Segformer(2)
Segformer 论文详解:
在SegFormer提出时,transformer已经开始在图像领域展露头角。在此之前,SETR最早将transformer结构引入到了语义分割任务中。SETR采用ViT作为backbone,并结合多个CNN decoder来放大特征分辨率。但是SETR具有两个局限性:
- 没有利用 multi-scale 特征
- 具有非常高的计算消耗
为了解决上述问题,pyramid vision Transformer (PVT) 被提出。PVT 具有金字塔结构,使得分割结果有进一步的提升。但是包括 PVT、Swin、Twins 等新兴方法都是在改进 encoder,但是忽略了 decoder 的改进。
与以前的方法相比,SegFormer 同时考虑了效率、准确性和鲁棒性,在三个数据集上取得了 SOTA 的效果,作者重新设计了 encoder 和 decoder,主要创新点包括:
- 利用多尺度特征图的同时,提出了一种新型的**无位置编码(position-encoding-free)**分层变压器编码器(position-encoding-free 带来了将模型变为 end-to-end 的好处,即不用将输入图片插值以符合固定大小的尺寸)
- 一种轻量级的 All-MLP(多层感知机) decoder设计,不仅结合了多尺度的特征信息,而且简单高效
网络设计:
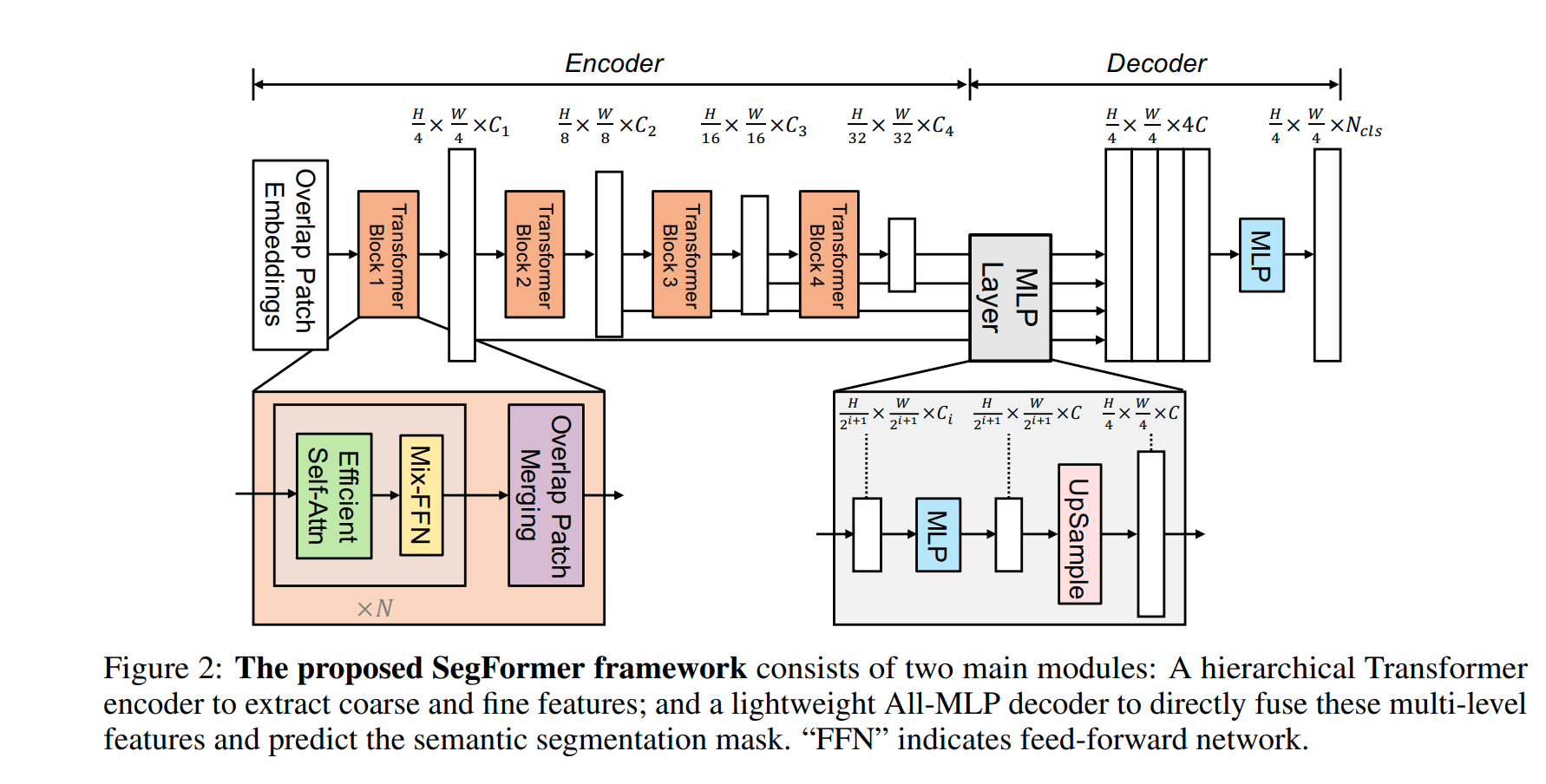
整个网络结构使用了经典的 encoder-decoder 设计,从整体结构看,将 encoder 各个阶段产生的不同尺度的特征图经过不同倍数的上采样后 concat 到一起去,这样网络极像经典的 FCN 网络(是否也能提出像 UNET 的 Segformer 呢?)。下面详解网络各个部分
Overlap Patch Embedding:
Encoder 部分由一连串的 Mix Transformer encoders (MiT) 模块构成,Transformer encoder layer 本质上是 Effecient Self-Attention+Norm+MixFFN 的组合。作者设计了从 MiT-B0 到 MiT-B5 多个 encoder,每个 encoder 结构相同但是大小不同。
与 ViT 不同,SegFormer 的 encoder 部分可以生成 multi-scale 的特征,提高了语义分割的性能。给定一个 的图像输入,会得到一系列不同分辨率大小的特征: ,其中 ,且
encoder 中大量采用了多头自注意力模块,也就是: 。其中还Q、K、V有同样的大小N×C,N=H×W。在此基础上,作者添加了如下的改进:通过reshape+Linear层的方式减小了特征的长度,也就是N。其中一个主要的参数就是R。公式如下:
这样做的主要目的就是为了减小计算复杂度。
为了获取multi-scale的多层特征,例如将特征 转化为 ,作者设计了一种overlapped的patch merge方法。之所以patch之间要存在overlap,主要是为了保证空间上的语意连贯性。这个模块可以简单的通过一个Kernel=7,Stride=4,Padding=3的卷积层实现。