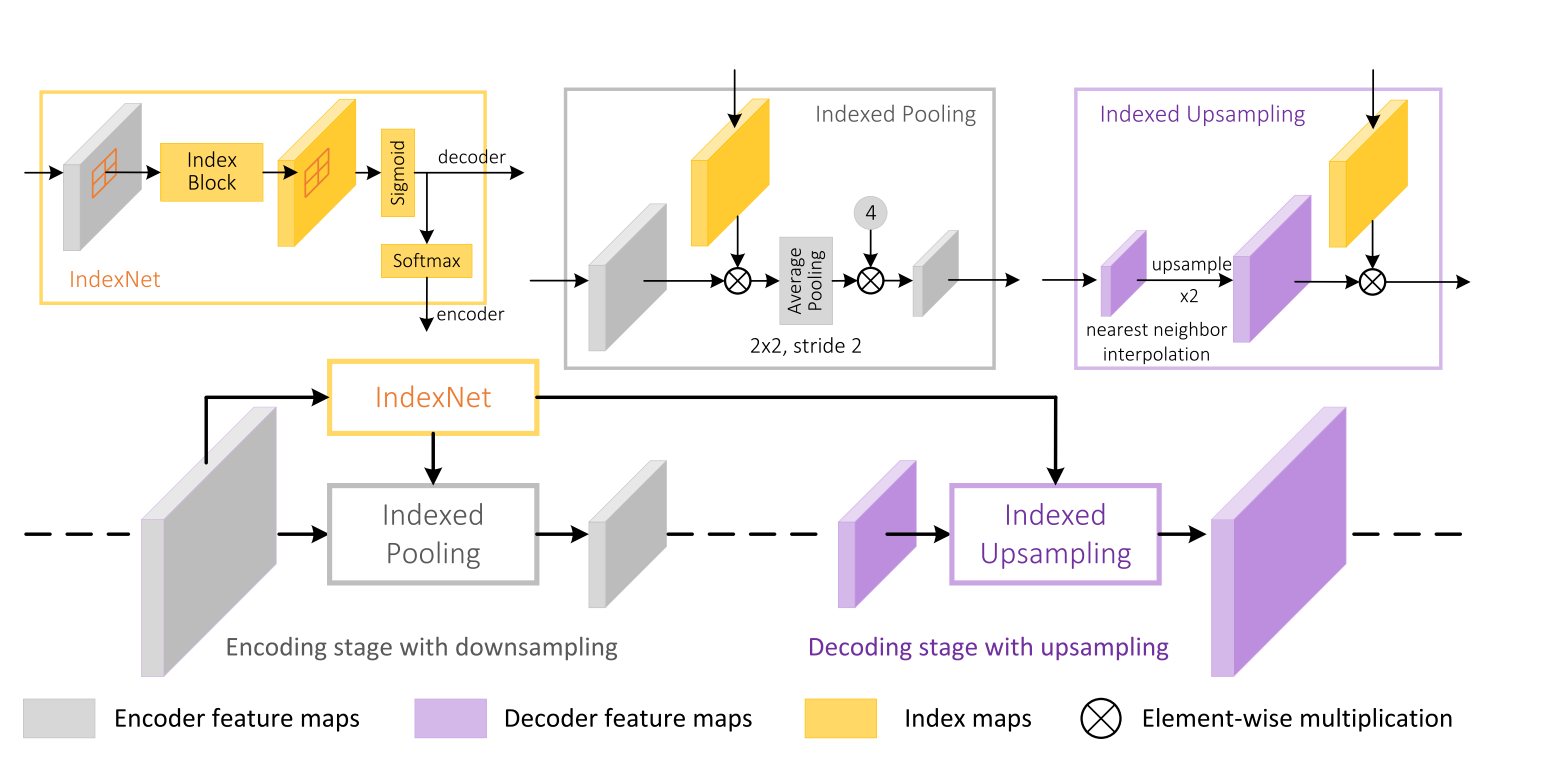
IndexNet
Indexed Network
卷积网络中上采样算子可以用文章中提出的索引函数(Index function)统一,说明了插值上采样与反池化操作等算子都是索引函数的特殊情况,由于在图像任务中,不同的部分图像对操作的要求不一样(比如图像边界需要提出边界信息,插值的方法就不如反最大值池化的操作;图像内部我们又需要邻域像素点的信息进行上采样的操作,这种情况下反最大值池化又不如插值方法),所以我们不能在图像中简单地用一个算子进行上采样,文章中提出了用Index function来引导采样的操作,其中Index function是一个可学习的函数(通过图像的信息学习—feature map),这样就可以根据图像的内容信息和位置信息进行不同的采样操作。
index的定义与理解
就是一个加权(对于图像内容的感知强度),用于进行矩阵乘法,表示对每个像素点的敏感程度。本文是由在 maxunpooling 的传递 index 的基础上提出的,所以本文作者才会称其为 indexNet ,在文章中的index都是"soft index",对 index 中每个元素: ,
对于每一个feature map ,IndexNet会产生两个Index function分别用于上采样与下采样:其实就是产生两个卷积核进行采样:
-
下采样操作 (indexed pooling):设是 通过 IndexNet 产生的索引(由下采样前的 feature map 产生,产生的 index map 大小与下采样前的 feature map 大小相同,因此在 操作之后要进行一次平均值池化满足下采样后的大小要求) 是下采样像素点的方形邻域(感受野),那么对 进行下采样,得到的结果为 ,对于每个区域 , 都会经过一个 softmax 保证图像强度连续性,从这里就可以看出最大值池化和平均值池化都是IndexNet的特例了。注:这样产生的 feature map 需要乘一个常数,在下采样率为2的时候整体 feature map 乘4去补偿平均值采样
-
上采样操作 (indexed upsampling):它是下采样操作的反算子,它先将上采样前低分辨率的 feature map 进行 NN 插值到和上采样后的大小,以匹配产生的 的大小(这一步就相对于CARAFE不同了,它考虑了spatial information,因为信息来自于encoder)即得上采样区域,即 , 的定义同上面的下采样。
文章中还根据训练的参数量将Index function分类:
