FADE
FADE: fusing the assets of decoder and encoder for task-agnostic upsampling
对于不同的稠密预测任务,有些任务注重于语义信息(semantic information),它们对图像位置信息敏感(region-sensitive)而有的任务(图像分割)注重于细节(detail-sensitive)。原有的上采样算子都是用于特定任务而不是通用型,本篇文章主要从encoder与decoder两方面解释了为什么CARAFE在semantic segmentation上优于IndexNet;IndexNet在image matting上优于CARAFE,并且提出了一种新的通用任务的采样算子FADE,FADE的有效性在于1.同时使用encoder与decoder,2.使用 semi-shift convolution 保证感受野大小,3.在产生上采样算子前使用一个gating mechanism模块,设计成与decoder无关以增强上采样算子的细节增强能力。
encoder&decoder
我们先提出一个假设:一个理想的上采样算子需要能够很好地保留semantic information的同时也需要补偿下采样过程中失去的细节信息;对于前者,semantic information已经嵌入在了decoder中,对于后者则存在于encoder中。我们进一步假设:正是因为encoder或者decoder中的信息使用不够充分或者有偏向性才导致采样算子有着task-dependent的特性。
下面通过采样算子的原理解释为什么现有的采样算子task-dependent:
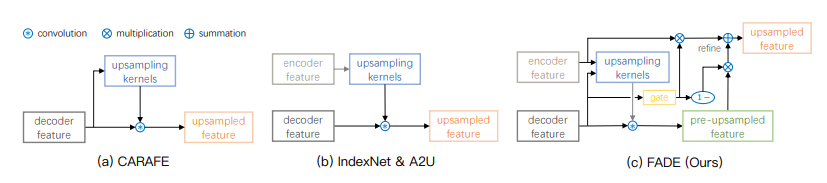
- CARAFE的上采样算子通过下采样之后的特征图产生,即由decoder feature产生,这样就充分利用了decoder feature的信息而丢失了下采样前的图像细节信息。
- IndexNet和A2U的上采样核通过下采样前的feature map产生,这样就充分利用了原feature map中的细节信息,而没有利用采样后的semantic information
- 于是我们提出了FADE:通过将encoder与decoder的信息融合生成采样算子
那么接下来的问题是如何将两个信息全部利用起来?
How to leverage both encoder and decoder features for task-agnostic upsampling?
一个朴素的想法是将encoder与decoder所提供的信息concatenate起来,通过卷积进行特征提取(卷积核实质上就是一个滤波器)生成上采样算子,但是主要的问题是:encoder与decoder所提供的feature map大小不一样(mismatched resolution),考虑如果对decoder使用参数为2的临近插值(2NN)进行信息补全,同时上采样率为2,当我们使用 大小的卷积核进行卷积时,本来是 大小的感受野就退化为只能感受到4个像素信息,同时实验也证明这种方法并不好。于是启发我们设计一个新的解决方案:semi-shift convolution。每当卷积窗口在 encoder feature 中移动两个像素点时,decoder feature 中的卷积窗口移动一个像素点,这一点和 CARAFE 的方式是相同的
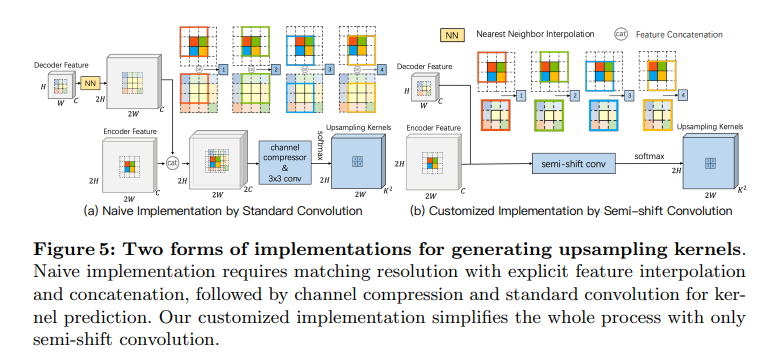
FADE 的设计
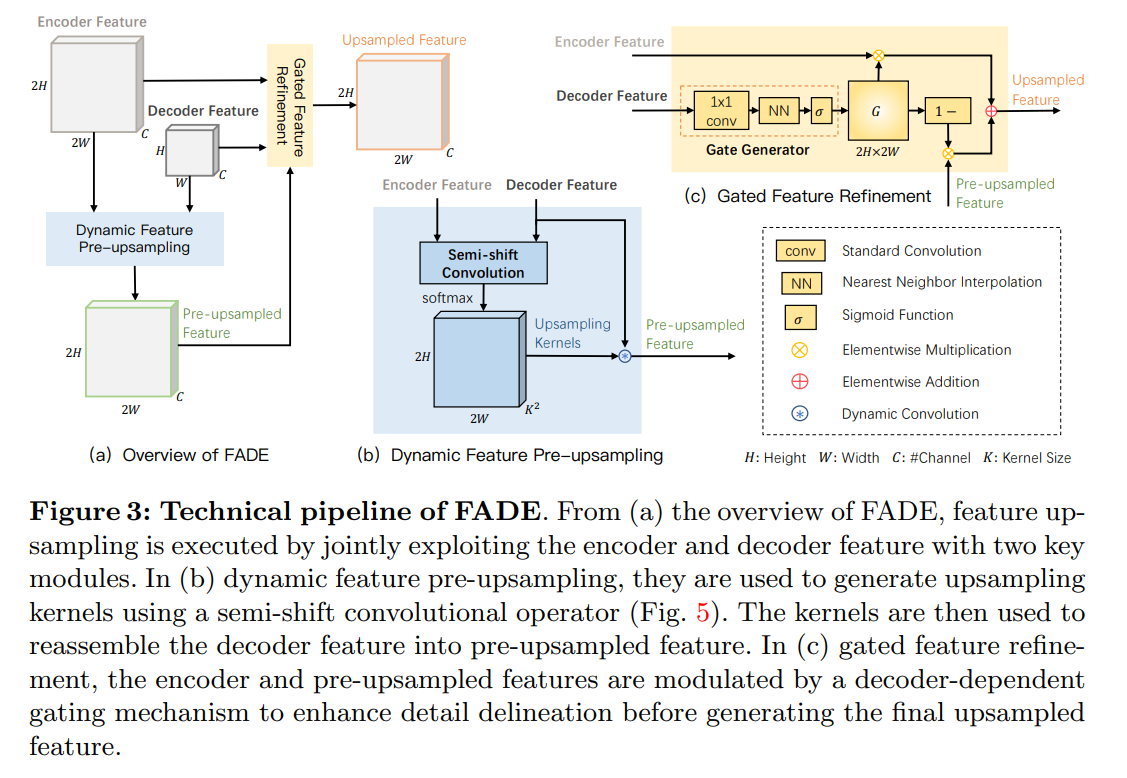
encoder feature 与 decoder feature 先经过一个半移位卷积生成 pre-upsampled feature,如果直接使用这份 feture map 会发现它恢复细节的能力不够,这时候引入 gated mechanism 进行微调,decoder feature 通过 的卷积进行通道压缩,再通过一次 NN插值上采样和 sigmoid 函数生成 ,这个 用于平衡 encoder feature 和 pre-upsampled 的权重,最终生成的上采样 feature map 由如下公式生成:
Gate是否有必要的讨论
在后续实验中,其实可以发现 Gate 其实并不是必须的,直接取 并不会对算子的性能产生很大的破坏,甚至有时候 的效果比动态生成 的效果好,为了简单期间,后续实现的代码我就不考虑 Gate 了
H2L与L2H
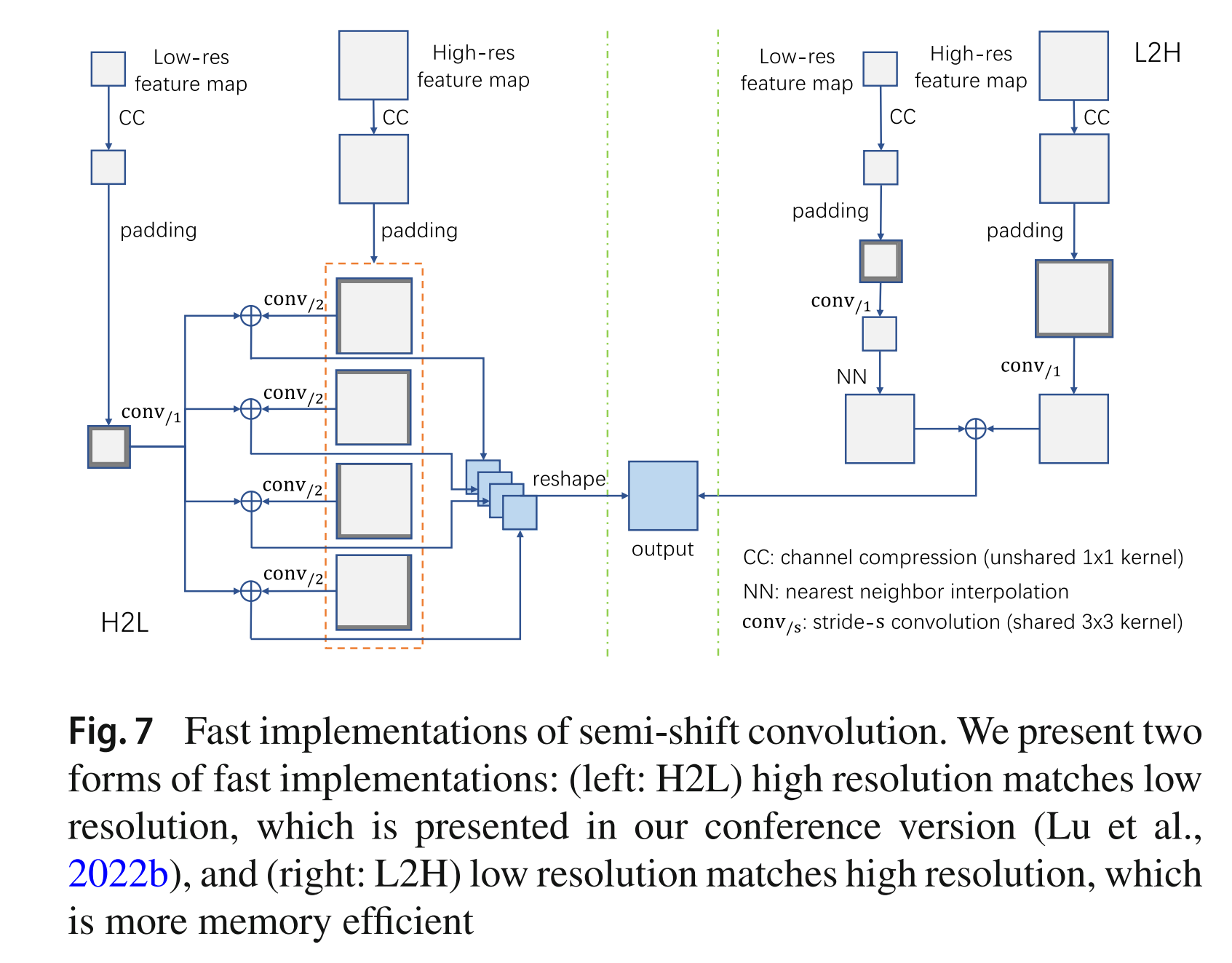
记 为步长为 的卷积,我们上面讨论的实现方式为对高分辨率的 encoder feature 使用步长为 2 的卷积去匹配 decoder feature 的大小,称这种实现方式为 H2L;反过来,我们也可以通过先对低分辨率 decoder feature 进行 NN 上采样,这样用低分辨率特征去匹配高分辨率特征称为 L2H
在算子效果上,H2L 方式的计算开销更大,但是效果更好;L2H 方式的计算开销更小,但是效果不如 H2L
代码实现:
为了简单期间,我只实现了 FADE 的 H2L 方式算子
1 | |
参考文献:
Fusing the assets of encoder and decoder in feature upsampling