强化学习入门
什么是强化学习
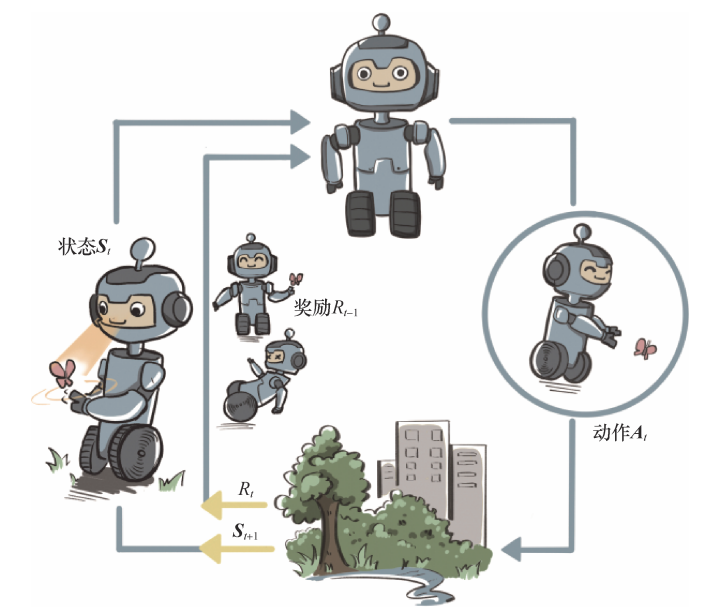
强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一 轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器(因此强化学习示意图很像RNN网络)。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。强化学习用智能体(agent)这个 概念来表示做决策的机器。相比于有监督学习中的“模型”,强化学习中的“智能体”强调机器 不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境,而不只是给出一些预测信号
强化学习的环境
环境这样一个自身演变的随机过程中加入一个外来的干扰因素,即智能体的动作, 那么环境的下一刻状态的概率分布将由当前状态和智能体的动作来共同决定,用最简单的数学公式(马尔可夫决策过程)表示则是:
每一轮状态转移都伴随着两方面 的随机性:一是智能体决策的动作的随机性,二是环境基于当前状态和智能体动作来采样下一刻状态的随机性
强化学习的数据:
有监督学习的任务建立在从给定的数据分布中采样得到的训练数据集上,通过优化在训练 数据集中设定的目标函数(如最小化预测误差)来找到模型的最优参数。这里,训练数据集背 后的数据分布是完全不变的。 在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布(占用度量)就不同
- 强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地 改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断 发生改变的
- 由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应 的奖励的期望,因此寻找最优策略对应着寻找最优占用度量
与其它学习的区别
对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(generalization error),用简要的公式可以概括为:
相比之下,强化学习任务的最终优化目标是最大化智能体策略在和动态环境交互过程中的价值。根据1.5节的分析,策略的价值可以等价转换成奖励函数在策略的占用度量上的期望,即:
(1)有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望
(2)二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变