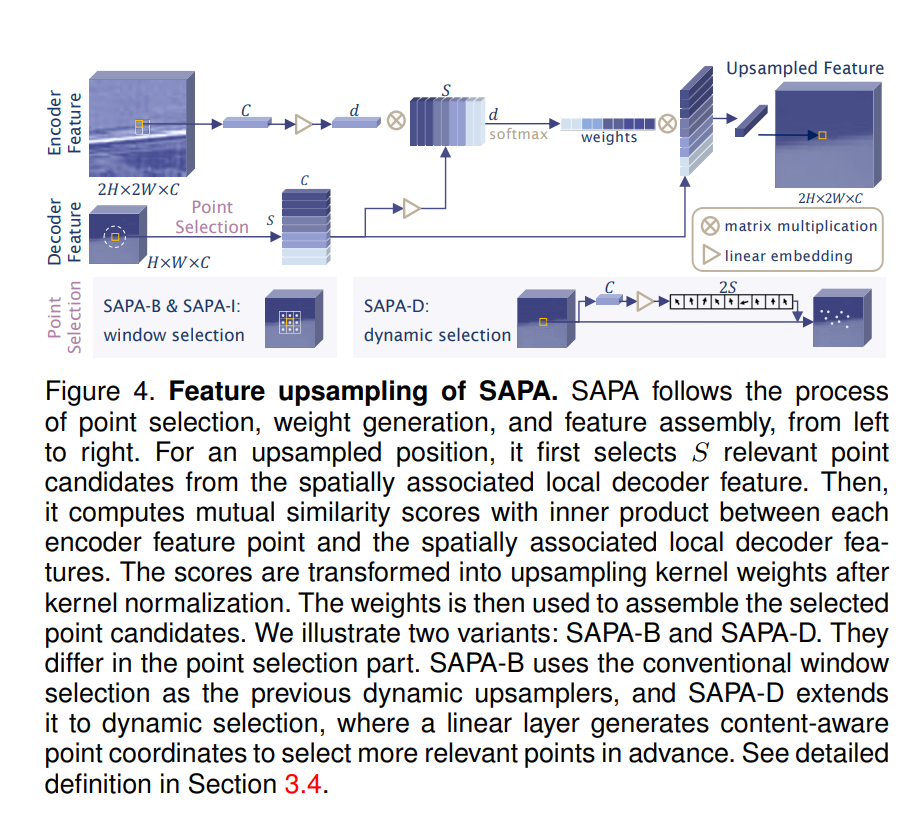
SAPA
SAPA: similarity-aware affiliation for feature upsampling
在低分辨率feature map中,如果对边界点进行上采样,可能出现的情况是:原本在低分辨率的一个点上采样之后所得的 个点并不属于一个semantic cluster。本篇文章旨在将语义信息的相似性引入上采样算子,利用不同点之间的联系(affiliation)判断采样点属于哪一个semantic cluster。它的原理是:计算待采样点与相邻某些点的相似性,用这些相似性,类似注意力机制去产生采样算子,由此对decoder feature进行上采样。SAPA不仅能够进行semantic smoothness(语义平滑)和boundary sharpness(突出边界),是一种非常有效的采样方式
SAPA-B:
设 decoder feature 大小为 ,待采样 feature map 大小为 (设采样率为2),设在 中每个点 ,则其对应 中的点 ,设我们要从邻域中 个点的信息采样,我们设些采样点的集合全体位置构成的集合设为 ,这些采样点沿通道的信息的集合为
再设对整个 feature map 的采样核为 ,大小为 ,由于要对 进行 normalize,我们将 normalize 定义为:
其中 是任意一个函数,通常选用 即为 softmax normalize 过程, 是相似度函数,定义有两种方式:
则对应点 的核 采样点的值可以表示为:
其中 是在 encoder feature 在 处的沿深度的向量,如果我们将 定义为点 在 decoder feature 中的方邻域,则根据采样值的相似度定义的不同,将 SAPA 划分为 SAPA-B (base) 和 SAPA-I (innner product),SAPA-B 的效果不仅能将同一个 semantic cluster 内的像素进行平滑,而且能将边界像素对比度调高(smooth regions and sharp boundaries)

SAPA-B的改进
SAPA-B 在大多数领域中都表现很好的表现,但在目标检测任务中,SAPA-B 的效果不如 CARAFE,作者在文中比较了 Semantic Segmentation 和 Object Detection 的区别,Sementic Segmentation 的每个像素点都会对最终性能评估和损失函数造成影响,而在 Object Detection 中只有一小部分区域对最终结果造成影响,因此它们可以划分为像素级的任务和非像素级的人物, CARAFE 可以修复 semantic information 且具有大的局部可分性( large local divisibility ),而如下图所示 SAPA-B 在低分辨率图像有正确的 semantic cluster 时,SAPA-B 会提升它的性能,但是如果存在着噪声的话 (例如下图中墙上的画的内容),SAPA-B 会引入噪声,因此如果在同一个 semantic cluster 内部像素信息不是平滑的时候,SAPA-B 的性能提升会很有限
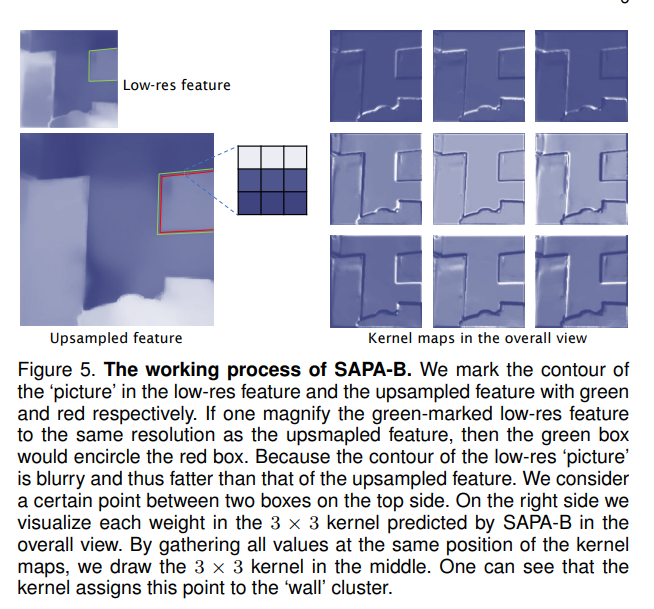
如下图所示,SAPA-B 在墙上挂画内部有噪声的时候,会引入一定的噪声
简而言之,作者在文章中给出解释:SAPA-B only extracts already existed knowledge from the encoder feature, but cannot learn new knowledge to enhance features. However, the dynamic convolution in CARAFE learns new representations based on the decoder feature and is able to mend the features. 在修复 feature 上,由于 CARAFE 的局部可分性强于 SAPA-B,在目标检测任务里面, SAPA-B 提供目标精确边界对性能指标的提升会不如 CARAFE 对目标内部一些关键区域信息的修补
SAPA-D的提出:
基于上面的推理,我们改进的思路是将 SAPA 改进为能够修复 feature,因此我们在噪声中去寻找潜在可能的适合的像素点进行采样。因此我们将 SAPA 先前统一的固定窗口形状变为一个可变的形状,即动态地去选择采样点。受 DCN(Deformable Convolutional Networks) 的启发,我们去生成对应于采样点的偏移量,则整个采样过程可以写为:
