FeatUp(1)
FeatUp
本文章通过借助图像重建的思路提出了一种新型上采样算子,这篇论文的idea可以用以下几点概括:
- 借助3D图像重建网络NeRF的想法:多个视角下的地分辨率信号可以指导采样高分辨率的特征图的“重建“过程,这里的“多个视角”指对原低分辨率特征图进行各种微调(jittered)之后的特征图,通过这些低分辨率的特征图可以有效地帮助重建高分辨率信号
- 以Joint Bilateral Upsampling (JBU)采样算子为基础,在此基础上进行一般化推广为这篇文章中的结果
网络结构:
这篇文章的核心就是借助NeRF中从不同的视角观察3D场景,以此去“强迫2D图片的连续性”
网络结构如下图所示,网络先使用backbone网络去引导学习下采样算子,再通过
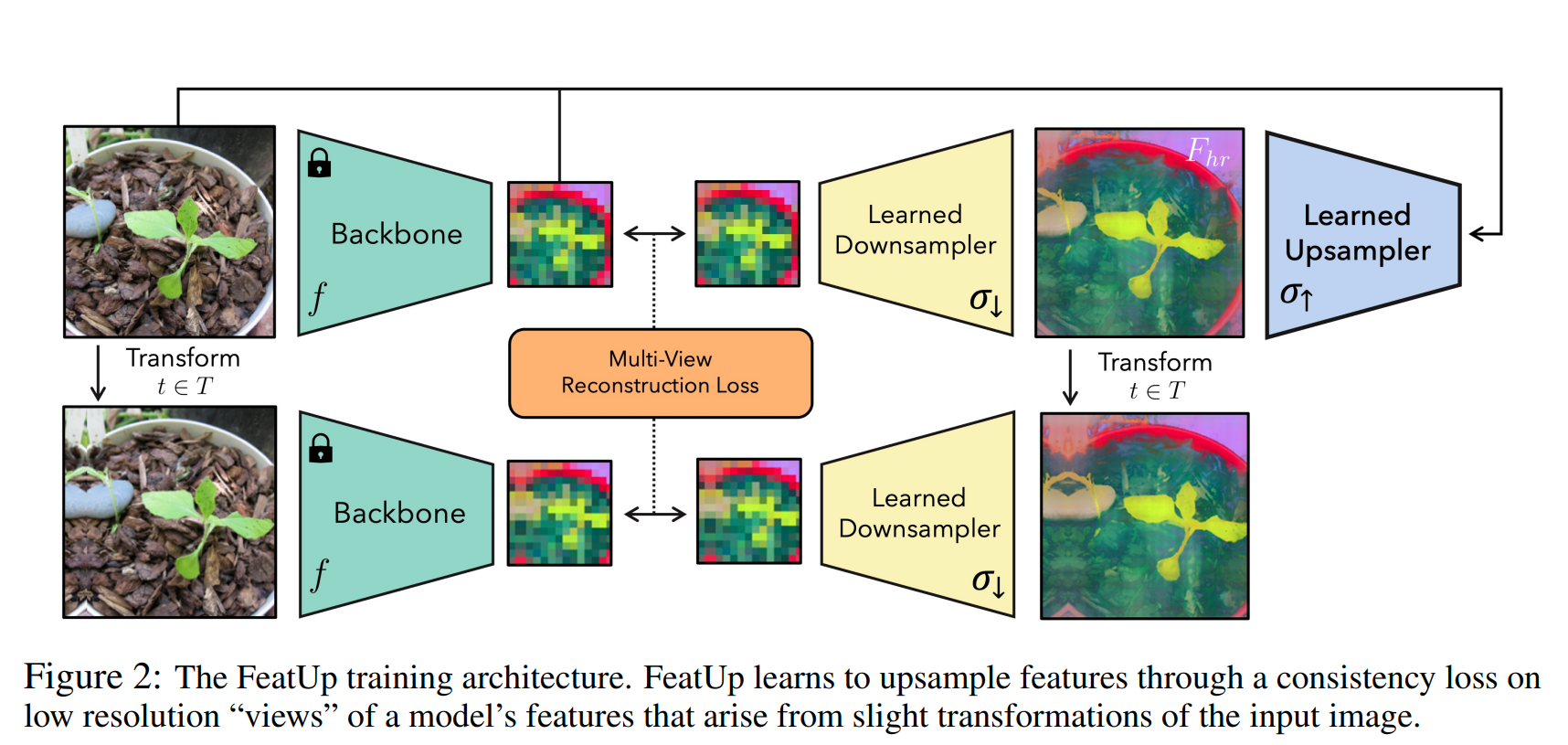
用符号语言表示如下:设 是一种transform(比如旋转,裁剪,镜像扩张等), 为 组成的集合, 为指导训练下采样核的backbone, 为待训练的下采样算子, 为学习出的上采样算子,则可以得到预测出来的高分辨率图 ,注意: 同时依赖于 与 (称为guided),不是 unguided upsampler(仅依赖于 ),不是一个 implicit network(仅依赖于 ),更不是一个 learned buffer(与 与 )均无关
则我们得到的多视角重建损失函数如下:
其中 是 spatially-varying adaptive 不确定度通过一个 Linear 层 转化为一个标量值,这一项将 MSE loss 变为能够恰当处理不确定性的合理似然性 loss(proper likelihood capable of handling uncertainty),这种额外的灵活性使得网络能够在某些异常特征根本无法上采样的情况下进行学习
选择下采样核:
本文中选取了两种下采样核:一个是轻量级的可学习的 blur kernel,另一个是更加灵活的基于 attention 的采样核,它们都是通过简单地使用邻域信息插值像素点(没多高级)
- 第一种下采样核选取为简单地卷积核,卷积核每个值被保证为正且和为1(保证强度的连续性)
- 第二种下采样核改进了第一种下采样核几种缺点:不能动态地改变感受野大小,不能动态地感受 object salience 和不支持非线性映射。第二种下采样核规则如下:先对预测高分辨图使用 的卷积核生成一个重要性特征图(saliency map),再通过与一个 spatially-invariant weight and bias kernel 进行掩码计算得到下采样图:
其中 是下采样后在坐标为 的像素点, 是对应下采样坐标为 像素点的原图像的 patch, 和 是学习得到的 weight 和 bias(对所有 patch 共用)
选择上采样核:
选择上采样核是一个关键的步骤,本文选择了两个上采样核:
- Joint Bilateral Upsamplers(JBU)
- “Implicit” FeatUp,它使用
Joint Bilateral Upsampler:
上采样算子定义为一串参数化的 JBU 复合算子:
是低分辨率图,本文推广了 BJU 的计算过程(generalizes the original JBU (Kopf et al., 2007) implementation to high-dimensional signals and makes this operation learnable)让它变得可学习,使用了一个高分辨率的信号 指导对 的采样过程,令 是 中的像素点邻域,本文使用了以目标点为中心的 的邻域,令 为相似度函数,令 为正则化因子(保证值为1),则推广的 BJU 算子如下:
其中 是一个可学习的 Gaussian Kernel( 可学习),为了协调高分辨率和低分辨率坐标范围不一样的问题,本文将将距离都正则化到 的范围:
而 是 temperature-weighted softmax, 是 temperature 因子:
在本文中 MLP 设置了一个30维的隐藏层和两个 GeLU 激活函数
评估低分辨率特征图 中的位置坐标 时,遵循原始的联合双边上采样(Joint Bilateral Upsampling, JBU)公式进行处理。(评估位置坐标(evaluate)就是如果指导像素(guidance pixel)与低分辨率特征图中的某个像素点并未完全重合时,用双线性插值的方式来获取特征值,这是行话)
Implicit:
第二种上采样器架构与 NeRF 直接类比,通过使用一个隐式函数 来参数化单幅图像的高分辨率特征。已有若干现有的上采样解决方案采用了类似的推理时刻训练方法,包括DIP和LIIF。我们使用了一个小型多层感知机(MLP),用于将图像坐标和强度映射至给定位置的高维特征。利用傅立叶特征改进了隐式表示的空间分辨率。除了标准的傅立叶位置特征外,我们还展示了添加傅立叶颜色特征能使网络利用原始图像中的高频颜色信息。这一做法极大地加快了收敛速度,并能够在不依赖条件随机场(CRFs)等技术的情况下,优雅地利用高分辨率图像信息
令 代表逐内容(conponent-wise)的像素特征通过一个频率向量 经过离散傅里叶变换得到的特征,令 为二维像素坐标字段(像素坐标场(pixel coordinate fields)),是以浮点数表示的二维数组,其中每个元素对应图像中的一个像素点的横或纵坐标, 代表 concatnate,用公式描述如下:
其中 MLP 设置为三层的 ReLU 网络,带有 0.1 的 dropout 和 layer normalization(可以学一下像这样调参),这种方式比第一种方式少了非常多的参数量和内存消耗
论文中可以学习的技巧:
- GeLU函数激活函数可能比传统的ReLU更加高效
- 要学会使用 dropout 层
- 比传统 softmax 更加灵活的 temperature-weighted softmax,温度参数T起到了调节输出概率分布陡峭程度的作用:
- 当温度T > 1时,softmax函数的输出更加平滑,每个类别的概率差异减小,模型变得更为保守,不倾向于过于确定某个类别
- 当T接近于0时,softmax函数趋于硬最大化,输出的概率分布更加尖锐,模型倾向于高度集中在具有最高logit值的类别上
- 减少内存占用并进一步加速FeatUp隐式网络的训练过程,我们首先将空间变化的特征压缩为其前128个主成分。这一操作近乎无损,因为在一个图像的所有特征中,前128个主成分大约能解释96%的方差(这种方法使ResNet-50的训练时间提升了60倍)
- 图像中使用傅里叶特征,从空间域转换到频率域,允许对图像进行频率成分分析,可能比直接特征分析更加有效
- 为了避免在高分辨率特征中出现虚假噪声,论文在隐式特征幅度上添加了一个小的总变差平滑先验(Total Variation Prior),相较于对完整特征进行正则化,这种方法更加快速,并且避免了过度规定单个组件应该如何组织排列(在JBU上采样器中,由于它本身不容易过拟合,所以没有在这部分使用)
问题:
at test time, we can query the pixel coordinate field to yield features Fhr at any resolution.