CARAFE上采样算子
CARAFE
在图像任务中,不同的部分图像对操作的要求不一样(比如图像边界需要提出边界信息,插值的方法就不如反最大值池化的操作;图像内部我们又需要邻域像素点的信息进行上采样的操作,这种情况下反最大值池化又不如插值方法),所以我们不能在图像中简单地用一个算子进行上采样,CARAFA是基于图像内容特征进行的采样方式。
上采样方式:
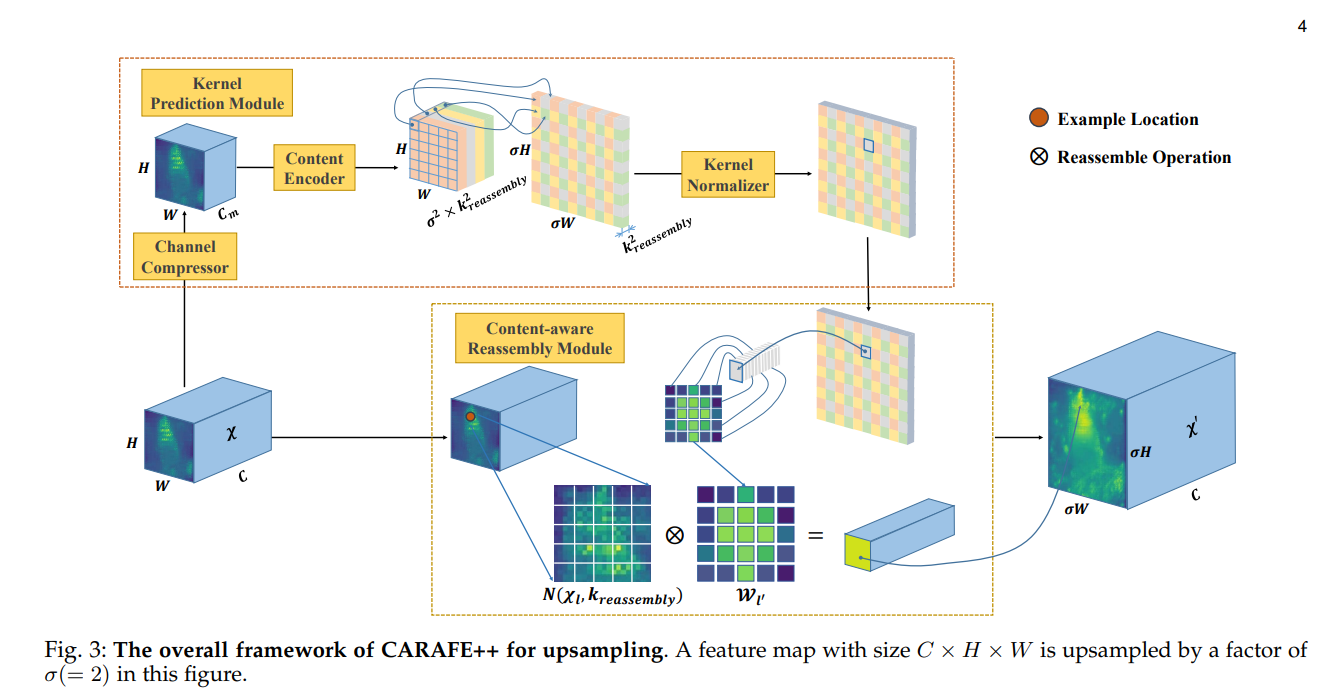
kernel Prediction Module
产生上采样算子的模块,Channel Compresser进行的一部是 的卷积操作,这部的目的是减少参数量,减少Computational cost。Content Encoder就是一个全卷积层,通过卷积感知邻域信息进行编码,注意卷积核的数量要符合 以满足后续的上采样操作,再将得到的feature map展平为 ,再经过一次正则化就产生了上采样算子
Content-aware Reassembly Module
论文中上采样操作为:对于原图像中任一个像素点 ,设 为以 为中心,边长为的方邻域,将原 feature map 先后进行通道压缩,内容编码,变换形状后再进行正则化操作得到上采样算子,在将原 feature map 的 和上采样算子的对应点沿通道进行相乘,运算如上图所示,这样得到的feature map的大小变为了原来的 倍,而通道数不变,这样就完成了上采样的操作。
下采样方式:
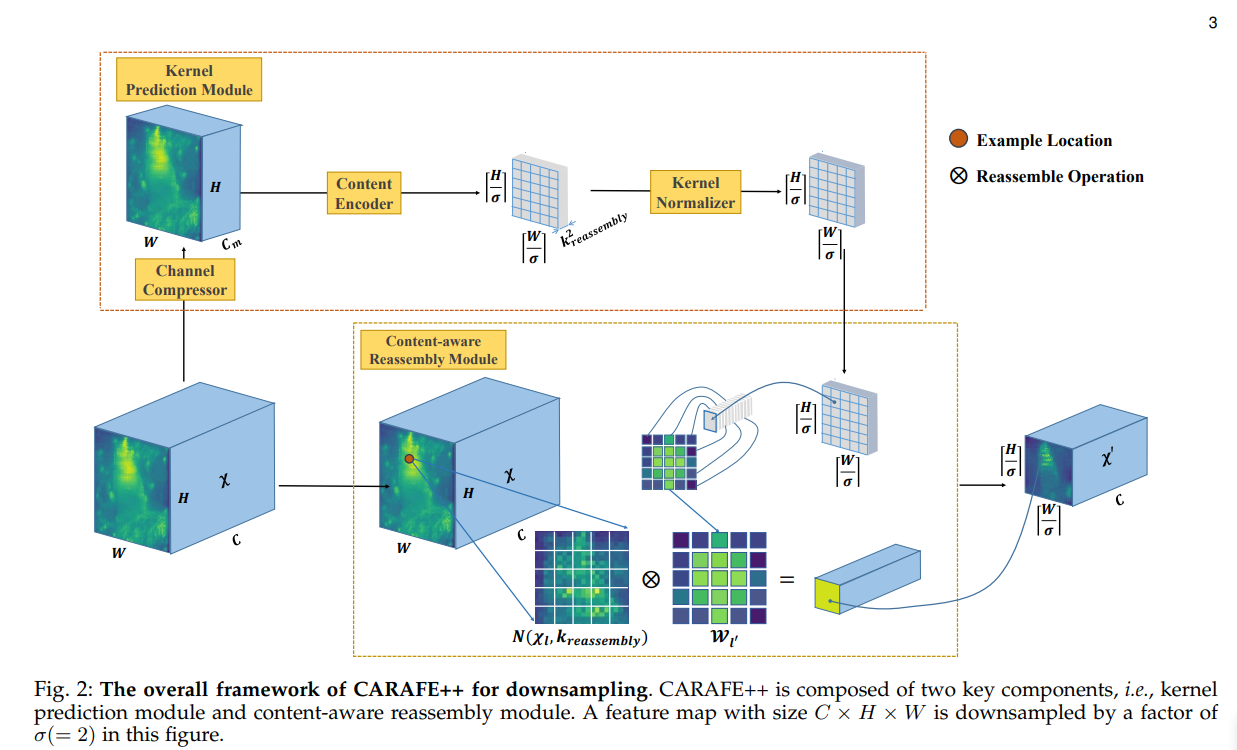
下采样的结构与上采样结构相似,只是在 Content_Encoder 部分使用了步幅为 的卷积,以此生成对应数量的采样核,因为大小已经满足需要,后续就不需要进行 pixeL-shuffle 操作了,接下来的过程与上采样相同
上下采样算子的协同使用:
论文中提到了:Experimental results show that adopting CARAFE++ in both upsampling and downsampling can consistently and substantially outperforms CARAFE on object detection, instance segmentation, semantic segmentation and image inpainting
这启发我们再后续的工作中探讨:上下采样算子的对应关系是否会影响采样的性能,我们能不能找出一般化的上下采样算子的对应准则?即去讨论上下采样算子的协同性,以此去指导上下采样过程
Question:
文章中:Note that these spatially adaptive weights are not learned as network parameters. Instead, they are predicted on-the-fly, using a lightweight fully-convolutional module with softmax activation.
not learned bur predicted 的意思是什么?
动态卷积核并不是在学习卷积核,如果学习的是卷积核,那么学习完成之后的卷积核依然是静态的。backward 学习的是:根据输入 feature map 而生成的生成卷积核的函数,这样卷积核就是动态生成的了。
代码实现:
1 | |
- CARAFE在上采样时,由于生成的卷积算子要求原图像中一个点对应 个点,这样会导致卷积核移位的速度不一样,不容易求和。所以使用
F.interpolate将原图像膨胀 倍 - 要求原 feature map 中每一个点的邻域时,使用
F.Unfold函数可以求出每个窗口 - 最后一步进行 einsum 操作时,将生成的四维卷积算子升为五维,多出来的一维专门用来求和,这样求和操作就变得很方便直观