- 每个层通道是否共享一个Index function将Index Networks分为HINS(holistic index networks) 和 DINS(depthwise index networks),对于原始大小的feature map,HINS会将feature map特征提取输出为大小的Index block,而DINS会将feature map特征提取输出为的Index block
- 再对DINS进行分类,由于输入feature map与输出Index block的通道数都是,因此我们考虑使用三维卷积还是二维卷积,即输出Index block的对通道的每一个切片是否考虑与feature map对通道的每一个切片一一对应,还是考虑feature map的全部层,于是将DINS分类为O2O DINS(one to one)和M2O DINS(many to one)
- 我们再对O2O DINS进行分类,考虑在上采样与下采样操作中,我们是否采用同一个参数的Index block,于是将O2O DINS进行分类为Modelwise O2O DINS和Stagewise O2O DINS
- 再对Stagewise O2O DINS进行分类,如果我们在不同阶段的采样过程中(不只是上下采样)都需要不同的Index block(即是否共享参数),我们再将Stagewise O2O DINS分类为Shared Stagewise O2O DINS和unshared Stagewise O2O DINS
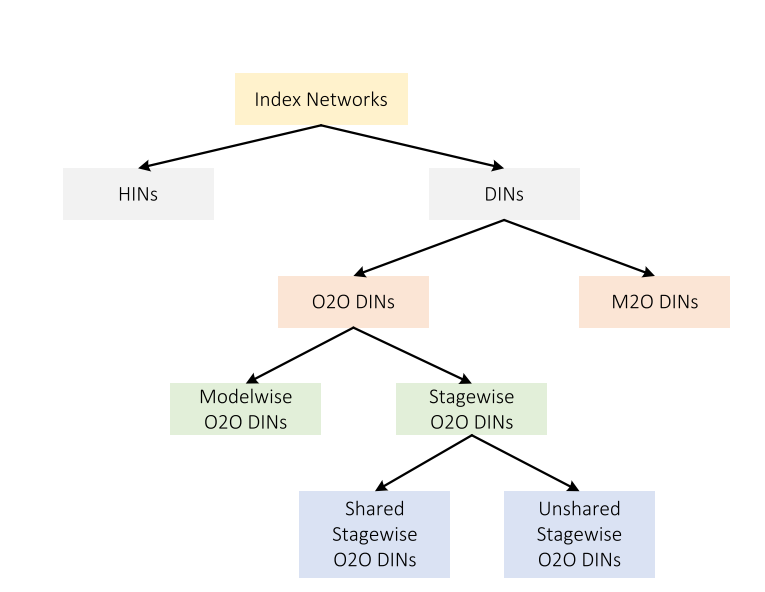
其中M2O的效果最好,但是同时参数量也最大;HINs比DINs更加灵活,对于网络的设计来说自由度更高。
IndexNet与CARAFE的比较
相同点:
-
它们都是基于内容生成的动态的,具有可学习参数的采样核。
-
CARAFE是IndexNet的特殊形式:
不同点
-
下采样时,IndexNet产生的Index function是基于前面高分辨率的feature map产生的,这样就不会丢失空间位置信息。
-
CARAFE基于下采样后的低分辨率图产生,因此具有丰富的语义信息
-
IndexNet的下采样与上采样方式是相互作用的,而CARAFE上下采样方式毫无关系,这一点可能可以引导以后的研究!
1 | |
代码经验:
- 对于一些不确定是否存在的层,将这些层设置为None就可以跳过他们,而不需要写两个
nn.Sequence - 对于重复性的层,合理使用列表生成式写法减少代码量