segformer(1)
Segformer 代码结构分析
MMSegmentation 算法库的整体框架
MMSegmentation 是 OpenMMLab 开源的基于 PyTorch 实现的功能强大的语义分割工具箱,MMSegmentation 的主要特性如下:
- 丰富的语义分割模型: 已支持 11 种主干网络和 34 种算法,例如常用模型 FCN, PSPNet 和 DeepLabV3;Transformer 模型,Swin Transformer、Segmenter 和 SegFormer; Real-Time 实时分割模型, ICNet、BiSeNet 和 STDC 等;以及最近流行的网络 ConvNeXt 和 MAE。
- 大量开箱即用的模型权重:在 16 个常用的语义分割数据集上提供了 590 个训练好的模型。
- 统一的性能评估框架:优化和统一了训练和测试的流程,方便公平比较各个模型在特定任务上的表现。
MMSegmentation 目录结构
按照代码目录下的文件夹,MMSegmentation 代码库主要可以包含四个部分:
(1)./tools 包括了调用 MMSegmentation 作为训练和测试入口的 ./tools/train.py 和 ./tools/test.py,预训练模型和数据集准备的转换脚本,以及部署和可视化相关的脚本
详细介绍可见 Github 里的文档
(2) ./configs 包括了各个算法的配置文件、存放常用的数据集配置、基础模型以及训练策略的基配置文件 ./configs/_base_
(3)./mmseg 里面是 MMSegmentation 的算法库,包括核心组件、数据集处理、分割模型代码和面向用户的 API 接口
(4)./data 指的是存放数据集的路径,在原本的代码库中没有这个文件夹。用户只需指定正确的文件夹路径即可使用数据
下面是详细的 MMSegmentation 的算法库目录结构:
1 | |
MMSegmentation 的算法库有 3 个关键组件:
1../mmseg/apis/,用于训练和测试的接口
2../mmseg/models/,用于分割网络模型的具体实现
3../mmseg/datasets/,用于数据集处理
本文我们主要介绍算法模型相关的代码,因此涉及内容主要在 ./mmseg/models 里面
MMSegmentation 模型实现
MMSegmentation 中将语义分割模型定义为 segmentor, 一般包括 backbone、neck、head、loss4 个核心组件( 4 个组件不是每个算法都需要的),每个模块的功能如下:
MMSegmentation 里面的分割器框架可以分为 “Encoder Decoder” 结构和 “Cascade Encoder Decoder” 结构。 “Cascade Encoder Decoder” 的解码部分不是单独的解码头,而是级联式的 2 个或多个解码头,前一个解码头的输出作为后一个解码头的输入。
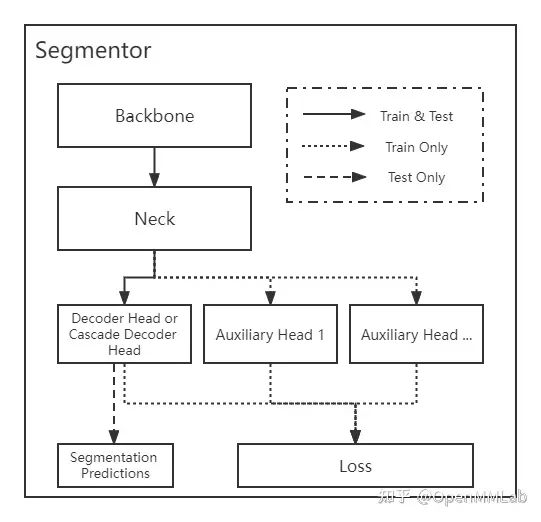
关于分割器 segmentor 的训练和测试的基本逻辑,以语义分割经典的 “Encoder Decoder” 结构为例:
1 | |
EncoderDecoder 里面分别定义了训练和测试的接口,训练时调用 forward_train() 返回一个 dict,包含各种 loss ,测试时则会调用 simple_test() 或者测试时数据增广的 aug_test(),只返回预测的分割结果。
训练时预测结果并计算 loss 的主要逻辑是在 _decode_head_forward_train 中实现:
1 | |
对于不同的 head,都可以抽象为:seg_logits = self.forward(inputs) ,即:网络前传得到预测的 logtis 值,然后再计算各个 head 的对应 loss:
1 | |
接下来,我们详细介绍分割器 segmentor 里4 个核心组件:backbone, neck,head,和 loss
Backbone
目前 MMSegmengtation 中已经集成了大部分主干网络,具体见文件 ./mmseg/models/backbones/、
**通常定义的"主干网络" 是指从上游任务(如 ImageNet )预训练,然后用于多个下游任务(如目标检测、实例分割、语义分割、姿态估计)中的网络,**而在 ./mmseg/models/backbones 里主干网络的定义有所不同,会把一些分割算法的网络结构也作为"主干网络",如 UNet、 FastSCNN、CGNet、ICNet、BiSeNetV1/V2、ERFNet、STDC
其中最常用的是 ResNet v1c 系列和 Vision Transformer 系列。如果你需要对骨架进行扩展,可以继承上述网络,然后通过注册器机制注册使用。一个典型用法为 ./configs/_base_/models/segmenter_vit-b16_mask.py 里面的:
1 | |
这里使用了 MMCV 中的模块注册机制,通过修改配置文件的 type ,可以使用在 MMSegmentation 已经实现的 backbone 模型。此外,还可以使用 MMClassification 里面的更多主干网络,如 ShuffleNet、EfficientNet 等,可根据 ./configs/convnext 里面 ConvNeXt 的实现方式,详细的方式可以参考: MMDet居然能用MMCls的Backbone?论配置文件的打开方式
backbone, neck,head,和 loss可以同理解读
如果把这东西看成一个库的话,会感觉这东西很难用,我想要自定义自己的模型的话,按照官方教程的说法,我需要在mmseg的底层代码中增加文件,创建一个新的文件 mmseg/models/backbones/mobilenet.py,这意味着我每次开发一个新模型都需要把整个mmseg文件包带上,而不能直接import底层的代码调用api,而且不能让我自己实例化模型,训练推理。必须使用它的train.py和test.py…
因此不应该把它视为一个库,而是一种代码模板,从这点来看,它的整个框架结构和可拓展性都是很好的,下面我们去看Segformer论文代码:
Segformer 官方论文代码
1 | |
可以看出来这个目录就是按照上面 mmseg 目录模板来进行的,每个部分的功能都可以参照上面 mmseg 目录注释部分。特别的这里有一个 local_configs 文件夹值得一提,它的存在是如下考虑的:
在实际使用中,用户可能会从configs文件夹中复制一个预定义的配置文件到local_configs文件夹,并根据需要进行修改。这样,用户可以保留原始的默认配置,同时在 local_configs 中进行个性化设置,而不会影响到原始的配置文件。local_configs 文件夹中的内容通常会覆盖 configs 文件夹中的对应配置。在许多深度学习框架和项目中,local_configs用于存放本地用户自定义的配置文件,这些文件允许用户根据自己的需求对模型的训练、推理或其他相关参数进行调整
当项目运行时,它会首先查找local_configs文件夹中的配置文件,如果找到了与项目运行相关的配置文件,那么这些文件中的设置会优先被使用。如果local_configs中没有相应的配置文件,或者用户想要使用默认的配置,那么项目会回退到configs文件夹中的默认配置
Segformer 程序复现:
先参照论文官方 github 仓库将代码copy下来,再安装依赖库:详情查看 requirements.txt 文档,mmcv 安装参照:open-mmlab/mmcv: OpenMMLab Computer Vision Foundation
程序修改:
根据上面对各个部分内容作用的分析,我们只需要修改 mmseg/datasets/corresponding_daaset.py tools locol_configs 这三个部分即可:
-
本文我采用原论文中ADE20K数据集进行训练,于是修改
mmseg/datasets/voc.py的步骤就可以省略了,不过也可以按照 ADE20K 数据集中objects.txt文档检查一下SegFormer-master/mmseg/datasets/ade.py中配置信息是否正确: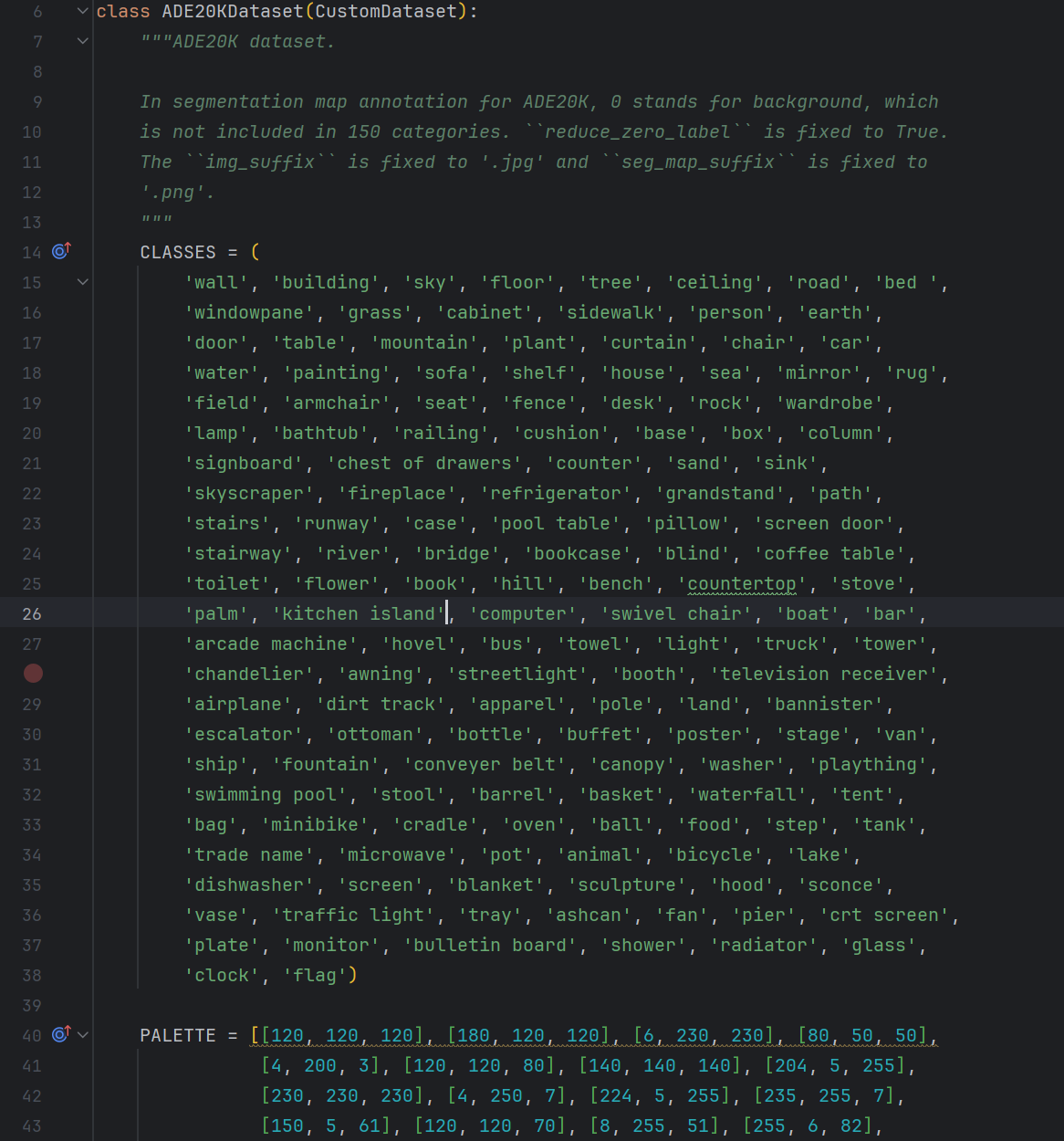
-
如果是单卡训练,需要修改在
mmseg/models/decode_heads/segformer_head.py中BatchNorm 方式 -
训练过程为了减少训练 epoch 的次数,采用了再预训练模型上继续训练的方式进行,