dysample
Learning to sample
本文提出了一种新的极轻量级的高效采样算子(比前面所有的都更好,而且是在几乎各个任务中),主要是基于pytorch中grid_sample函数提出。FADE 和 SAPA 对高分辨率图像的需求在一定程度上限制了它们的应用领域,本文避开了动态卷积过程。dysample不需要原始高分辨率的feature map。
提出并优化dysample
设feature map ,采样集 ,一维的2表示 两个坐标,设上采样率为,朴素采样过程为:
其中,dysample的想法是引入一个输入和输出分别为 和 的线性层生成偏移量 ,每个采样点由”对应点 + 偏移量“的方式决定上采样图中每个点在采样前图中的坐标,使用F.grid_sample函数,将采样集修改为:
其中 为采样集, 为偏移量, 为采样对应点,由下面代码生成:
1 | |
至此就是 dysample 的雏形,下面我们一步步改进 dysample:
修改initial sampling position
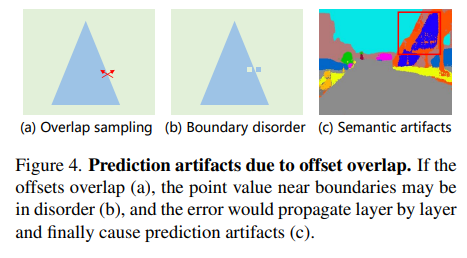
由于上采样前后 feature map 大小的差异,上采样后的特征图中有 个点对应采样前的同一个点,这 个点的初始坐标都相同,这样就导致了这些点不会区分开来,本质上就是 NN 采样加上了一个偏移量,于是作者将这些点的 initial sampling position 都加上了对应位置的偏离,对于 的情况,这些点的横纵坐标都分别加上了 ,过程如图所示:

考虑邻域信息:
在dysample中,如果使用 NN 插值上采样,在 时那么整个采样过程就等价于NN采样,没有考虑到邻域信息,我们将F.grid_sample 函数中的 mode 调为 bilinear,这样就能考虑邻域信息
限制偏移量范围:
偏移量过大会导致靠近边界处原有语义簇内的点采样到其它语义簇的情况,这样就会导致边界混乱,因此我们要限制偏移量的范围,使用:
的方式限定了边界范围,注意:如果使用tanh函数严格控制边界范围反而会导致效果变差,作者在文中给出的解释是太过于严格的边界会限制采样效果,因此在后面中提出了动态边界
减少参数量:
类似于在 nn.Conv2d 中的group操作,我们可以将通道分为 个 group,这些 group 内共享参数,作者在文中经验性地说明了 是一种较好的选择
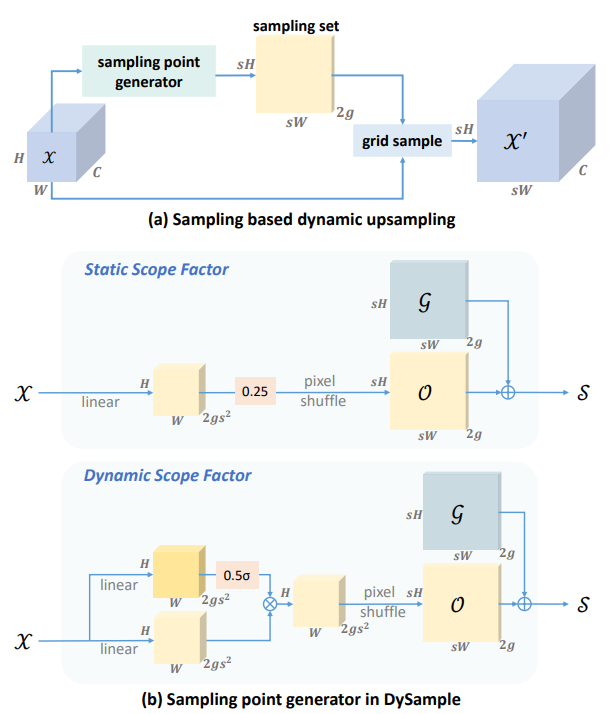
设置动态范围:
将偏移量的范围设置为 并以 0.25 为他们的平均值,则偏移量 可继续改写为:
使用PL继续减少参数量
在上面的讨论中,对于每个共享参数的group,我们先使用了CNN生成了大小为 大小的偏移量张量,再将其形状变换为 接得到了符合上采样后大小的偏移量,这个过程称为 “linear + pixelshuffle”(LP),为了减少训练的参数量,我们可以考虑减少通道维数,先进行形状变换操作,即将每个 group 大小的 feature map 形状变换为 ,再直接通过CNN生成符合上采样后大小形状的偏移量,这个过程称为 “pixelshuffle + linear” (PL),这样通过减少通道数的方式,我们减少了训练参数量
至此,dysample算子可分为以下四类:
- DySample: LP-style with the static scope factor
- DySample+: LP-style with the dynamic scope factor
- DySample-S: PL-style with the static scope factor
- DySample-S+: PL-style with dynamic scope factor
代码实现:
1 | |
代码经验:
F.interpolate对某一个通道为 c 进行的 feature map 进行分组插值时,将通道上组的维度移动到 batch 维度上,插值完成之后再从 batch 维度上移动回来即可- 对于模型中不变的Tensor,可以使用
register_buffer将 Tensor 保存到模型中 - 使用函数分开各部分的功能提高代码可读性