那么又引出一个问题:我们怎么生成采样点?作者在文章中引入了 DOF 的概念:
DOF ( Degree of Freedom ) 定义: 用于描述特征图的连续性和对比度的平衡,如果在 中 个值都由同一组参数生成,那么称 DOF 的值为1,反之若它们的值由 个值生成,那么 DOF 的值为
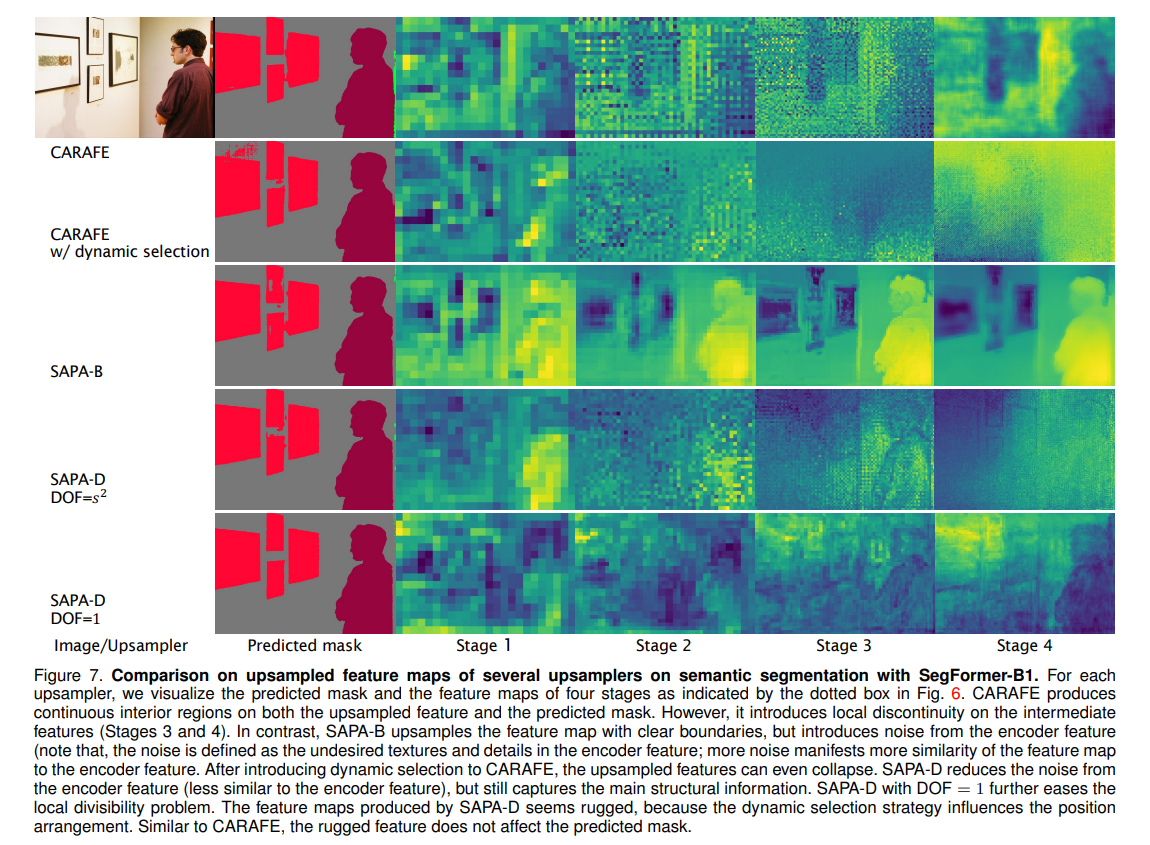
根据这个定义,CARAFE 的 DOF 值为 ,SAPA-B 的 DOF 值为1,Pixel-shuffle 的 DOF 值为 ,NN 的 DOF 值为1。DOF 的值越高,代表着更高的对比度和更低的连续性。效果如下图所示:

因此我们在语义分割任务中设置 DOF = 1,即 个采样点由同一组参数生成,在 instance-level tasks 中(例如目标检测)设置 DOF = ,在 DOF = 1 时,SAPA-D 表现出一个好的在连续性和对比度之间的折中
Group Upsampling:
用于采样的点的数量对计算速度有很大的影响,Group Upsampling 是一个 economic 的方式提升 SAPA 的性能,我们将 SAPA-B 中25个用于采样的点在SAPA-D中减为9个,并且使用 4 groups 进行采样。值得一提的是:Interestingly, the grouping operation is only useful for SAPA-D with dynamic selection, while even hurting the performance for SAPA-B and CARAFE.
高分辨率图像在采样中的作用:
高分辨率图像不仅能提供图像细节信息,还能提供 structural information to stabilize the feature map,如图 Fig.3 所示,在没有高分辨率图像指导的采样过程中,采样出来的高分辨率图像导致了采样的 feature 灾难性消失(值得一提的是,这样采样生成的特征图仍然能产生大约正确的结果,作者在文中猜测是提取了一些新的特殊的特征)。至此,我们可以将 SAPA 的采样过程表示为: