Pytorch-hook
Pytorch 的 hook 机制:
简介:
在PyTorch中,hook机制是一种强大的工具,它允许开发者在不修改模型原始结构的情况下,插入自定义函数来访问、记录或修改模型运行过程中的中间层输出(forward pass)和梯度(backward pass)。
具体来说,在torch.nn.Module及其包含的torch.Tensor对象上可以注册hook。通过调用.register_forward_hook()或.register_backward_hook()方法,可以在前向传播结束时或反向传播过程中执行特定的回调函数:
register_forward_hook(hook_function):当模块的前向传播完成时,会调用这个hook函数,它可以访问到该模块的输入和输出张量。register_backward_hook(hook_function):当模块接收到关于其输出的反向传播信号时,这个hook函数会被调用,它能够访问到模块输出的梯度以及输入的梯度。
Hook常用于以下场景:
- 可视化中间层特征图
- 监控和记录网络训练过程中的中间变量和梯度信息
- 对模型训练进行干预,如正则化或其他动态调整策略
- 实现元学习中的特殊计算需求
- 保存特定层的输出用于后续分析或微调
使用hook时需要注意释放资源,因为在每次迭代结束后,如果不手动保存这些中间结果,它们通常会被自动清理以节省内存。
PyTorch中的hook机制分为针对Tensor和Module(模型)的两种类型:
-
Tensor Hook:
torch.Tensor.register_hook(hook_function):这是一个作用在张量上的钩子函数,当该张量参与反向传播计算梯度时,会调用你注册的hook_function。这个函数接收一个参数,即该张量对应的梯度(grad),并且允许你在梯度计算完成后对其进行修改或观察,这种情况用得少,几乎只能用于修改反向传播的梯度值
-
Module Hooks:
-
torch.nn.Module.register_forward_hook(hook_function):当你需要监控或者修改模块执行前向传播过程时使用的钩子。在模块完成其forward()方法并生成输出后,hook_function会被调用,它接受三个参数:当前模块实例、模块接收到的输入以及模块计算出的输出。 -
torch.nn.Module.register_forward_pre_hook(hook_function):与register_forward_hook类似,但会在模块执行前向传播之前调用,此时输入尚未经过模块处理。 -
torch.nn.Module.register_backward_hook(hook_function):用于监控或修改模块在反向传播阶段的行为。当模块的输出梯度计算完毕后,hook_function会被调用,它接收四个参数:当前模块实例、输入梯度、输出梯度以及输出自身 -
如果希望对整个模型或特定层的所有输入和输出张量添加hooks,可以使用模块级别的hook,例如:
nn.Module.register_forward_hook(hook_function)nn.Module.register_backward_hook(hook_function)nn.Module.register_full_backward_hook(hook_function)
这些接口将允许在模型前向传播或反向传播的不同阶段添加自定义处理逻辑
-
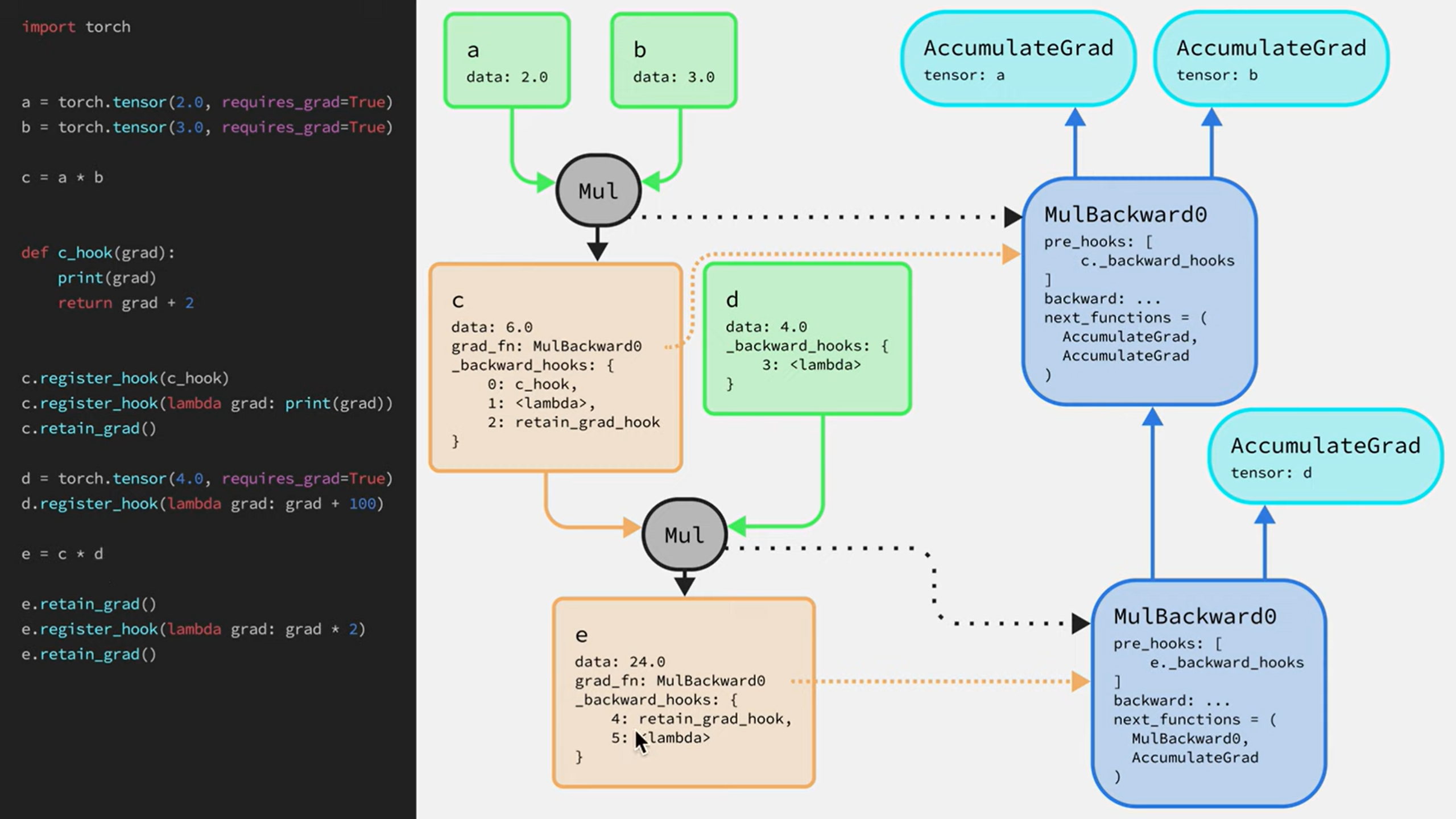
torch.Tensor.register_hook(hook_function) 用法
函数签名:
1 | |
参数说明:
hook: Callable[[Tensor], None]- 这是一个接受一个张量作为输入的可调用对象(通常为函数)
- 输入的张量是该操作在反向传播过程中产生的梯度,即当计算当前张量的上游梯度时,传递给
hook_function的是当前张量的梯度 hook函数没有返回值要求,其目的是为了让你能够监控或者修改这个张量的梯度- 对于
grad_fn=True的 Tensor,可以直接使用tensor.register_hook而不需要显式地先指向grad_fn属性
返回值:
- 无直接返回值,但会返回一个
torch.utils.hooks.RemovableHandle对象。通过该对象加上.remove()可以随时移除之前注册的钩子函数
注意:尽量不要在动态图的中间节点的hook函数中使用某个节点的 grad_fn 的 inplace 操作,比如 c=a+b 如果在 b 的 hook 中原地改变 b 的梯度,则 a 的梯度也会一样改变,因为 Pytorch 的底层机制,反向传播过程中发现 a 和 b 的梯度相同,就直接将 b 的梯度信息复制过去了!
1 | |
register_forward_hook(hook_function) 用法:
函数签名:
1 | |
参数:
hook:类型为Callable[[Module, Tensor, Tensor], None]的函数对象。这个函数需要接受三个参数,并且不返回任何值(因为返回了值也没什么用)module(类型:torch.nn.Module):触发钩子的模块实例。input(类型:Tuple[Tensor, ...]或单个Tensor):传递给模块执行前向传播操作时的输入数据,如果模块接收多个输入,则是一个包含所有输入张量的元组。output(类型:Tensor或Tuple[Tensor, ...]):模块执行完前向传播后生成的输出数据,根据模块的具体输出,可以是单个张量或多张量组成的元组
返回值:
- 无直接返回值,但会返回一个
torch.utils.hooks.RemovableHandle对象。通过该对象加上.remove()可以随时移除之前注册的钩子函数
1 | |
register_backward_hook() 用法
函数签名:
1 | |
参数说明:
- hook:类型为
Callable[[Module, Tensor, Tensor], None]的函数对象module(类型:torch.nn.Module):当前注册 hook 的模块实例grad_input(类型:tuple[Tensor, ...]):输入张量的梯度元组,每个元素对应模块正向传播接收到的一个输入张量的梯度grad_output(类型:tuple[Tensor, ...]):输出张量的梯度元组,每个元素对应模块正向传播生成的一个输出张量的梯度
返回值:
- 无直接返回值,但会返回一个
torch.utils.hooks.RemovableHandle对象。通过该对象加上.remove()可以随时移除之前注册的钩子函数
使用是同理的,通过使用 register_backward_hook(),开发者可以监视和/或修改模块在反向传播过程中的梯度信息,这对于调试、监控训练动态以及实现一些高级算法如梯度裁剪、正则化等非常有用
技巧:如果前向传播和反向传播的hook都有时,可以用一个类去封装hook使代码模块化
hook 应用实例:特征图提取特征可视化
1 | |
