常用Neck网络-1
SPP(Spatial Pyramid Pooling)
Motivation:
SPP的提出就是为了解决CNN输入图像大小必须固定的问题,从而可以使得输入图像高宽比和大小任意
网络结构解析:
SPP-Neck网络结构如下:
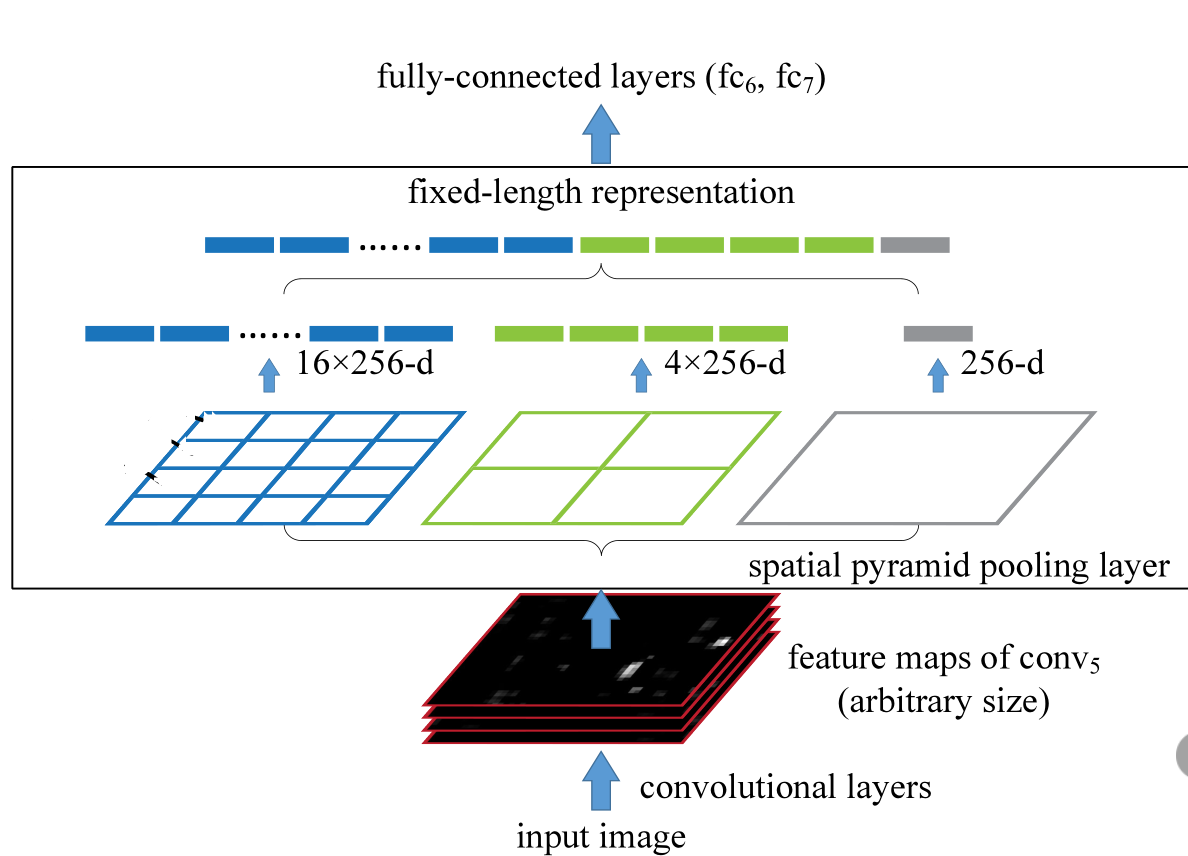
- 首先是输入层(input image),其大小可以是任意的
- 中间的部分就是SPP-Neck层,SPP会在最后一层卷积层输出的特征图上进行操作,将其划分为多个不同大小的子区域,并对每个子区域分别执行池化操作
- 最左边有是原特征图拆分成16份的图,256表示的是原特征图的channel对应在Linear层的维度,共有16个这样的Linear层(最常见的是使用等比分割以形成规则的网格,并不一定是等比分)
- 中间部分和右侧部分的网络同理,就是将原特征图分成了 和 ,同理左边的部分
代码实现:
1 | |
ASPP(Atrous Spatial Pyramid Pooling)
Motivation:
可以认为是SPP在语义分割中的应用,结合了空洞卷积可在不丢失分辨率(不进行下采样)的情况下扩大卷积核的感受野。Deep CNN 中普通卷积对于其他任务还有一些致命性的缺陷。主要问题有:
- 内部数据结构丢失;空间层级化信息丢失
- 小物体信息无法重建 (假设有四个pooling layer 则任何小于 pixel 的物体信息将理论上无法重建
在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度, 而 dilated convolution 的设计就良好的避免了这些问题
网络结构解析:
ASPP网络结构如下:
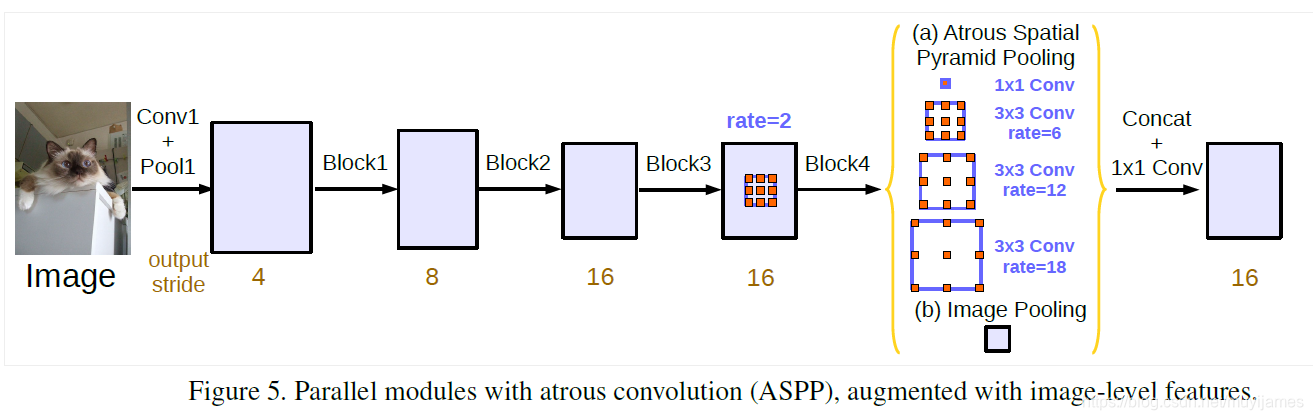
中间黄色括号部分即为 ASPP-Neck,展开结构如下所示:
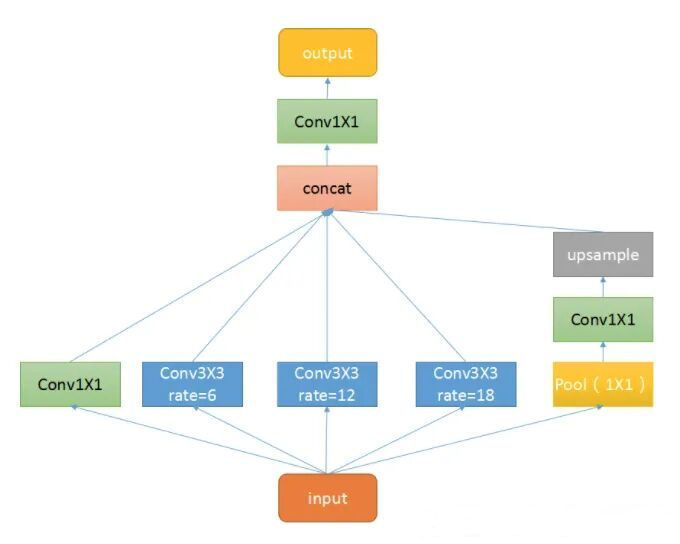
- 对于 input,网络会对 feature map 分别进行 $1 \times1 $ 和不同比例空洞卷积,这些操作都不改变 feature map 的大小
- 右边部分称为 ASPP Pooling,目的是为了得到语义信息,首先是一个
AdaptiveAvgPool2d层。自适应均值池化就是不需要指定 kernel size 和 stride,只需指定最后的输出尺寸,再进行 卷积后上采样 - 最终将这些 feature map concat 到一起再特征融合即可
代码实现:
1 | |
NAS-FPN(Neural Architecture Search)
Motivation:
采用神经网络结构搜索(Neural Architecture Search, NAS),在一个覆盖所有跨尺度连接的新型可扩展搜索空间中发现了一个新的特征金字塔结构,NAS-FPN。与原始FPN相比,NAS-FPN显著提高了目标检测的性能,并取得了更好了速度-精度的 trade-off
网络结构解析:
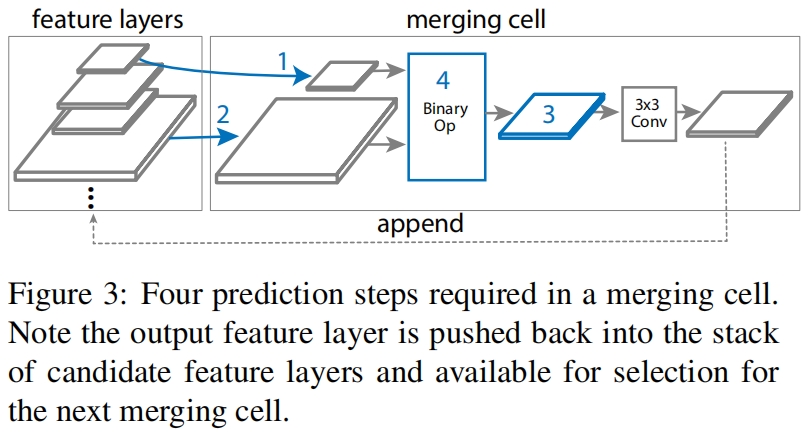
作者提出了merging cell作为FPN的basic building block,将任何两层的输入特征融合为一层的输出特征:
最终搜索到的NAS-FPN的完整结构如图6所示
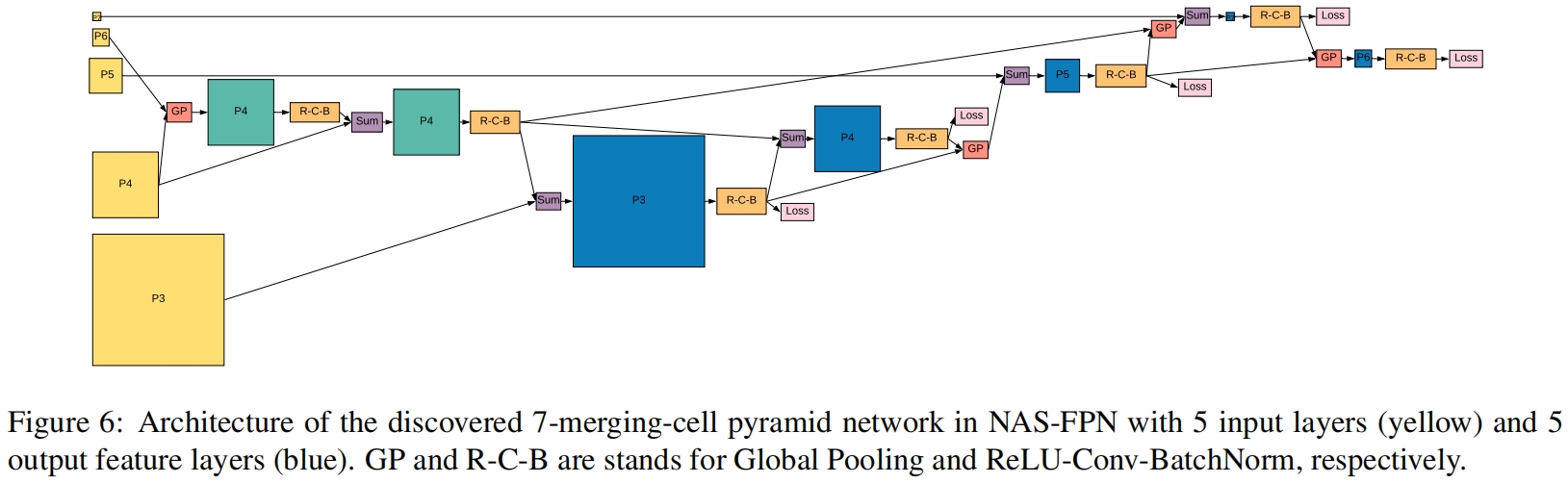
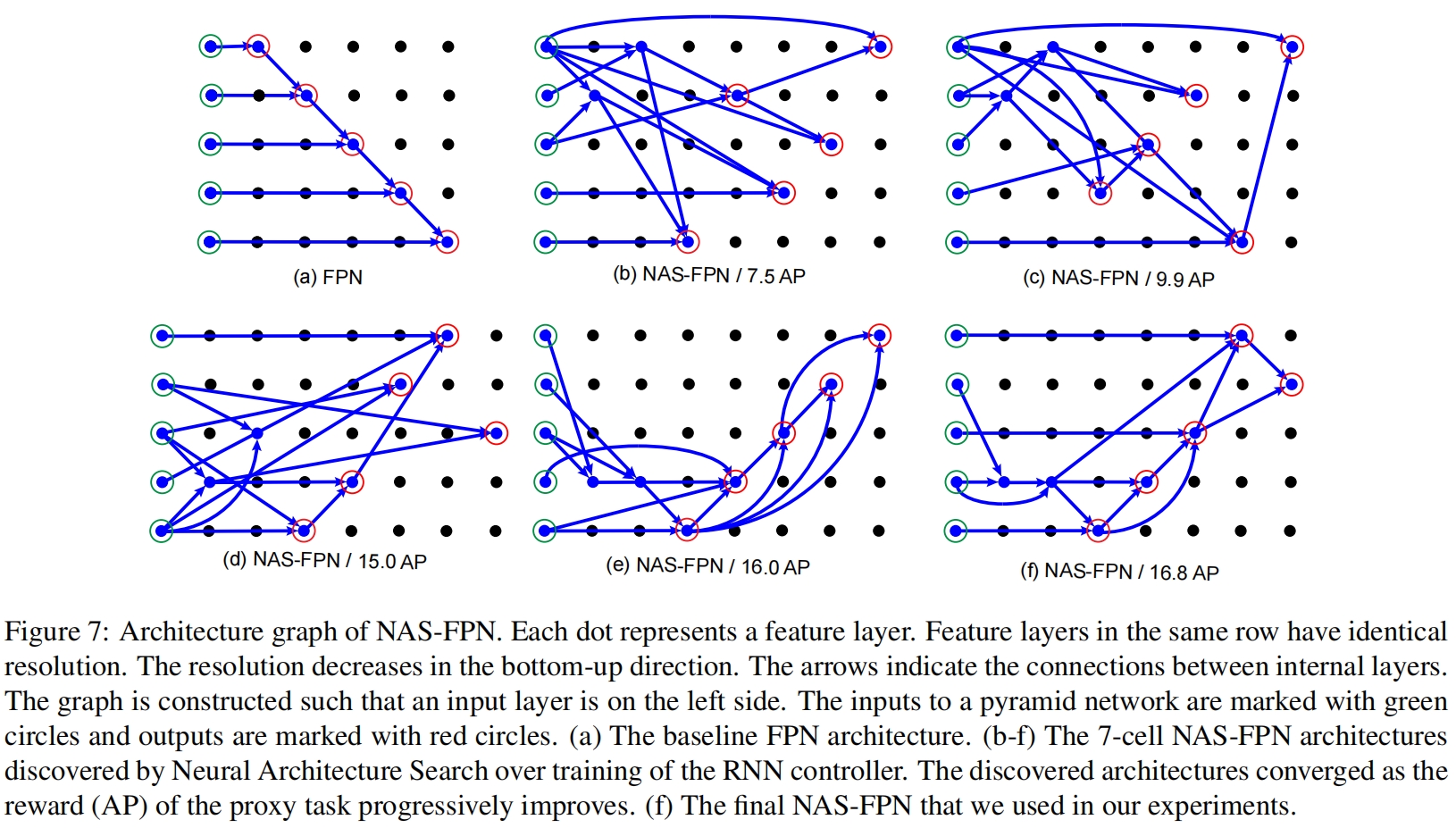
如下图所示,下图其中(a)是原始FPN结构,(b)-(f)的精度逐渐变高,(f)是最终的NAS-FPN结构,每个圆点代表一个特征层,绿色圆圈表示输入层,红色圆圈表示输出层,这些特征层在同一个行中具有相同的分辨率。箭头指示特征层之间的连接或信息流的方向
代码实现:
以 mmdetection 中的一部分代码为例:
1 | |
PANet(Path Aggregation Network)
Motivation:
dense prediction task 不仅要关心语义信息,还要关注图像的精确到像素点的浅层信息。PANet 最大的贡献是提出了一个自顶向下和自底向上的双向融合骨干网络,同时在最底层和最高层之间添加了一条“short-cut”,用于缩短层之间的路径
网络结构解析:
PANet网络结构如下:
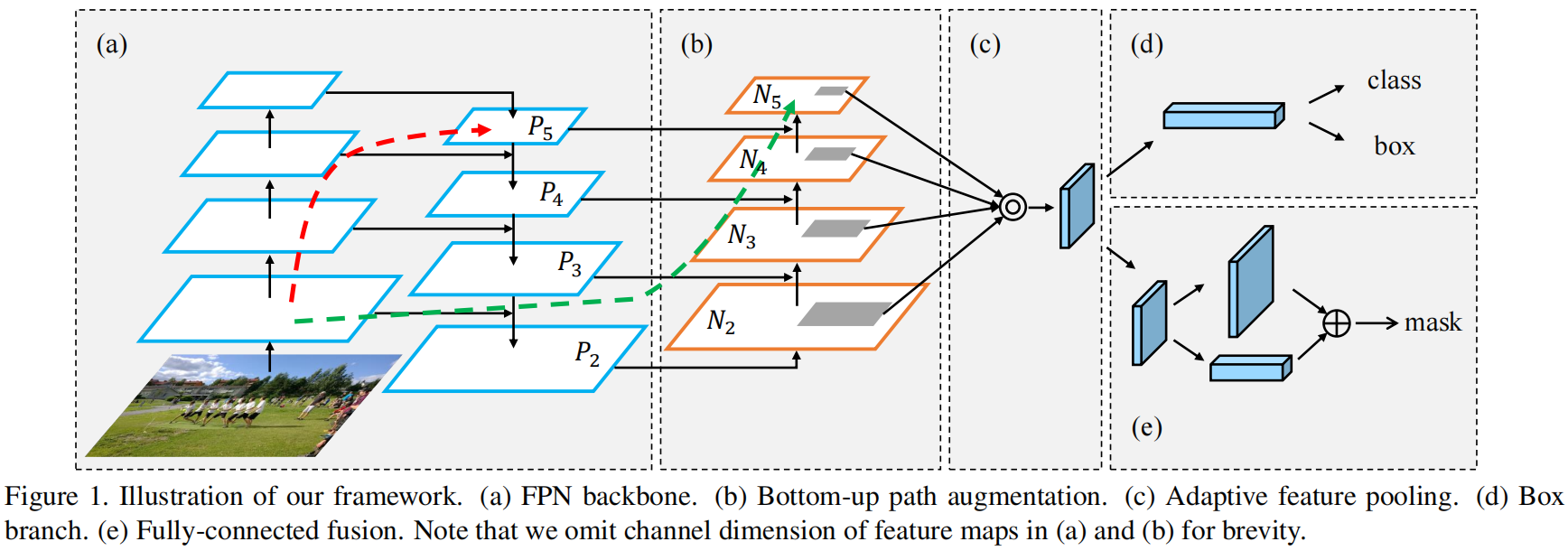
具体的实现比较简单,就是在FPN的基础上加上了一个Neck部分,再通过两条虚线将浅层网络信息跳连到深层网络中(按理来说PANet是可以在NAS-FPN那篇论文中搜索到的,查了一下确实PANet的发表时间早于NAS-FPN)
其它:
还有各种FPN网络如PANet、ASFF、NAS-FPN、BiFPN、Recursive-FPN…太多了,有需要的时候再查
个人感想:要是 NAS 能够改变算法能够搜索地足够快的话,能把这些 FPN 网络全部搜索完就好了,哪需要认为设计这么多乱七八糟的 FPN…