config=config):
hparams = wandb.config
learning_rate = hparams.learning_rate
batch_size = hparams.batch_size
dropout_rate = hparams.dropout_rate
|
效果展示:
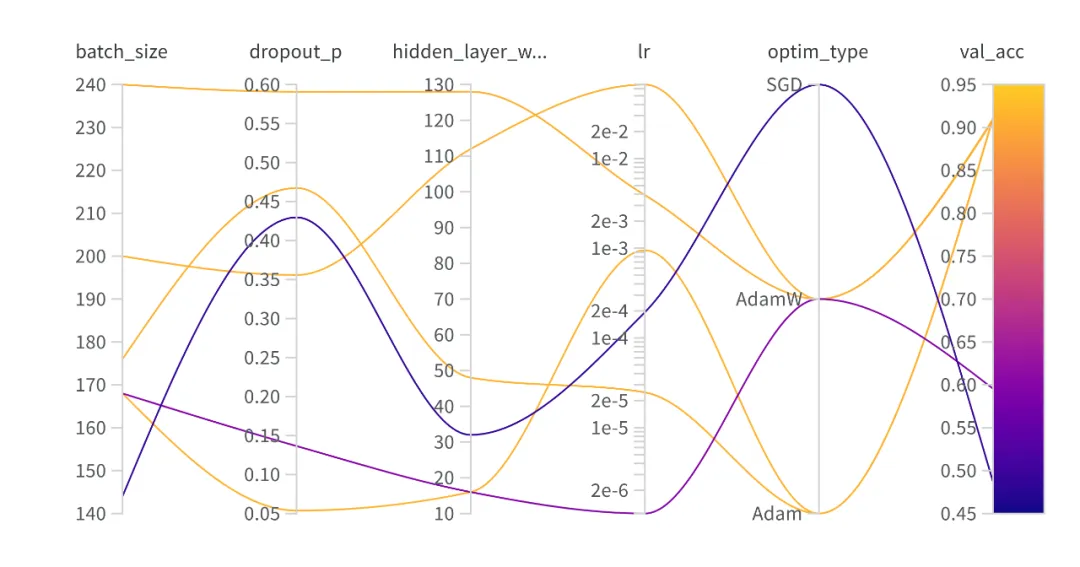
平行坐标系图
可以直观展示哪些超参数组合更加容易获取更好的结果
超参数重要性图
可以显示超参数和优化目标最终取值的重要性,和相关性方向