Wandb教程(1)
Wandb教程(1)
Wandb(Weights & Biases)是一个用于机器学习实验跟踪、可视化和管理的平台。它提供了一个强大的工具集,帮助研究人员和开发人员跟踪他们的模型训练过程、超参数、指标以及模型的版本。他就是Tensorboard的白富美版本:颜值高,气质好,可视化交互性强,支持所有深度学习框架。它内嵌在计算机中,不需要你写可视化代码(我之前每次可视化都要写一次把张量的batch维度抽出来,再转换通道维的索引…)
Wandb的网站是高度可交互的,这个功能非常的强大,可以自行探索(比如添加panel,缩放图像展示格,交互式地进行数据分析等)
Wandb的使用:
Wandb用法与matplotlib.plt十分类似,既支持面向对象编程也支持面向过程编程,即既可以实例化一个对象使用,又可以纯函数式使用:
1 | |
下面我们介绍各种函数的使用(仅介绍常用用法,更多用法查阅官方文档):
wandb.init的使用:
它的参数多得太夸张了,进阶参数查阅官方文档,这里只列举几个常用参数:
1 | |
参数解释:
project (str): 运行所属项目的名称。用于将运行组织到特定的项目下name (str, optional): 运行项的显示名称。这个名称在Wandb的界面中显示,并且可以编辑,但不需要是唯一的config (dict-like, optional): 一个字典类对象,用于设置实验的配置,如超参数。这些配置会被跟踪,并且可以在Wandb的界面中查看**(这个参数如果太长了,可以在函数外面专门写配置的一句话)**dir(str or pathlib.Path, optional):一个绝对路径,用于保存训练过程中的元数据(metadata)resume: Optional[Union[bool, str]]:这个参数用于控制是否恢复之前中断的实验运行(run)。如果你在训练过程中中断了实验,并且想要在之后的某个时间点恢复它,你可以使用resume=Truejob_type:记录任务的类型,例如 ‘training’, ‘evaluation’, ‘inference’ 等。默认值为 ‘training’anonymous:用于控制是否启用匿名记录。当你不希望将实验运行与你的账户关联,或者你不希望你的实验运行在公共Wandb项目中可见时,可以使用这个参数:"allow"表示允许匿名记录,但不会强制"never"表示不允许任何匿名记录,所有记录都必须与账户关联"must"表示强制匿名记录,这意味着运行将不会与任何账户关联
wandb.log的使用:
用于记录在训练过程中需要可视化的信息,函数声明如下:
1 | |
data(dic, optional):一个可序列化的Python对象的字典,即字符串(str)、整数(ints)、浮点数(floats)、张量(Tensors)、字典(dicts)等step(int, optional):处理中的全局步骤,表示训练过程中的指标随step的变化情况
wandb.Image 的使用:
用于创建一个 wandb.Image 对象,该对象可以被记录到 Wandb 的运行中。以下是 wandb.Image 类的一些常用参数和它们的用法:
1 | |
参数:
-
data_or_path(PIL Image 或 NumPy 数组或者图像数据路径):必须提供的参数,表示要记录的图像数据。它可以是一个 PIL图像对象,或者是一个 NumPy 数组,如果是路径wandb会推断数据类型并且读入数据 -
caption(str, optional): 图像的标题或描述 -
mode(str, optional):图像数据的结构,可以为 “L(灰度图)”, “RGB”, “RGBA(带透明度)”. 等
返回值:
wandb.Image 类的构造函数返回一个 wandb.Image 对象。这个对象可以被传递给 wandb.log 函数,用于记录和可视化图像数据
使用范例:
1 | |
wandb.Artifact的使用:
wandb.Artifact 用于封装、管理和共享项目资源(如数据集、模型、代码、日志文件等)的重要类。它允许将这些资源版本化、关联到特定的 wandb 运行,并在 wandb 平台上进行可视化、下载和复用:
构造函数
1 | |
参数:
name: str:Artifact的唯一名称。在项目中应保持唯一,以避免覆盖已有资源type: str:Artifact的类型,用于标识资源的类别。常见的类型有'dataset'、'model'、'code'等,也可以自定义。description: Optional[str] = None: 可选的描述文字,用于提供Artifact的简要说明。metadata: Optional[Dict[str, Any]] = None: 可选的元数据字典,用于存储关于Artifact的附加信息,如数据集统计信息、模型架构摘要等version: Optional[str] = None: 可选的版本号。如果不指定,wandb会自动为Artifact分配一个版本
返回值:
- 返回一个
wandb.Artifact对象,代表创建的资源包。
主要方法:
add_file:用于将指定路径下的单个文件添加到Artifact中。这使得该文件成为Artifact的一部分,将在Artifact上传至wandb服务器时一同保存add_dir:将指定路径下的整个目录及其内容(包括子目录和文件)添加到Artifact中log_artifact将Artifact记录到指定的wandb运行中,并将其上传到wandb服务器。这样,该Artifact就与特定的wandb运行关联起来,可以在wandb界面上查看、下载、分享和复用
1 | |
`参数:
path: Union[str, Path]: 要添加到Artifact中的本地文件或目录的路径name: Optional[str] = None: 可选的在Artifact内部使用的文件名。如果不指定,将使用原始文件名metadata: Optional[Dict[str, Any]] = None: 可选的文件元数据字典,用于存储关于文件的附加信息
1 | |
参数:
path: Union[str, Path]: 要添加到Artifact中的本地目录的路径name: Optional[str] = None: 可选的在Artifact内部使用的目录名。如果不指定,将使用原始目录名recursive: bool = True: 是否递归地添加目录下所有文件和子目录。默认为True
1 | |
参数:
run: Optional[Union[str, wandb.apis.public.Run]] = None: 可选的wandb运行对象或运行ID。如果不指定,将使用当前wandb运行commit: Optional[bool] = True: 是否立即提交并上传
Wand.Table使用:
wandb.Table 是用于展示和记录表格数据的一种数据结构。它允许用户将结构化的数据(如 Pandas DataFrame、NumPy 数组或其他表格数据)以表格形式可视化,并将其与 wandb 运行关联起来,便于在 wandb 界面上进行数据分析、探索和比较
创建 wandb.Table
构造函数:
1 | |
参数:
data: 表格数据,可以是以下类型之一:- Pandas DataFrame
- 列表嵌套字典(每一项代表一行数据,键为列名,值为数据)
- 列表嵌套列表(每一项代表一行数据,按列顺序排列)
- 字典嵌套列表(键为列名,值为该列数据组成的列表)
- 列表嵌套元组(每一项为
(column_name, value)的二元组) - 元组(只有一行数据时,形式为
(column_name, value))
columns: 可选的列名列表,用于指定列名。对于不提供列名的输入类型(如列表嵌套列表),此参数是必需的
常用方法:
add_data 方法
1 | |
- 作用: 向现有
wandb.Table对象中添加新的行数据 - 参数:
row_data: 要添加的新行数据,可以是以下类型之一:- 字典(键为列名,值为数据)
- 列表(按列顺序排列的数据)
- 元组(只有一行数据时,形式为
(column_name, value))
column_names: 可选的列名列表,用于指定列名。对于不提供列名的输入类型(如列表),此参数是必需的
add_rows 方法
1 | |
- 作用: 向现有
wandb.Table对象中批量添加多行数据 - 参数:
rows: 要添加的新行数据列表,每一项可以是以下类型之一:- 字典(键为列名,值为数据)
- 列表(按列顺序排列的数据)
- 元组(只有一行数据时,形式为
(column_name, value))
column_names: 可选的列名列表,用于指定列名。对于不提供列名的输入类型(如列表),此参数是必需的
Wand.Table作用:
- 数据可视化:
wandb.Table使得结构化的数据能够在wandb界面上以表格形式展示,便于直观地查看、分析和比较数据 - 数据记录: 将
wandb.Table记录到wandb运行中,可以将实验数据(如中间结果、评估指标、样本数据等)与模型训练过程关联起来,形成完整的实验记录,便于后续回顾、分析和复现 - 数据版本控制: 由于
wandb.Table是wandb运行的一部分,它会随运行一起版本化。用户可以轻松地对比不同运行之间的表格数据,观察数据的变化趋势或差异
wandb.watch 的使用
wandb.watch 用于在模型训练过程中自动记录和可视化神经网络模型的权重、激活、损失等关键信息
wandb.watch()侧重于模型内部状态的自动跟踪和可视化,如权重、激活、计算图和梯度wandb.log()专注于用户自定义的、实验相关的各种数据和指标的记录,包括但不限于模型性能、超参数、中间结果、日志信息等
基本用法
1 | |
- 参数:
model: 待监控的神经网络模型对象,可以是 PyTorch 的torch.nn.Module、TensorFlow Keras 的tensorflow.keras.Model或tf.keras.Model,以及其他支持的框架模型。log_freq: 可选的整数,指定记录指标的频率(以批次为单位)。默认情况下,仅在每个训练周期结束时记录一次。若设置为n,则每n个批次记录一次。log_graph: 可选的布尔值,指示是否记录和可视化模型的计算图。默认为False。如果设置为True,将为模型绘制计算图并上传到wandbwatch: 可选的参数,用于指定要监视的模型层或参数。可以是层名、层列表或字典。默认情况下,监视所有可训练参数gradients: 可选的布尔值,指示是否记录模型参数的梯度。默认为False。如果设置为True,将记录并可视化梯度
使用范例:
1 | |
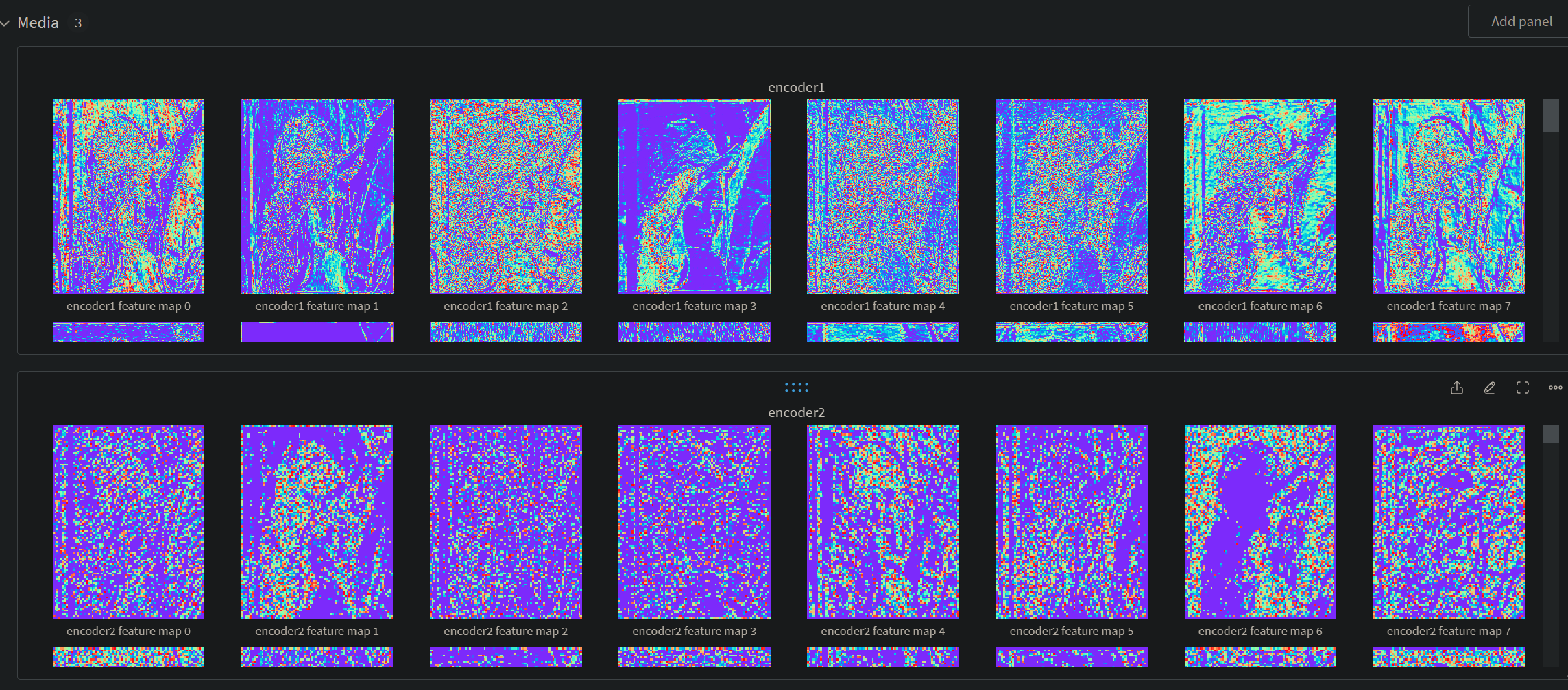
使用示例:使用wandb可视化vgg网络的特征图
1 | |
结果可视化图: